 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpportunities and Risks of LLMs for Scalable Deliberation with Polis
Jun 20, 2023



Polis is a platform that leverages machine intelligence to scale up deliberative processes. In this paper, we explore the opportunities and risks associated with applying Large Language Models (LLMs) towards challenges with facilitating, moderating and summarizing the results of Polis engagements. In particular, we demonstrate with pilot experiments using Anthropic's Claude that LLMs can indeed augment human intelligence to help more efficiently run Polis conversations. In particular, we find that summarization capabilities enable categorically new methods with immense promise to empower the public in collective meaning-making exercises. And notably, LLM context limitations have a significant impact on insight and quality of these results. However, these opportunities come with risks. We discuss some of these risks, as well as principles and techniques for characterizing and mitigating them, and the implications for other deliberative or political systems that may employ LLMs. Finally, we conclude with several open future research directions for augmenting tools like Polis with LLMs.
Open High-Resolution Satellite Imagery: The WorldStrat Dataset -- With Application to Super-Resolution
Jul 13, 2022

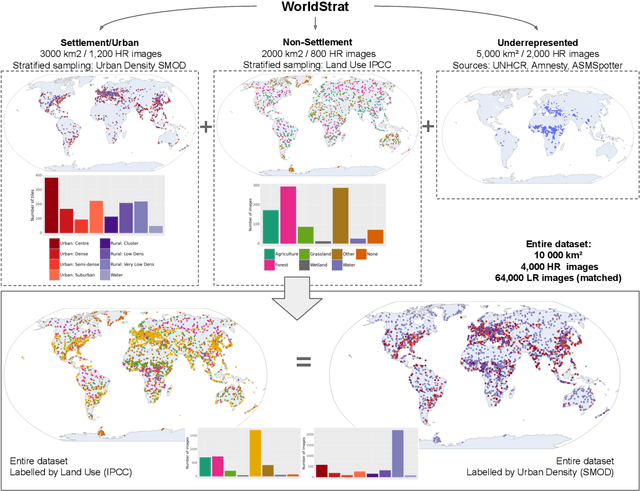
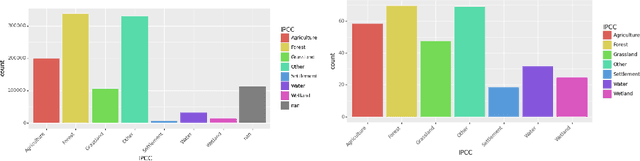
Analyzing the planet at scale with satellite imagery and machine learning is a dream that has been constantly hindered by the cost of difficult-to-access highly-representative high-resolution imagery. To remediate this, we introduce here the WorldStrat dataset. The largest and most varied such publicly available dataset, at Airbus SPOT 6/7 satellites' high resolution of up to 1.5 m/pixel, empowered by European Space Agency's Phi-Lab as part of the ESA-funded QueryPlanet project, we curate nearly 10,000 sqkm of unique locations to ensure stratified representation of all types of land-use across the world: from agriculture to ice caps, from forests to multiple urbanization densities. We also enrich those with locations typically under-represented in ML datasets: sites of humanitarian interest, illegal mining sites, and settlements of persons at risk. We temporally-match each high-resolution image with multiple low-resolution images from the freely accessible lower-resolution Sentinel-2 satellites at 10 m/pixel. We accompany this dataset with an open-source Python package to: rebuild or extend the WorldStrat dataset, train and infer baseline algorithms, and learn with abundant tutorials, all compatible with the popular EO-learn toolbox. We hereby hope to foster broad-spectrum applications of ML to satellite imagery, and possibly develop from free public low-resolution Sentinel2 imagery the same power of analysis allowed by costly private high-resolution imagery. We illustrate this specific point by training and releasing several highly compute-efficient baselines on the task of Multi-Frame Super-Resolution. High-resolution Airbus imagery is CC BY-NC, while the labels and Sentinel2 imagery are CC BY, and the source code and pre-trained models under BSD. The dataset is available at https://zenodo.org/record/6810792 and the software package at https://github.com/worldstrat/worldstrat .
