 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Stochastic Gradient Posterior Sampling with Lattice Based Discretisation
Feb 17, 2026Stochastic-gradient MCMC methods enable scalable Bayesian posterior sampling but often suffer from sensitivity to minibatch size and gradient noise. To address this, we propose Stochastic Gradient Lattice Random Walk (SGLRW), an extension of the Lattice Random Walk discretization. Unlike conventional Stochastic Gradient Langevin Dynamics (SGLD), SGLRW introduces stochastic noise only through the off-diagonal elements of the update covariance; this yields greater robustness to minibatch size while retaining asymptotic correctness. Furthermore, as comparison we analyze a natural analogue of SGLD utilizing gradient clipping. Experimental validation on Bayesian regression and classification demonstrates that SGLRW remains stable in regimes where SGLD fails, including in the presence of heavy-tailed gradient noise, and matches or improves predictive performance.
A Complete Decomposition of Stochastic Differential Equations
Jan 12, 2026We show that any stochastic differential equation with prescribed time-dependent marginal distributions admits a decomposition into three components: a unique scalar field governing marginal evolution, a symmetric positive-semidefinite diffusion matrix field and a skew-symmetric matrix field.
Scalable Thermodynamic Second-order Optimization
Feb 12, 2025Many hardware proposals have aimed to accelerate inference in AI workloads. Less attention has been paid to hardware acceleration of training, despite the enormous societal impact of rapid training of AI models. Physics-based computers, such as thermodynamic computers, offer an efficient means to solve key primitives in AI training algorithms. Optimizers that normally would be computationally out-of-reach (e.g., due to expensive matrix inversions) on digital hardware could be unlocked with physics-based hardware. In this work, we propose a scalable algorithm for employing thermodynamic computers to accelerate a popular second-order optimizer called Kronecker-factored approximate curvature (K-FAC). Our asymptotic complexity analysis predicts increasing advantage with our algorithm as $n$, the number of neurons per layer, increases. Numerical experiments show that even under significant quantization noise, the benefits of second-order optimization can be preserved. Finally, we predict substantial speedups for large-scale vision and graph problems based on realistic hardware characteristics.
Thermodynamic Bayesian Inference
Oct 02, 2024A fully Bayesian treatment of complicated predictive models (such as deep neural networks) would enable rigorous uncertainty quantification and the automation of higher-level tasks including model selection. However, the intractability of sampling Bayesian posteriors over many parameters inhibits the use of Bayesian methods where they are most needed. Thermodynamic computing has emerged as a paradigm for accelerating operations used in machine learning, such as matrix inversion, and is based on the mapping of Langevin equations to the dynamics of noisy physical systems. Hence, it is natural to consider the implementation of Langevin sampling algorithms on thermodynamic devices. In this work we propose electronic analog devices that sample from Bayesian posteriors by realizing Langevin dynamics physically. Circuit designs are given for sampling the posterior of a Gaussian-Gaussian model and for Bayesian logistic regression, and are validated by simulations. It is shown, under reasonable assumptions, that the Bayesian posteriors for these models can be sampled in time scaling with $\ln(d)$, where $d$ is dimension. For the Gaussian-Gaussian model, the energy cost is shown to scale with $ d \ln(d)$. These results highlight the potential for fast, energy-efficient Bayesian inference using thermodynamic computing.
Scalable Bayesian Learning with posteriors
May 31, 2024Although theoretically compelling, Bayesian learning with modern machine learning models is computationally challenging since it requires approximating a high dimensional posterior distribution. In this work, we (i) introduce posteriors, an easily extensible PyTorch library hosting general-purpose implementations making Bayesian learning accessible and scalable to large data and parameter regimes; (ii) present a tempered framing of stochastic gradient Markov chain Monte Carlo, as implemented in posteriors, that transitions seamlessly into optimization and unveils a minor modification to deep ensembles to ensure they are asymptotically unbiased for the Bayesian posterior, and (iii) demonstrate and compare the utility of Bayesian approximations through experiments including an investigation into the cold posterior effect and applications with large language models.
