 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynheart Capacity: A Theory-Driven Physiological Representation of Cognitive Capacity Dynamics from Wearable Signals
May 23, 2026Human cognitive performance is constrained by limited mental resources, yet continuous computational estimation of cognitive capacity dynamics remains an open challenge. We propose a theory-driven multimodal learning framework that models capacity-related cognitive state as a two-dimensional physiological representation defined by voluntary resource allocation (mental effort) and overload-related strain (stress). The proposed architecture combines dual-stream encoding of cardiac (IBI/HRV) and electrodermal (EDA) signals with late fusion and task-specific output heads that independently estimate probabilistic effort and stress states. Evaluation on the SWELL-KW dataset using strict leave-one-subject-out cross-validation demonstrates cross-individual generalization (stress: 70.0\% balanced accuracy; effort: 72.2\%), with significant gains from multimodal integration and theory-guided supervision. Rather than collapsing physiological dynamics into a single workload label, the proposed effort--stress state-space enables structured differentiation between distinct cognitive regimes, including productive engagement and overload-related strain. Predicted state trajectories exhibit significant demand-sensitive shifts under controlled workload manipulations, with effort and stress responding differentially across interruption and time-pressure conditions. These results suggest that physiologically grounded multidimensional state representations may provide a foundation for adaptive systems capable of continuous capacity-aware monitoring and human-centered interaction.
Synheart Emotion: Privacy-Preserving On-Device Emotion Recognition from Biosignals
Nov 09, 2025



Human-computer interaction increasingly demands systems that recognize not only explicit user inputs but also implicit emotional states. While substantial progress has been made in affective computing, most emotion recognition systems rely on cloud-based inference, introducing privacy vulnerabilities and latency constraints unsuitable for real-time applications. This work presents a comprehensive evaluation of machine learning architectures for on-device emotion recognition from wrist-based photoplethysmography (PPG), systematically comparing different models spanning classical ensemble methods, deep neural networks, and transformers on the WESAD stress detection dataset. Results demonstrate that classical ensemble methods substantially outperform deep learning on small physiological datasets, with ExtraTrees achieving F1 = 0.826 on combined features and F1 = 0.623 on wrist-only features, compared to transformers achieving only F1 = 0.509-0.577. We deploy the wrist-only ExtraTrees model optimized via ONNX conversion, achieving a 4.08 MB footprint, 0.05 ms inference latency, and 152x speedup over the original implementation. Furthermore, ONNX optimization yields a 30.5% average storage reduction and 40.1x inference speedup, highlighting the feasibility of privacy-preserving on-device emotion recognition for real-world wearables.
HighRes-net: Recursive Fusion for Multi-Frame Super-Resolution of Satellite Imagery
Feb 15, 2020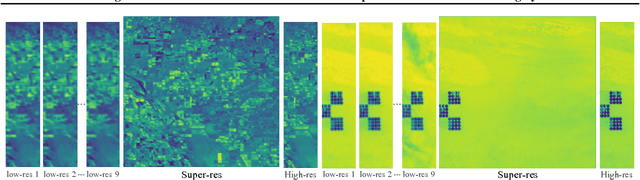
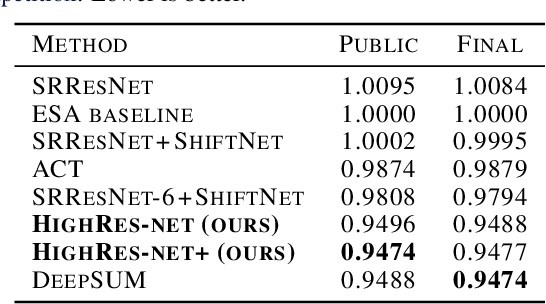
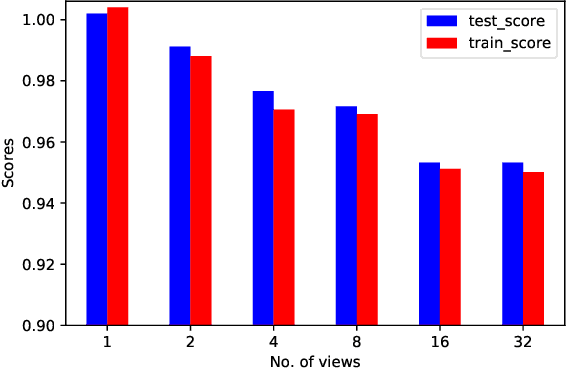
Generative deep learning has sparked a new wave of Super-Resolution (SR) algorithms that enhance single images with impressive aesthetic results, albeit with imaginary details. Multi-frame Super-Resolution (MFSR) offers a more grounded approach to the ill-posed problem, by conditioning on multiple low-resolution views. This is important for satellite monitoring of human impact on the planet -- from deforestation, to human rights violations -- that depend on reliable imagery. To this end, we present HighRes-net, the first deep learning approach to MFSR that learns its sub-tasks in an end-to-end fashion: (i) co-registration, (ii) fusion, (iii) up-sampling, and (iv) registration-at-the-loss. Co-registration of low-resolution views is learned implicitly through a reference-frame channel, with no explicit registration mechanism. We learn a global fusion operator that is applied recursively on an arbitrary number of low-resolution pairs. We introduce a registered loss, by learning to align the SR output to a ground-truth through ShiftNet. We show that by learning deep representations of multiple views, we can super-resolve low-resolution signals and enhance Earth Observation data at scale. Our approach recently topped the European Space Agency's MFSR competition on real-world satellite imagery.
