 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Thermodynamic Second-order Optimization
Feb 12, 2025Many hardware proposals have aimed to accelerate inference in AI workloads. Less attention has been paid to hardware acceleration of training, despite the enormous societal impact of rapid training of AI models. Physics-based computers, such as thermodynamic computers, offer an efficient means to solve key primitives in AI training algorithms. Optimizers that normally would be computationally out-of-reach (e.g., due to expensive matrix inversions) on digital hardware could be unlocked with physics-based hardware. In this work, we propose a scalable algorithm for employing thermodynamic computers to accelerate a popular second-order optimizer called Kronecker-factored approximate curvature (K-FAC). Our asymptotic complexity analysis predicts increasing advantage with our algorithm as $n$, the number of neurons per layer, increases. Numerical experiments show that even under significant quantization noise, the benefits of second-order optimization can be preserved. Finally, we predict substantial speedups for large-scale vision and graph problems based on realistic hardware characteristics.
Thermodynamic Bayesian Inference
Oct 02, 2024A fully Bayesian treatment of complicated predictive models (such as deep neural networks) would enable rigorous uncertainty quantification and the automation of higher-level tasks including model selection. However, the intractability of sampling Bayesian posteriors over many parameters inhibits the use of Bayesian methods where they are most needed. Thermodynamic computing has emerged as a paradigm for accelerating operations used in machine learning, such as matrix inversion, and is based on the mapping of Langevin equations to the dynamics of noisy physical systems. Hence, it is natural to consider the implementation of Langevin sampling algorithms on thermodynamic devices. In this work we propose electronic analog devices that sample from Bayesian posteriors by realizing Langevin dynamics physically. Circuit designs are given for sampling the posterior of a Gaussian-Gaussian model and for Bayesian logistic regression, and are validated by simulations. It is shown, under reasonable assumptions, that the Bayesian posteriors for these models can be sampled in time scaling with $\ln(d)$, where $d$ is dimension. For the Gaussian-Gaussian model, the energy cost is shown to scale with $ d \ln(d)$. These results highlight the potential for fast, energy-efficient Bayesian inference using thermodynamic computing.
Extended Mind Transformers
Jun 04, 2024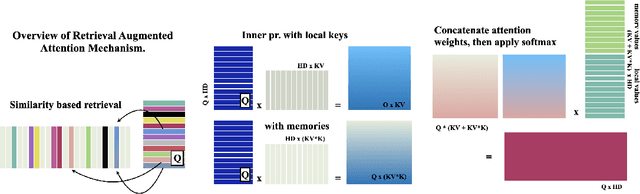
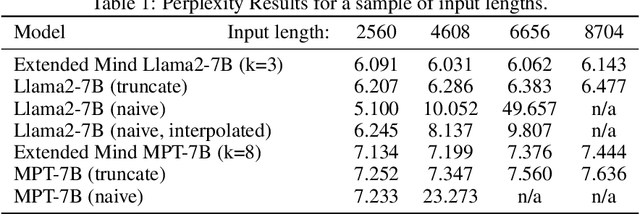
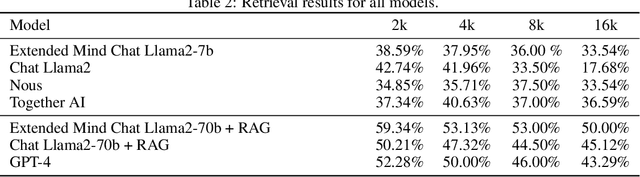
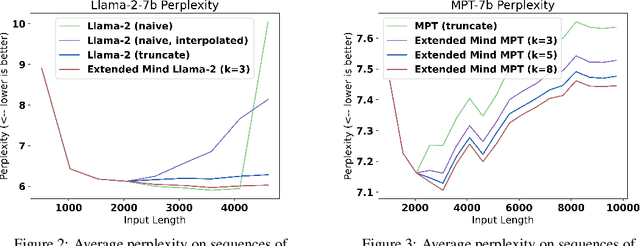
Pre-trained language models demonstrate general intelligence and common sense, but long inputs quickly become a bottleneck for memorizing information at inference time. We resurface a simple method, Memorizing Transformers (Wu et al., 2022), that gives the model access to a bank of pre-computed memories. We show that it is possible to fix many of the shortcomings of the original method, such as the need for fine-tuning, by critically assessing how positional encodings should be updated for the keys and values retrieved. This intuitive method uses the model's own key/query system to select and attend to the most relevant memories at each generation step, rather than using external embeddings. We demonstrate the importance of external information being retrieved in a majority of decoder layers, contrary to previous work. We open source a new counterfactual long-range retrieval benchmark, and show that Extended Mind Transformers outperform today's state of the art by 6% on average.
Scalable Bayesian Learning with posteriors
May 31, 2024Although theoretically compelling, Bayesian learning with modern machine learning models is computationally challenging since it requires approximating a high dimensional posterior distribution. In this work, we (i) introduce posteriors, an easily extensible PyTorch library hosting general-purpose implementations making Bayesian learning accessible and scalable to large data and parameter regimes; (ii) present a tempered framing of stochastic gradient Markov chain Monte Carlo, as implemented in posteriors, that transitions seamlessly into optimization and unveils a minor modification to deep ensembles to ensure they are asymptotically unbiased for the Bayesian posterior, and (iii) demonstrate and compare the utility of Bayesian approximations through experiments including an investigation into the cold posterior effect and applications with large language models.