 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation of VLM for Soccer Video Understanding
May 20, 2025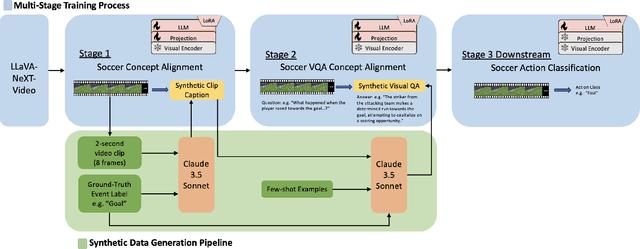

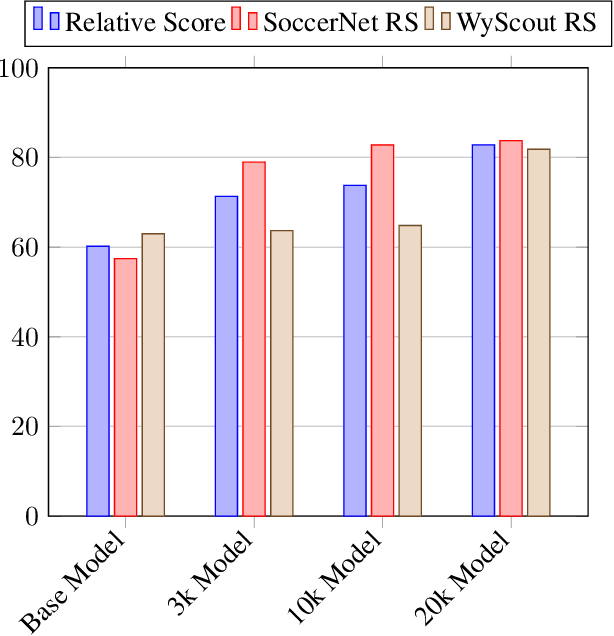

Vision Language Models (VLMs) have demonstrated strong performance in multi-modal tasks by effectively aligning visual and textual representations. However, most video understanding VLM research has been domain-agnostic, leaving the understanding of their transfer learning capability to specialized domains under-explored. In this work, we address this by exploring the adaptability of open-source VLMs to specific domains, and focusing on soccer as an initial case study. Our approach uses large-scale soccer datasets and LLM to create instruction-following data, and use them to iteratively fine-tune the general-domain VLM in a curriculum learning fashion (first teaching the model key soccer concepts to then question answering tasks). The final adapted model, trained using a curated dataset of 20k video clips, exhibits significant improvement in soccer-specific tasks compared to the base model, with a 37.5% relative improvement for the visual question-answering task and an accuracy improvement from 11.8% to 63.5% for the downstream soccer action classification task.
Mitigating stereotypical biases in text to image generative systems
Oct 10, 2023
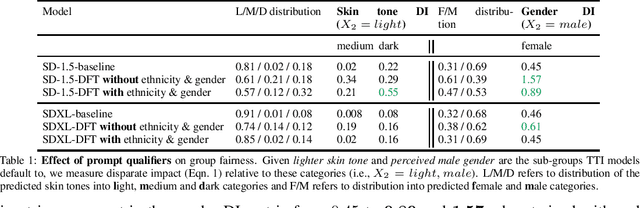


State-of-the-art generative text-to-image models are known to exhibit social biases and over-represent certain groups like people of perceived lighter skin tones and men in their outcomes. In this work, we propose a method to mitigate such biases and ensure that the outcomes are fair across different groups of people. We do this by finetuning text-to-image models on synthetic data that varies in perceived skin tones and genders constructed from diverse text prompts. These text prompts are constructed from multiplicative combinations of ethnicities, genders, professions, age groups, and so on, resulting in diverse synthetic data. Our diversity finetuned (DFT) model improves the group fairness metric by 150% for perceived skin tone and 97.7% for perceived gender. Compared to baselines, DFT models generate more people with perceived darker skin tone and more women. To foster open research, we will release all text prompts and code to generate training images.
Structure and Content-Guided Video Synthesis with Diffusion Models
Feb 06, 2023Text-guided generative diffusion models unlock powerful image creation and editing tools. While these have been extended to video generation, current approaches that edit the content of existing footage while retaining structure require expensive re-training for every input or rely on error-prone propagation of image edits across frames. In this work, we present a structure and content-guided video diffusion model that edits videos based on visual or textual descriptions of the desired output. Conflicts between user-provided content edits and structure representations occur due to insufficient disentanglement between the two aspects. As a solution, we show that training on monocular depth estimates with varying levels of detail provides control over structure and content fidelity. Our model is trained jointly on images and videos which also exposes explicit control of temporal consistency through a novel guidance method. Our experiments demonstrate a wide variety of successes; fine-grained control over output characteristics, customization based on a few reference images, and a strong user preference towards results by our model.
Data Augmentation for Intent Classification with Off-the-shelf Large Language Models
Apr 05, 2022