Objects of violence: synthetic data for practical ML in human rights investigations
Apr 01, 2020
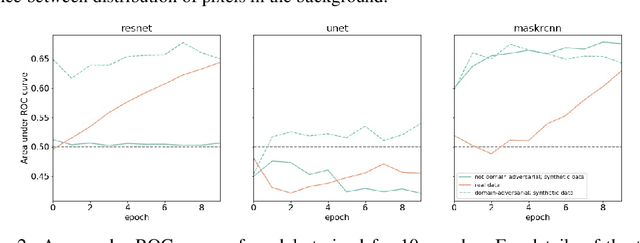


We introduce a machine learning workflow to search for, identify, and meaningfully triage videos and images of munitions, weapons, and military equipment, even when limited training data exists for the object of interest. This workflow is designed to expedite the work of OSINT ("open source intelligence") researchers in human rights investigations. It consists of three components: automatic rendering and annotating of synthetic datasets that make up for a lack of training data; training image classifiers from combined sets of photographic and synthetic data; and mtriage, an open source software that orchestrates these classifiers' deployment to triage public domain media, and visualise predictions in a web interface. We show that synthetic data helps to train classifiers more effectively, and that certain approaches yield better results for different architectures. We then demonstrate our workflow in two real-world human rights investigations: the use of the Triple-Chaser tear gas grenade against civilians, and the verification of allegations of military presence in Ukraine in 2014.
HighRes-net: Recursive Fusion for Multi-Frame Super-Resolution of Satellite Imagery
Feb 15, 2020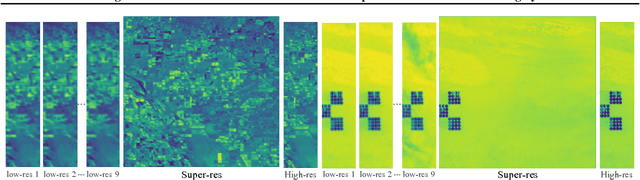
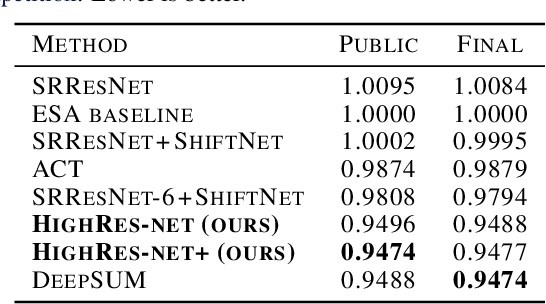
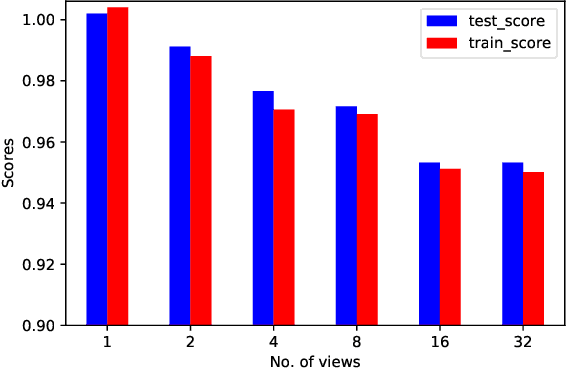
Generative deep learning has sparked a new wave of Super-Resolution (SR) algorithms that enhance single images with impressive aesthetic results, albeit with imaginary details. Multi-frame Super-Resolution (MFSR) offers a more grounded approach to the ill-posed problem, by conditioning on multiple low-resolution views. This is important for satellite monitoring of human impact on the planet -- from deforestation, to human rights violations -- that depend on reliable imagery. To this end, we present HighRes-net, the first deep learning approach to MFSR that learns its sub-tasks in an end-to-end fashion: (i) co-registration, (ii) fusion, (iii) up-sampling, and (iv) registration-at-the-loss. Co-registration of low-resolution views is learned implicitly through a reference-frame channel, with no explicit registration mechanism. We learn a global fusion operator that is applied recursively on an arbitrary number of low-resolution pairs. We introduce a registered loss, by learning to align the SR output to a ground-truth through ShiftNet. We show that by learning deep representations of multiple views, we can super-resolve low-resolution signals and enhance Earth Observation data at scale. Our approach recently topped the European Space Agency's MFSR competition on real-world satellite imagery.