Nanoscale Microscopy Images Colourisation Using Neural Networks
Dec 17, 2019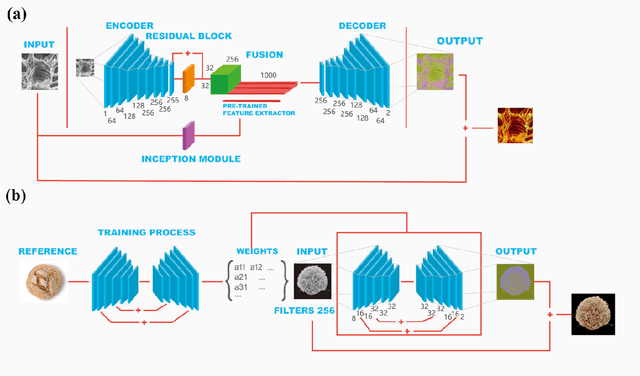
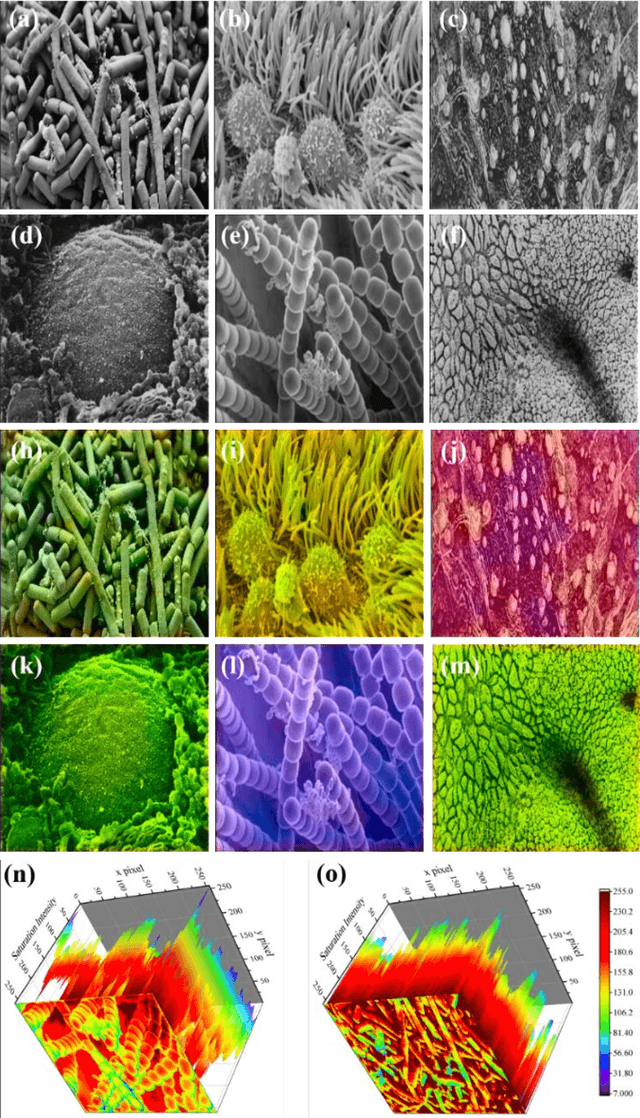


Microscopy images are powerful tools and widely used in the majority of research areas, such as biology, chemistry, physics and materials fields by various microscopies (Scanning Electron Microscope (SEM), Atomic Force Microscope (AFM) and the optical microscope, et al.). However, most of the microscopy images are colourless due to the unique imaging mechanism. Though investigating on some popular solutions proposed recently about colourizing microscopy images, we notice the process of those methods are usually tedious, complicated, and time-consuming. In this paper, inspired by the achievement of machine learning algorithms on different science fields, we introduce two artificial neural networks for grey microscopy image colourization: An end-to-end convolutional neural network (CNN) with a pre-trained model for feature extraction and a pixel-to-pixel Neural Style Transfer convolutional neural network (NST-CNN) which can colourize grey microscopy images with semantic information learned from a user-provided colour image at inference time. Our results show that our algorithm not only could able to colour the microscopy images under complex circumstances precisely but also make the colour naturally according to a massive number of nature images training with proper hue and saturation.