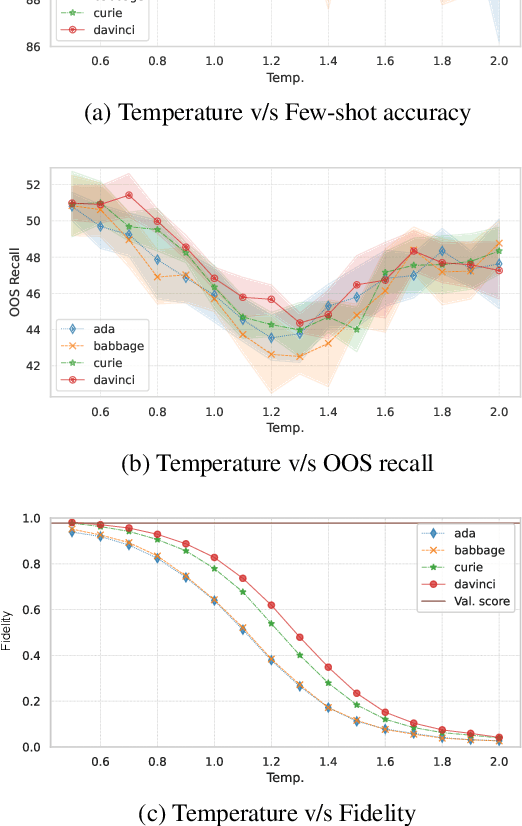

Data augmentation is a widely employed technique to alleviate the problem of data scarcity. In this work, we propose a prompting-based approach to generate labelled training data for intent classification with off-the-shelf language models (LMs) such as GPT-3. An advantage of this method is that no task-specific LM-fine-tuning for data generation is required; hence the method requires no hyper-parameter tuning and is applicable even when the available training data is very scarce. We evaluate the proposed method in a few-shot setting on four diverse intent classification tasks. We find that GPT-generated data significantly boosts the performance of intent classifiers when intents in consideration are sufficiently distinct from each other. In tasks with semantically close intents, we observe that the generated data is less helpful. Our analysis shows that this is because GPT often generates utterances that belong to a closely-related intent instead of the desired one. We present preliminary evidence that a prompting-based GPT classifier could be helpful in filtering the generated data to enhance its quality.
Can Active Learning Preemptively Mitigate Fairness Issues?
Apr 14, 2021