DECoVaC: Design of Experiments with Controlled Variability Components
Sep 21, 2019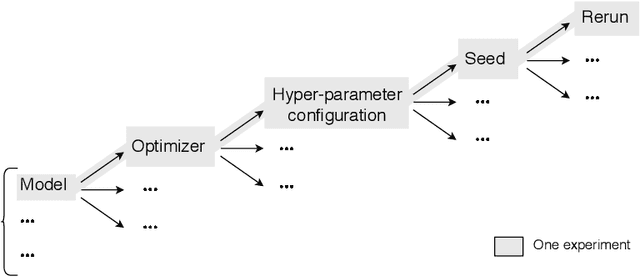
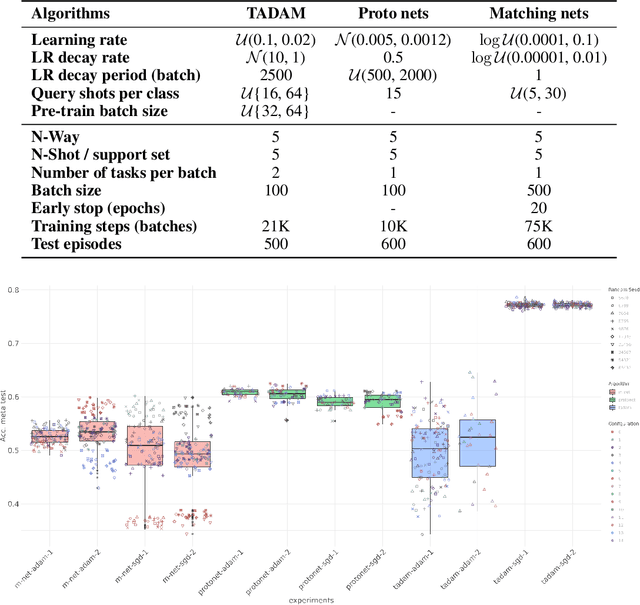

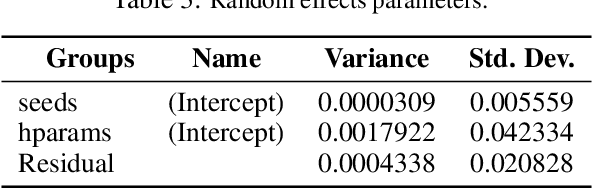
Reproducible research in Machine Learning has seen a salutary abundance of progress lately: workflows, transparency, and statistical analysis of validation and test performance. We build on these efforts and take them further. We offer a principled experimental design methodology, based on linear mixed models, to study and separate the effects of multiple factors of variation in machine learning experiments. This approach allows to account for the effects of architecture, optimizer, hyper-parameters, intentional randomization, as well as unintended lack of determinism across reruns. We illustrate that methodology by analyzing Matching Networks, Prototypical Networks and TADAM on the miniImagenet dataset.
A large-scale crowdsourced analysis of abuse against women journalists and politicians on Twitter
Jan 31, 2019
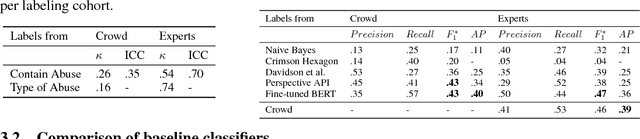
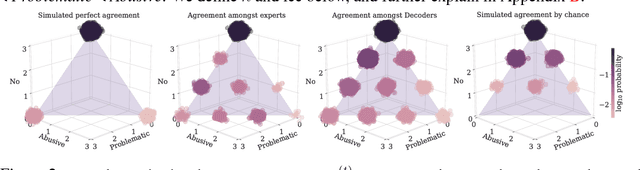
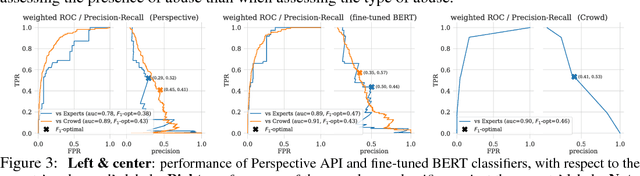
We report the first, to the best of our knowledge, hand-in-hand collaboration between human rights activists and machine learners, leveraging crowd-sourcing to study online abuse against women on Twitter. On a technical front, we carefully curate an unbiased yet low-variance dataset of labeled tweets, analyze it to account for the variability of abuse perception, and establish baselines, preparing it for release to community research efforts. On a social impact front, this study provides the technical backbone for a media campaign aimed at raising public and deciders' awareness and elevating the standards expected from social media companies.