Thermodynamic Natural Gradient Descent
May 22, 2024Second-order training methods have better convergence properties than gradient descent but are rarely used in practice for large-scale training due to their computational overhead. This can be viewed as a hardware limitation (imposed by digital computers). Here we show that natural gradient descent (NGD), a second-order method, can have a similar computational complexity per iteration to a first-order method, when employing appropriate hardware. We present a new hybrid digital-analog algorithm for training neural networks that is equivalent to NGD in a certain parameter regime but avoids prohibitively costly linear system solves. Our algorithm exploits the thermodynamic properties of an analog system at equilibrium, and hence requires an analog thermodynamic computer. The training occurs in a hybrid digital-analog loop, where the gradient and Fisher information matrix (or any other positive semi-definite curvature matrix) are calculated at given time intervals while the analog dynamics take place. We numerically demonstrate the superiority of this approach over state-of-the-art digital first- and second-order training methods on classification tasks and language model fine-tuning tasks.
Exploiting Inductive Biases in Video Modeling through Neural CDEs
Nov 08, 2023We introduce a novel approach to video modeling that leverages controlled differential equations (CDEs) to address key challenges in video tasks, notably video interpolation and mask propagation. We apply CDEs at varying resolutions leading to a continuous-time U-Net architecture. Unlike traditional methods, our approach does not require explicit optical flow learning, and instead makes use of the inherent continuous-time features of CDEs to produce a highly expressive video model. We demonstrate competitive performance against state-of-the-art models for video interpolation and mask propagation tasks.
A State-Space Perspective on Modelling and Inference for Online Skill Rating
Aug 04, 2023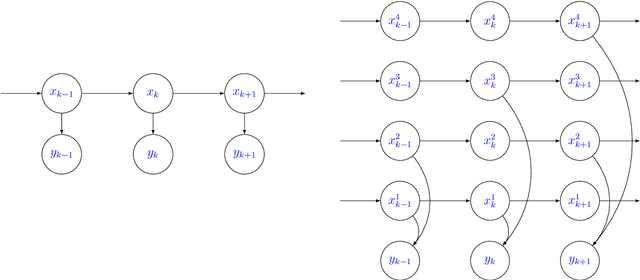

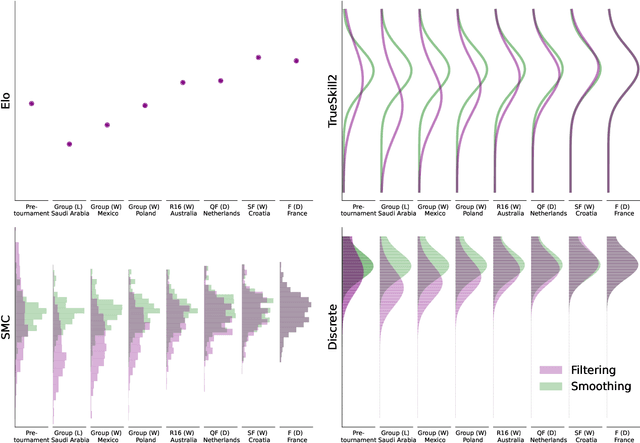
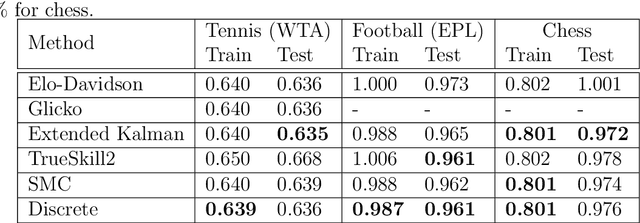
This paper offers a comprehensive review of the main methodologies used for skill rating in competitive sports. We advocate for a state-space model perspective, wherein players' skills are represented as time-varying, and match results serve as the sole observed quantities. The state-space model perspective facilitates the decoupling of modeling and inference, enabling a more focused approach highlighting model assumptions, while also fostering the development of general-purpose inference tools. We explore the essential steps involved in constructing a state-space model for skill rating before turning to a discussion on the three stages of inference: filtering, smoothing and parameter estimation. Throughout, we examine the computational challenges of scaling up to high-dimensional scenarios involving numerous players and matches, highlighting approximations and reductions used to address these challenges effectively. We provide concise summaries of popular methods documented in the literature, along with their inferential paradigms and introduce new approaches to skill rating inference based on sequential Monte Carlo and finite state-spaces. We close with numerical experiments demonstrating a practical workflow on real data across different sports.
