 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuarkMedSearch: A Long-Horizon Deep Search Agent for Exploring Medical Intelligence
Apr 14, 2026As agentic foundation models continue to evolve, how to further improve their performance in vertical domains has become an important challenge. To this end, building upon Tongyi DeepResearch, a powerful agentic foundation model, we focus on the Chinese medical deep search scenario and propose QuarkMedSearch, systematically exploring a full-pipeline approach spanning medical multi-hop data construction, training strategies, and evaluation benchmarks to further push and assess its performance upper bound in vertical domains. Specifically, for data synthesis, to address the scarcity of deep search training data in the medical domain, we combine a large-scale medical knowledge graph with real-time online exploration to construct long-horizon medical deep search training data; for post-training, we adopt a two-stage SFT and RL training strategy that progressively enhances the model's planning, tool invocation, and reflection capabilities required for deep search, while maintaining search efficiency; for evaluation, we collaborate with medical experts to construct the QuarkMedSearch Benchmark through rigorous manual verification. Experimental results demonstrate that QuarkMedSearch achieves state-of-the-art performance among open-source models of comparable scale on the QuarkMedSearch Benchmark, while also maintaining strong competitiveness on general benchmarks.
Spatio-Temporal Classification of Lung Ventilation Patterns using 3D EIT Images: A General Approach for Individualized Lung Function Evaluation
Jul 01, 2023


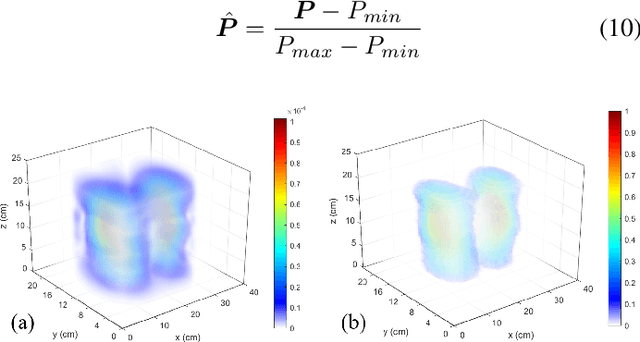
The Pulmonary Function Test (PFT) is an widely utilized and rigorous classification test for lung function evaluation, serving as a comprehensive tool for lung diagnosis. Meanwhile, Electrical Impedance Tomography (EIT) is a rapidly advancing clinical technique that visualizes conductivity distribution induced by ventilation. EIT provides additional spatial and temporal information on lung ventilation beyond traditional PFT. However, relying solely on conventional isolated interpretations of PFT results and EIT images overlooks the continuous dynamic aspects of lung ventilation. This study aims to classify lung ventilation patterns by extracting spatial and temporal features from the 3D EIT image series. The study uses a Variational Autoencoder network with a MultiRes block to compress the spatial distribution in a 3D image into a one-dimensional vector. These vectors are then concatenated to create a feature map for the exhibition of temporal features. A simple convolutional neural network is used for classification. Data collected from 137 subjects were finally used for training. The model is validated by ten-fold and leave-one-out cross-validation first. The accuracy and sensitivity of normal ventilation mode are 0.95 and 1.00, and the f1-score is 0.94. Furthermore, we check the reliability and feasibility of the proposed pipeline by testing it on newly recruited nine subjects. Our results show that the pipeline correctly predicts the ventilation mode of 8 out of 9 subjects. The study demonstrates the potential of using image series for lung ventilation mode classification, providing a feasible method for patient prescreening and presenting an alternative form of PFT.