Approximate Hubel-Wiesel Modules and the Data Structures of Neural Computation
Dec 28, 2015
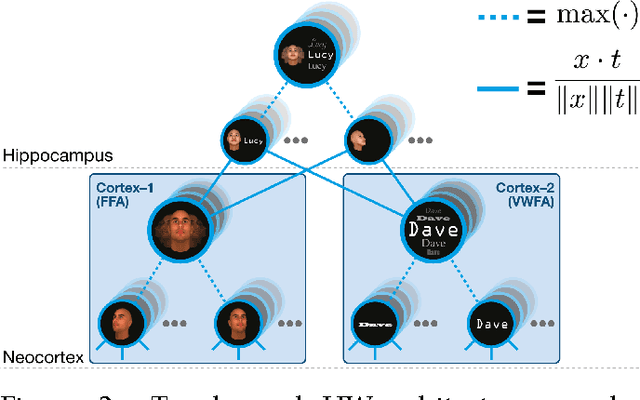
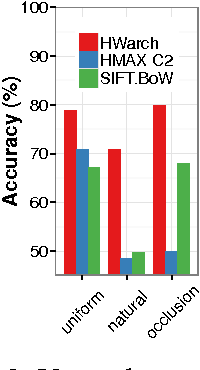
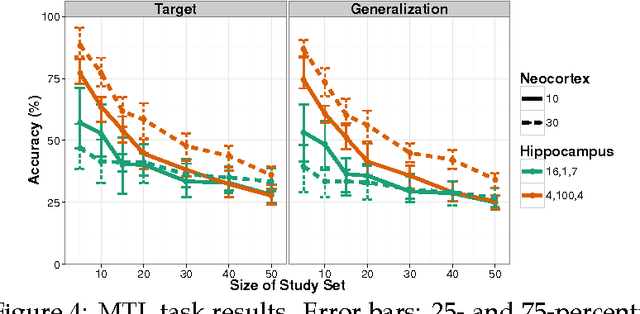
This paper describes a framework for modeling the interface between perception and memory on the algorithmic level of analysis. It is consistent with phenomena associated with many different brain regions. These include view-dependence (and invariance) effects in visual psychophysics and inferotemporal cortex physiology, as well as episodic memory recall interference effects associated with the medial temporal lobe. The perspective developed here relies on a novel interpretation of Hubel and Wiesel's conjecture for how receptive fields tuned to complex objects, and invariant to details, could be achieved. It complements existing accounts of two-speed learning systems in neocortex and hippocampus (e.g., McClelland et al. 1995) while significantly expanding their scope to encompass a unified view of the entire pathway from V1 to hippocampus.
Weight Uncertainty in Neural Networks
May 21, 2015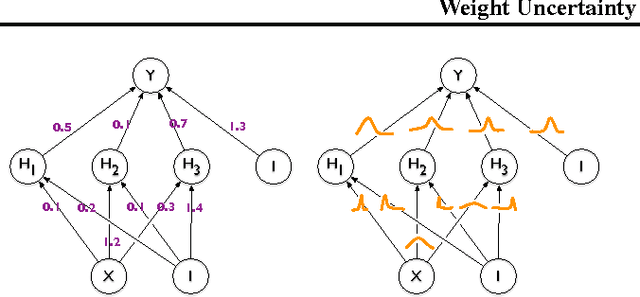
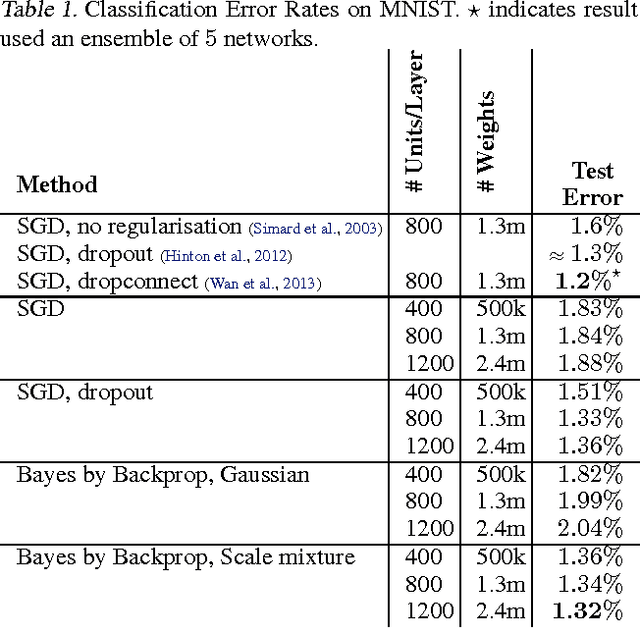
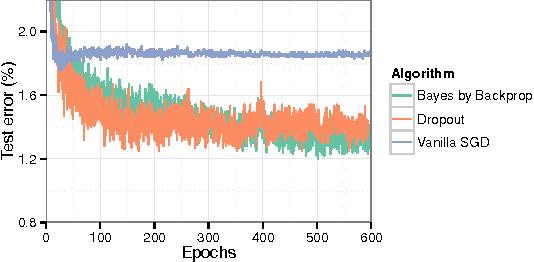