Dataset bias is one of the prevailing causes of unfairness in machine learning. Addressing fairness at the data collection and dataset preparation stages therefore becomes an essential part of training fairer algorithms. In particular, active learning (AL) algorithms show promise for the task by drawing importance to the most informative training samples. However, the effect and interaction between existing AL algorithms and algorithmic fairness remain under-explored. In this paper, we study whether models trained with uncertainty-based AL heuristics such as BALD are fairer in their decisions with respect to a protected class than those trained with identically independently distributed (i.i.d.) sampling. We found a significant improvement on predictive parity when using BALD, while also improving accuracy compared to i.i.d. sampling. We also explore the interaction of algorithmic fairness methods such as gradient reversal (GRAD) and BALD. We found that, while addressing different fairness issues, their interaction further improves the results on most benchmarks and metrics we explored.
Synbols: Probing Learning Algorithms with Synthetic Datasets
Sep 14, 2020
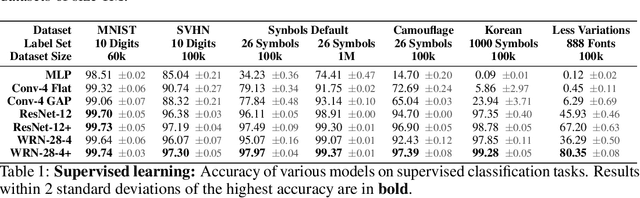
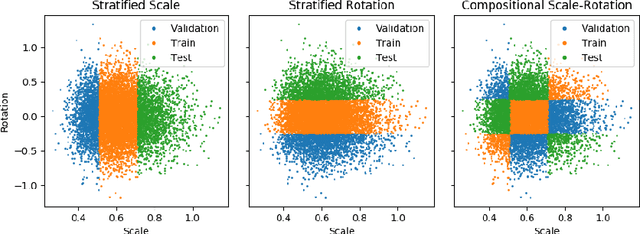
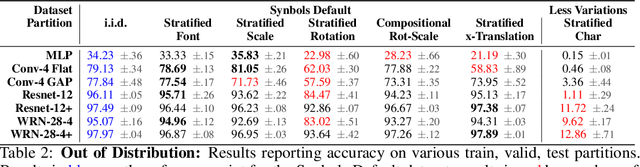
Progress in the field of machine learning has been fueled by the introduction of benchmark datasets pushing the limits of existing algorithms. Enabling the design of datasets to test specific properties and failure modes of learning algorithms is thus a problem of high interest, as it has a direct impact on innovation in the field. In this sense, we introduce Synbols -- Synthetic Symbols -- a tool for rapidly generating new datasets with a rich composition of latent features rendered in low resolution images. Synbols leverages the large amount of symbols available in the Unicode standard and the wide range of artistic font provided by the open font community. Our tool's high-level interface provides a language for rapidly generating new distributions on the latent features, including various types of textures and occlusions. To showcase the versatility of Synbols, we use it to dissect the limitations and flaws in standard learning algorithms in various learning setups including supervised learning, active learning, out of distribution generalization, unsupervised representation learning, and object counting.
A Weakly Supervised Region-Based Active Learning Method for COVID-19 Segmentation in CT Images
Jul 07, 2020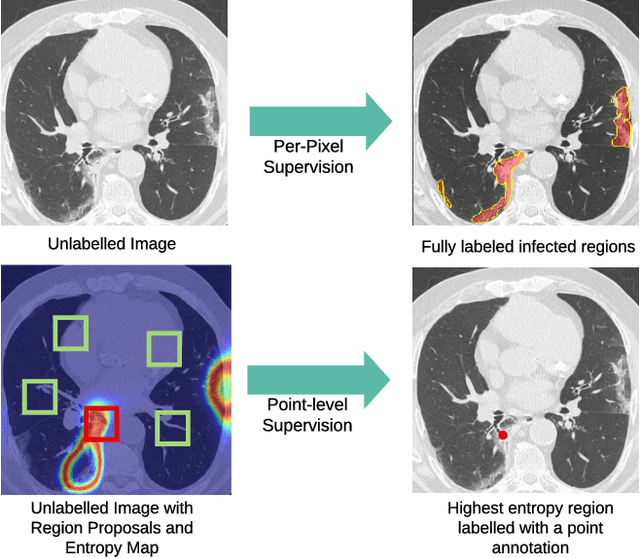
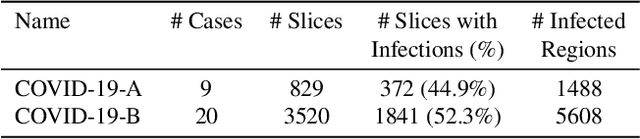
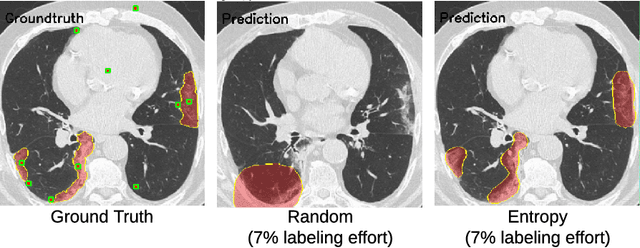
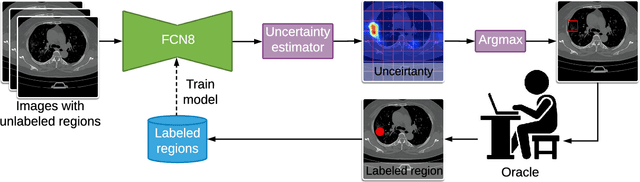
One of the key challenges in the battle against the Coronavirus (COVID-19) pandemic is to detect and quantify the severity of the disease in a timely manner. Computed tomographies (CT) of the lungs are effective for assessing the state of the infection. Unfortunately, labeling CT scans can take a lot of time and effort, with up to 150 minutes per scan. We address this challenge introducing a scalable, fast, and accurate active learning system that accelerates the labeling of CT scan images. Conventionally, active learning methods require the labelers to annotate whole images with full supervision, but that can lead to wasted efforts as many of the annotations could be redundant. Thus, our system presents the annotator with unlabeled regions that promise high information content and low annotation cost. Further, the system allows annotators to label regions using point-level supervision, which is much cheaper to acquire than per-pixel annotations. Our experiments on open-source COVID-19 datasets show that using an entropy-based method to rank unlabeled regions yields to significantly better results than random labeling of these regions. Also, we show that labeling small regions of images is more efficient than labeling whole images. Finally, we show that with only 7\% of the labeling effort required to label the whole training set gives us around 90\% of the performance obtained by training the model on the fully annotated training set. Code is available at: \url{https://github.com/IssamLaradji/covid19_active_learning}.
Bayesian active learning for production, a systematic study and a reusable library
Jun 17, 2020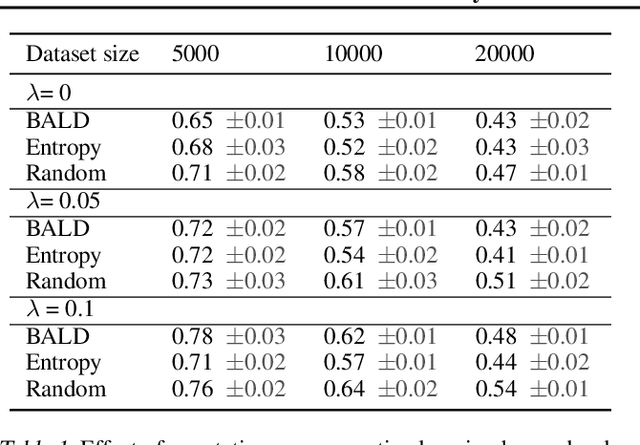