Neural Born Iteration Method For Solving Inverse Scattering Problems: 2D Cases
Dec 18, 2021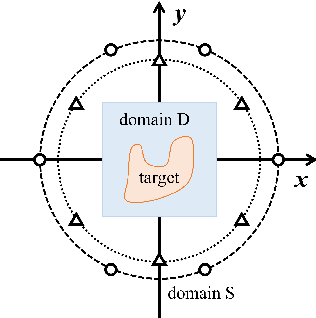

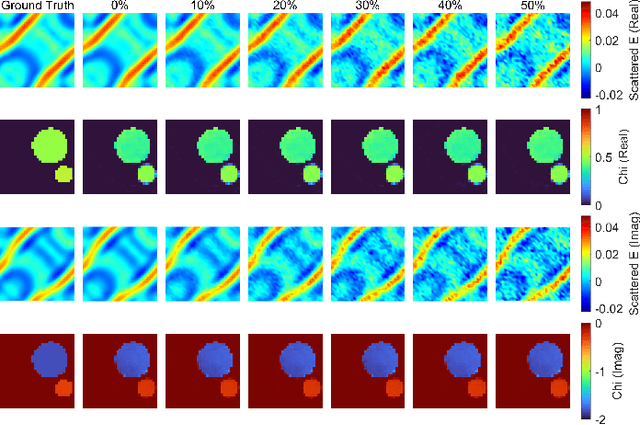
In this paper, we propose the neural Born iteration method (NeuralBIM) for solving 2D inverse scattering problems (ISPs) by drawing on the scheme of physics-informed supervised residual learning (PhiSRL) to emulate the computing process of the traditional Born iteration method (TBIM). NeuralBIM employs independent convolutional neural networks (CNNs) to learn the alternate update rules of two different candidate solutions with their corresponding residuals. Two different schemes of NeuralBIMs are presented in this paper including supervised and unsupervised learning schemes. With the data set generated by method of moments (MoM), supervised NeuralBIMs are trained with the knowledge of total fields and contrasts. Unsupervised NeuralBIM is guided by the physics-embedded loss functions founding on the governing equations of ISPs, which results in no requirements of total fields and contrasts for training. Representative numerical results further validate the effectiveness and competitiveness of both supervised and unsupervised NeuralBIMs.
A Graph-Based Neural Model for End-to-End Frame Semantic Parsing
Sep 25, 2021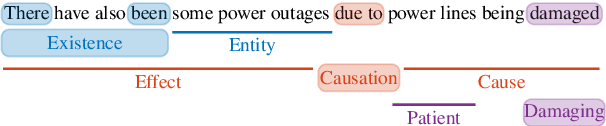
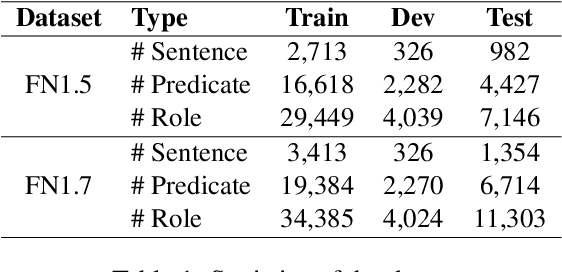
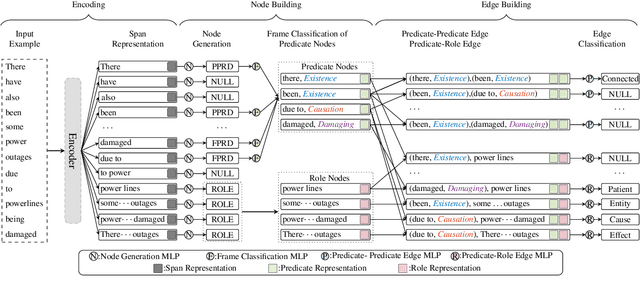
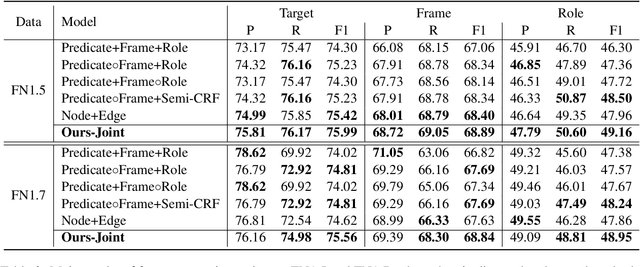
Frame semantic parsing is a semantic analysis task based on FrameNet which has received great attention recently. The task usually involves three subtasks sequentially: (1) target identification, (2) frame classification and (3) semantic role labeling. The three subtasks are closely related while previous studies model them individually, which ignores their intern connections and meanwhile induces error propagation problem. In this work, we propose an end-to-end neural model to tackle the task jointly. Concretely, we exploit a graph-based method, regarding frame semantic parsing as a graph construction problem. All predicates and roles are treated as graph nodes, and their relations are taken as graph edges. Experiment results on two benchmark datasets of frame semantic parsing show that our method is highly competitive, resulting in better performance than pipeline models.