We introduce a new, efficient, principled and backpropagation-compatible algorithm for learning a probability distribution on the weights of a neural network, called Bayes by Backprop. It regularises the weights by minimising a compression cost, known as the variational free energy or the expected lower bound on the marginal likelihood. We show that this principled kind of regularisation yields comparable performance to dropout on MNIST classification. We then demonstrate how the learnt uncertainty in the weights can be used to improve generalisation in non-linear regression problems, and how this weight uncertainty can be used to drive the exploration-exploitation trade-off in reinforcement learning.
Discussion of "Riemann manifold Langevin and Hamiltonian Monte Carlo methods'' by M. Girolami and B. Calderhead
Oct 30, 2010
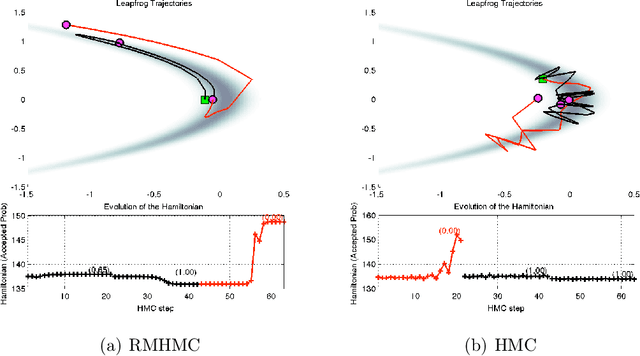
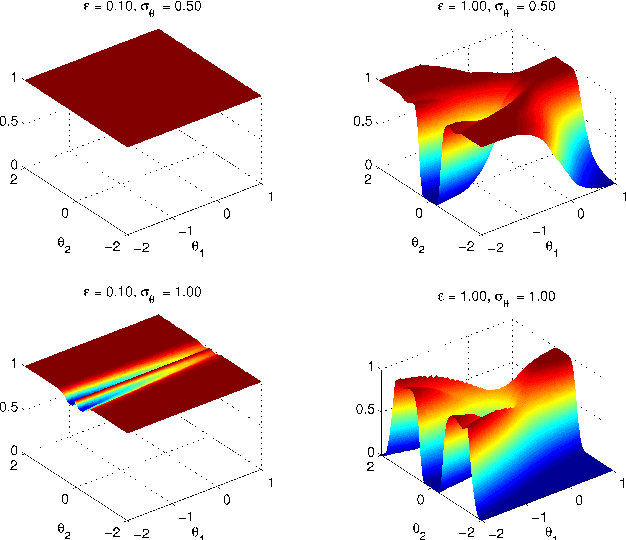
This technical report is the union of two contributions to the discussion of the Read Paper "Riemann manifold Langevin and Hamiltonian Monte Carlo methods" by B. Calderhead and M. Girolami, presented in front of the Royal Statistical Society on October 13th 2010 and to appear in the Journal of the Royal Statistical Society Series B. The first comment establishes a parallel and possible interactions with Adaptive Monte Carlo methods. The second comment exposes a detailed study of Riemannian Manifold Hamiltonian Monte Carlo (RMHMC) for a weakly identifiable model presenting a strong ridge in its geometry.