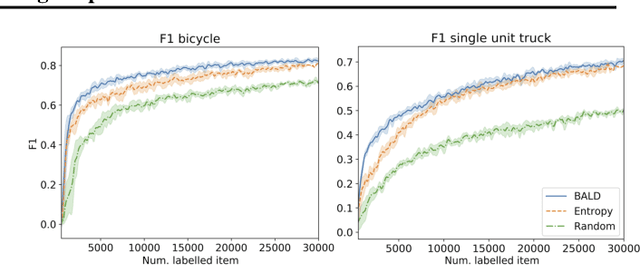
Active learning is able to reduce the amount of labelling effort by using a machine learning model to query the user for specific inputs. While there are many papers on new active learning techniques, these techniques rarely satisfy the constraints of a real-world project. In this paper, we analyse the main drawbacks of current active learning techniques and we present approaches to alleviate them. We do a systematic study on the effects of the most common issues of real-world datasets on the deep active learning process: model convergence, annotation error, and dataset imbalance. We derive two techniques that can speed up the active learning loop such as partial uncertainty sampling and larger query size. Finally, we present our open-source Bayesian active learning library, BaaL.
DECoVaC: Design of Experiments with Controlled Variability Components
Sep 21, 2019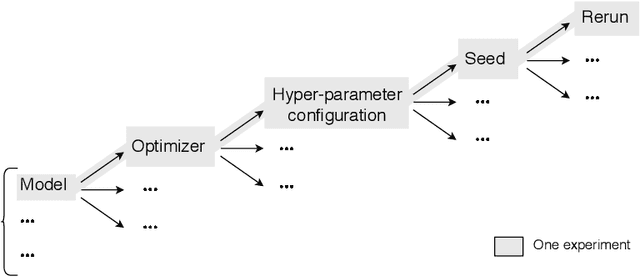
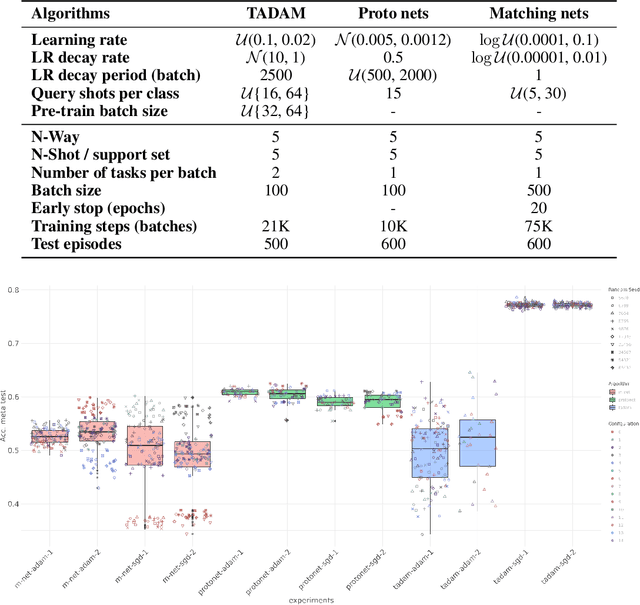

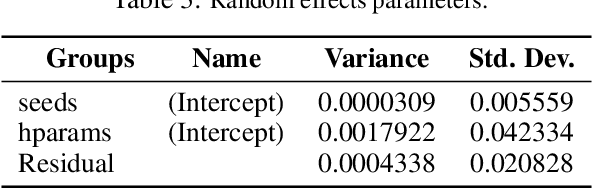
Reproducible research in Machine Learning has seen a salutary abundance of progress lately: workflows, transparency, and statistical analysis of validation and test performance. We build on these efforts and take them further. We offer a principled experimental design methodology, based on linear mixed models, to study and separate the effects of multiple factors of variation in machine learning experiments. This approach allows to account for the effects of architecture, optimizer, hyper-parameters, intentional randomization, as well as unintended lack of determinism across reruns. We illustrate that methodology by analyzing Matching Networks, Prototypical Networks and TADAM on the miniImagenet dataset.