 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighRes-net: Recursive Fusion for Multi-Frame Super-Resolution of Satellite Imagery
Feb 15, 2020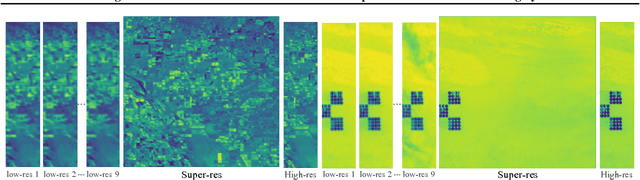
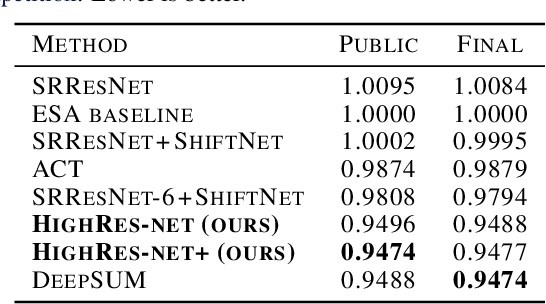
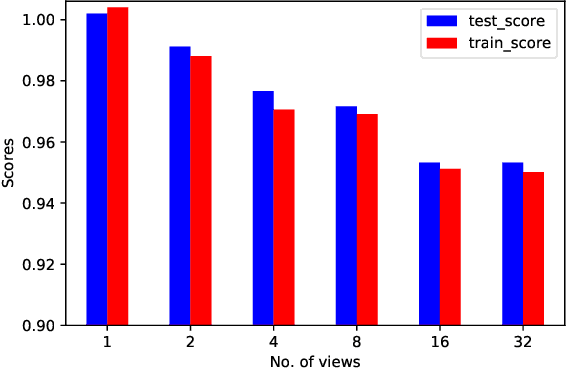
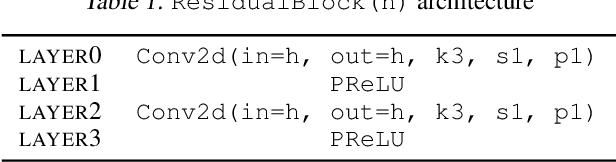
Generative deep learning has sparked a new wave of Super-Resolution (SR) algorithms that enhance single images with impressive aesthetic results, albeit with imaginary details. Multi-frame Super-Resolution (MFSR) offers a more grounded approach to the ill-posed problem, by conditioning on multiple low-resolution views. This is important for satellite monitoring of human impact on the planet -- from deforestation, to human rights violations -- that depend on reliable imagery. To this end, we present HighRes-net, the first deep learning approach to MFSR that learns its sub-tasks in an end-to-end fashion: (i) co-registration, (ii) fusion, (iii) up-sampling, and (iv) registration-at-the-loss. Co-registration of low-resolution views is learned implicitly through a reference-frame channel, with no explicit registration mechanism. We learn a global fusion operator that is applied recursively on an arbitrary number of low-resolution pairs. We introduce a registered loss, by learning to align the SR output to a ground-truth through ShiftNet. We show that by learning deep representations of multiple views, we can super-resolve low-resolution signals and enhance Earth Observation data at scale. Our approach recently topped the European Space Agency's MFSR competition on real-world satellite imagery.
Navigation Agents for the Visually Impaired: A Sidewalk Simulator and Experiments
Oct 29, 2019


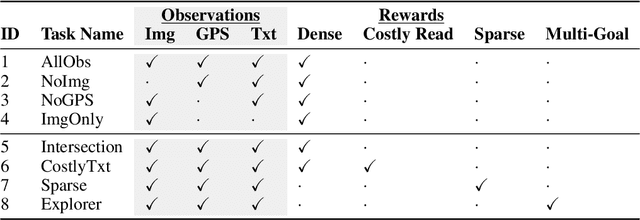
Millions of blind and visually-impaired (BVI) people navigate urban environments every day, using smartphones for high-level path-planning and white canes or guide dogs for local information. However, many BVI people still struggle to travel to new places. In our endeavor to create a navigation assistant for the BVI, we found that existing Reinforcement Learning (RL) environments were unsuitable for the task. This work introduces SEVN, a sidewalk simulation environment and a neural network-based approach to creating a navigation agent. SEVN contains panoramic images with labels for house numbers, doors, and street name signs, and formulations for several navigation tasks. We study the performance of an RL algorithm (PPO) in this setting. Our policy model fuses multi-modal observations in the form of variable resolution images, visible text, and simulated GPS data to navigate to a goal door. We hope that this dataset, simulator, and experimental results will provide a foundation for further research into the creation of agents that can assist members of the BVI community with outdoor navigation.