 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Bayesian Learning with posteriors
May 31, 2024Although theoretically compelling, Bayesian learning with modern machine learning models is computationally challenging since it requires approximating a high dimensional posterior distribution. In this work, we (i) introduce posteriors, an easily extensible PyTorch library hosting general-purpose implementations making Bayesian learning accessible and scalable to large data and parameter regimes; (ii) present a tempered framing of stochastic gradient Markov chain Monte Carlo, as implemented in posteriors, that transitions seamlessly into optimization and unveils a minor modification to deep ensembles to ensure they are asymptotically unbiased for the Bayesian posterior, and (iii) demonstrate and compare the utility of Bayesian approximations through experiments including an investigation into the cold posterior effect and applications with large language models.
Exploiting Inductive Biases in Video Modeling through Neural CDEs
Nov 08, 2023We introduce a novel approach to video modeling that leverages controlled differential equations (CDEs) to address key challenges in video tasks, notably video interpolation and mask propagation. We apply CDEs at varying resolutions leading to a continuous-time U-Net architecture. Unlike traditional methods, our approach does not require explicit optical flow learning, and instead makes use of the inherent continuous-time features of CDEs to produce a highly expressive video model. We demonstrate competitive performance against state-of-the-art models for video interpolation and mask propagation tasks.
Variable Length Embeddings
May 17, 2023In this work, we introduce a novel deep learning architecture, Variable Length Embeddings (VLEs), an autoregressive model that can produce a latent representation composed of an arbitrary number of tokens. As a proof of concept, we demonstrate the capabilities of VLEs on tasks that involve reconstruction and image decomposition. We evaluate our experiments on a mix of the iNaturalist and ImageNet datasets and find that VLEs achieve comparable reconstruction results to a state of the art VAE, using less than a tenth of the parameters.
Structure and Content-Guided Video Synthesis with Diffusion Models
Feb 06, 2023Text-guided generative diffusion models unlock powerful image creation and editing tools. While these have been extended to video generation, current approaches that edit the content of existing footage while retaining structure require expensive re-training for every input or rely on error-prone propagation of image edits across frames. In this work, we present a structure and content-guided video diffusion model that edits videos based on visual or textual descriptions of the desired output. Conflicts between user-provided content edits and structure representations occur due to insufficient disentanglement between the two aspects. As a solution, we show that training on monocular depth estimates with varying levels of detail provides control over structure and content fidelity. Our model is trained jointly on images and videos which also exposes explicit control of temporal consistency through a novel guidance method. Our experiments demonstrate a wide variety of successes; fine-grained control over output characteristics, customization based on a few reference images, and a strong user preference towards results by our model.
Designing a Recurrent Neural Network to Learn a Motion Planner for High-Dimensional Inputs
May 10, 2022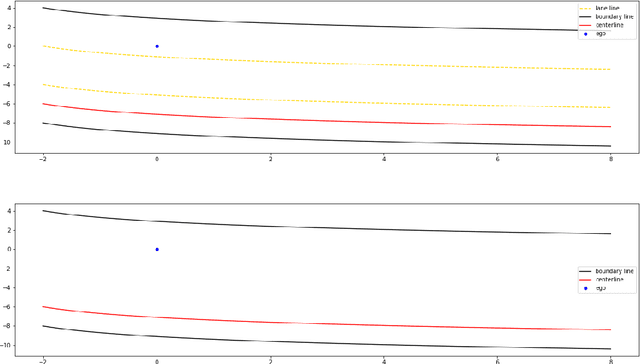
The use of machine learning in the self-driving industry has boosted a number of recent advancements. In particular, the usage of large deep learning models in the perception and prediction stack have proved quite successful, but there still lacks significant literature on the use of machine learning in the planning stack. The current state of the art in the planning stack often relies on fast constrained optimization or rule-based approaches. Both of these techniques fail to address a significant number of fundamental problems that would allow the vehicle to operate more similarly to that of human drivers. In this paper, we attempt to design a basic deep learning system to approach this problem. Furthermore, the main underlying goal of this paper is to demonstrate the potential uses of machine learning in the planning stack for autonomous vehicles (AV) and provide a baseline work for ongoing and future research.