Bayesian Learning of Parameterised Quantum Circuits
Jun 15, 2022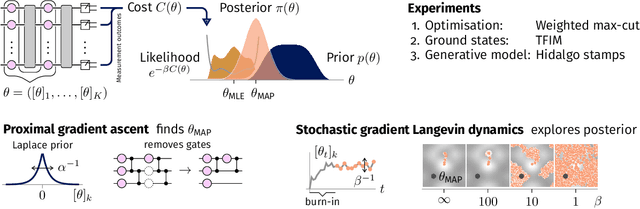
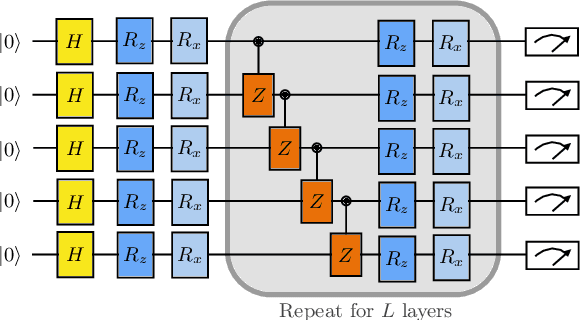
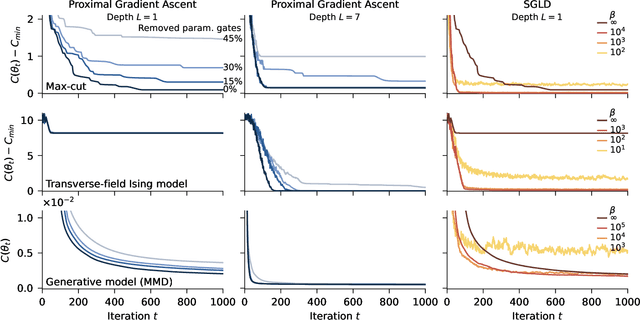
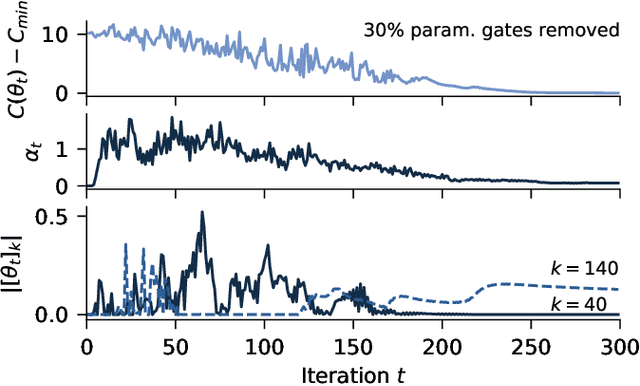
Currently available quantum computers suffer from constraints including hardware noise and a limited number of qubits. As such, variational quantum algorithms that utilise a classical optimiser in order to train a parameterised quantum circuit have drawn significant attention for near-term practical applications of quantum technology. In this work, we take a probabilistic point of view and reformulate the classical optimisation as an approximation of a Bayesian posterior. The posterior is induced by combining the cost function to be minimised with a prior distribution over the parameters of the quantum circuit. We describe a dimension reduction strategy based on a maximum a posteriori point estimate with a Laplace prior. Experiments on the Quantinuum H1-2 computer show that the resulting circuits are faster to execute and less noisy than the circuits trained without the dimension reduction strategy. We subsequently describe a posterior sampling strategy based on stochastic gradient Langevin dynamics. Numerical simulations on three different problems show that the strategy is capable of generating samples from the full posterior and avoiding local optima.