A Span-Based Model for Joint Overlapped and Discontinuous Named Entity Recognition
Jun 28, 2021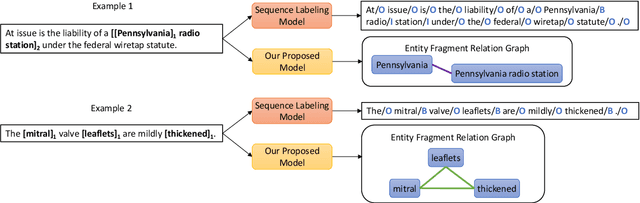

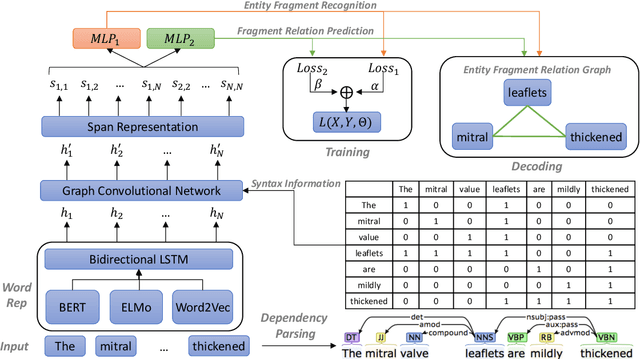
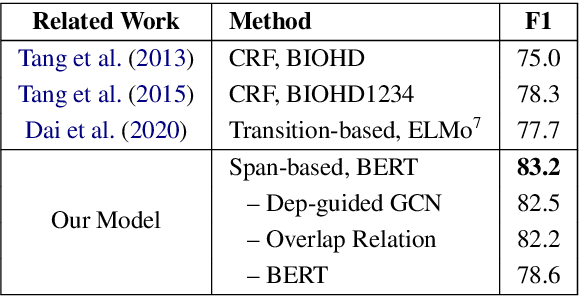
Research on overlapped and discontinuous named entity recognition (NER) has received increasing attention. The majority of previous work focuses on either overlapped or discontinuous entities. In this paper, we propose a novel span-based model that can recognize both overlapped and discontinuous entities jointly. The model includes two major steps. First, entity fragments are recognized by traversing over all possible text spans, thus, overlapped entities can be recognized. Second, we perform relation classification to judge whether a given pair of entity fragments to be overlapping or succession. In this way, we can recognize not only discontinuous entities, and meanwhile doubly check the overlapped entities. As a whole, our model can be regarded as a relation extraction paradigm essentially. Experimental results on multiple benchmark datasets (i.e., CLEF, GENIA and ACE05) show that our model is highly competitive for overlapped and discontinuous NER.