Modeling Image Quantization Tradeoffs for Optimal Compression
Dec 14, 2021
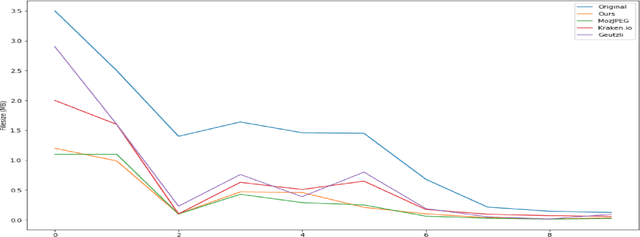


All Lossy compression algorithms employ similar compression schemes -- frequency domain transform followed by quantization and lossless encoding schemes. They target tradeoffs by quantizating high frequency data to increase compression rates which come at the cost of higher image distortion. We propose a new method of optimizing quantization tables using Deep Learning and a minimax loss function that more accurately measures the tradeoffs between rate and distortion parameters (RD) than previous methods. We design a convolutional neural network (CNN) that learns a mapping between image blocks and quantization tables in an unsupervised manner. By processing images across all channels at once, we can achieve stronger performance by also measuring tradeoffs in information loss between different channels. We initially target optimization on JPEG images but feel that this can be expanded to any lossy compressor.
Formal Analysis and Redesign of a Neural Network-Based Aircraft Taxiing System with VerifAI
May 14, 2020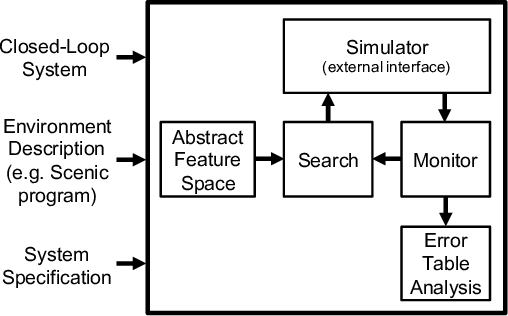

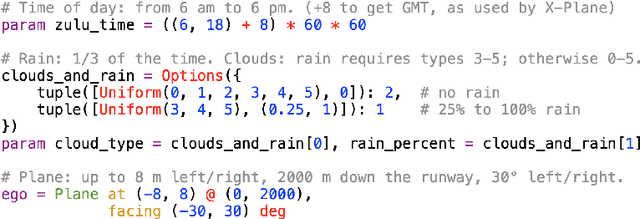
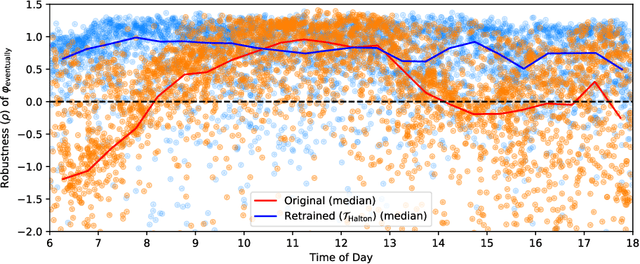
We demonstrate a unified approach to rigorous design of safety-critical autonomous systems using the VerifAI toolkit for formal analysis of AI-based systems. VerifAI provides an integrated toolchain for tasks spanning the design process, including modeling, falsification, debugging, and ML component retraining. We evaluate all of these applications in an industrial case study on an experimental autonomous aircraft taxiing system developed by Boeing, which uses a neural network to track the centerline of a runway. We define runway scenarios using the Scenic probabilistic programming language, and use them to drive tests in the X-Plane flight simulator. We first perform falsification, automatically finding environment conditions causing the system to violate its specification by deviating significantly from the centerline (or even leaving the runway entirely). Next, we use counterexample analysis to identify distinct failure cases, and confirm their root causes with specialized testing. Finally, we use the results of falsification and debugging to retrain the network, eliminating several failure cases and improving the overall performance of the closed-loop system.