HighRes-net: Recursive Fusion for Multi-Frame Super-Resolution of Satellite Imagery
Feb 15, 2020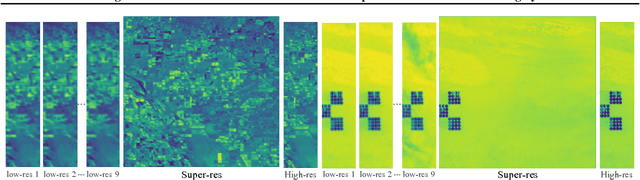
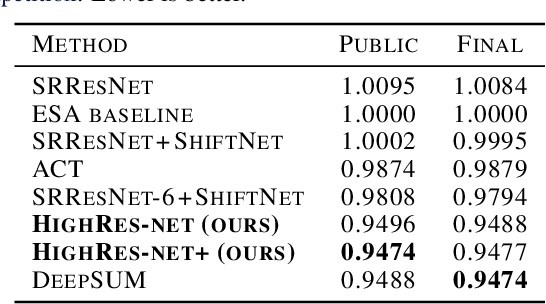
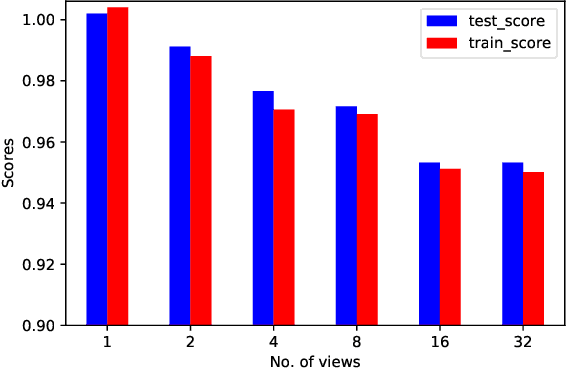
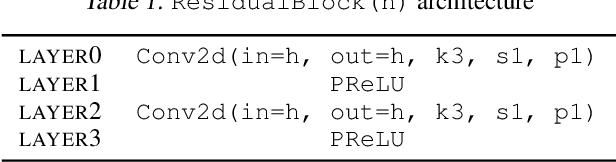
Generative deep learning has sparked a new wave of Super-Resolution (SR) algorithms that enhance single images with impressive aesthetic results, albeit with imaginary details. Multi-frame Super-Resolution (MFSR) offers a more grounded approach to the ill-posed problem, by conditioning on multiple low-resolution views. This is important for satellite monitoring of human impact on the planet -- from deforestation, to human rights violations -- that depend on reliable imagery. To this end, we present HighRes-net, the first deep learning approach to MFSR that learns its sub-tasks in an end-to-end fashion: (i) co-registration, (ii) fusion, (iii) up-sampling, and (iv) registration-at-the-loss. Co-registration of low-resolution views is learned implicitly through a reference-frame channel, with no explicit registration mechanism. We learn a global fusion operator that is applied recursively on an arbitrary number of low-resolution pairs. We introduce a registered loss, by learning to align the SR output to a ground-truth through ShiftNet. We show that by learning deep representations of multiple views, we can super-resolve low-resolution signals and enhance Earth Observation data at scale. Our approach recently topped the European Space Agency's MFSR competition on real-world satellite imagery.
Domain Representation for Knowledge Graph Embedding
Apr 09, 2019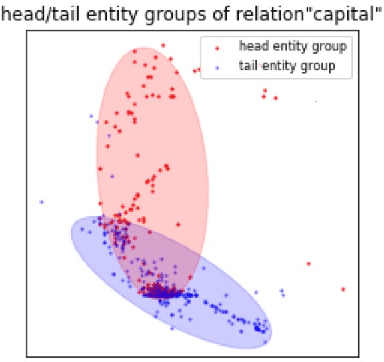

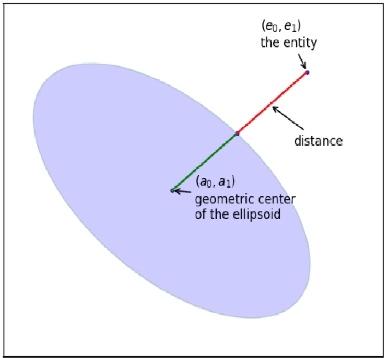

Embedding entities and relations into a continuous multi-dimensional vector space have become the dominant method for knowledge graph embedding in representation learning. However, most existing models ignore to represent hierarchical knowledge, such as the similarities and dissimilarities of entities in one domain. We proposed to learn a Domain Representations over existing knowledge graph embedding models, such that entities that have similar attributes are organized into the same domain. Such hierarchical knowledge of domains can give further evidence in link prediction. Experimental results show that domain embeddings give a significant improvement over the most recent state-of-art baseline knowledge graph embedding models.