 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBig Batch Bayesian Active Learning by Considering Predictive Probabilities
Jan 14, 2025

We observe that BatchBALD, a popular acquisition function for batch Bayesian active learning for classification, can conflate epistemic and aleatoric uncertainty, leading to suboptimal performance. Motivated by this observation, we propose to focus on the predictive probabilities, which only exhibit epistemic uncertainty. The result is an acquisition function that not only performs better, but is also faster to evaluate, allowing for larger batches than before.
Error bounds for particle gradient descent, and extensions of the log-Sobolev and Talagrand inequalities
Mar 04, 2024We prove non-asymptotic error bounds for particle gradient descent (PGD)~(Kuntz et al., 2023), a recently introduced algorithm for maximum likelihood estimation of large latent variable models obtained by discretizing a gradient flow of the free energy. We begin by showing that, for models satisfying a condition generalizing both the log-Sobolev and the Polyak--{\L}ojasiewicz inequalities (LSI and P{\L}I, respectively), the flow converges exponentially fast to the set of minimizers of the free energy. We achieve this by extending a result well-known in the optimal transport literature (that the LSI implies the Talagrand inequality) and its counterpart in the optimization literature (that the P{\L}I implies the so-called quadratic growth condition), and applying it to our new setting. We also generalize the Bakry--\'Emery Theorem and show that the LSI/P{\L}I generalization holds for models with strongly concave log-likelihoods. For such models, we further control PGD's discretization error, obtaining non-asymptotic error bounds. While we are motivated by the study of PGD, we believe that the inequalities and results we extend may be of independent interest.
Momentum Particle Maximum Likelihood
Dec 12, 2023


Maximum likelihood estimation (MLE) of latent variable models is often recast as an optimization problem over the extended space of parameters and probability distributions. For example, the Expectation Maximization (EM) algorithm can be interpreted as coordinate descent applied to a suitable free energy functional over this space. Recently, this perspective has been combined with insights from optimal transport and Wasserstein gradient flows to develop particle-based algorithms applicable to wider classes of models than standard EM. Drawing inspiration from prior works which interpret `momentum-enriched' optimisation algorithms as discretizations of ordinary differential equations, we propose an analogous dynamical systems-inspired approach to minimizing the free energy functional over the extended space of parameters and probability distributions. The result is a dynamic system that blends elements of Nesterov's Accelerated Gradient method, the underdamped Langevin diffusion, and particle methods. Under suitable assumptions, we establish quantitative convergence of the proposed system to the unique minimiser of the functional in continuous time. We then propose a numerical discretization of this system which enables its application to parameter estimation in latent variable models. Through numerical experiments, we demonstrate that the resulting algorithm converges faster than existing methods and compares favourably with other (approximate) MLE algorithms.
A State-Space Perspective on Modelling and Inference for Online Skill Rating
Aug 04, 2023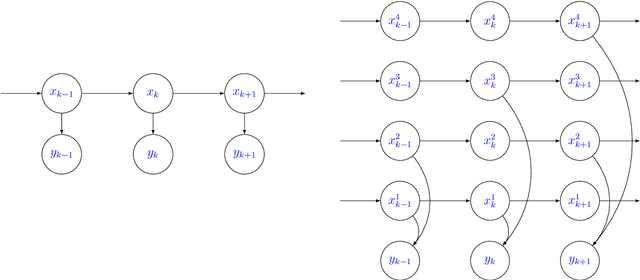

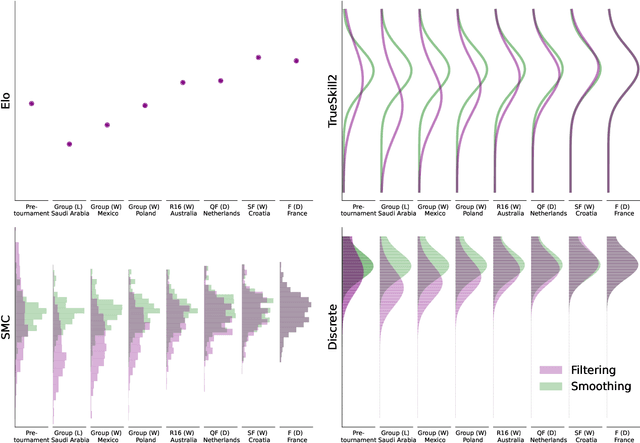
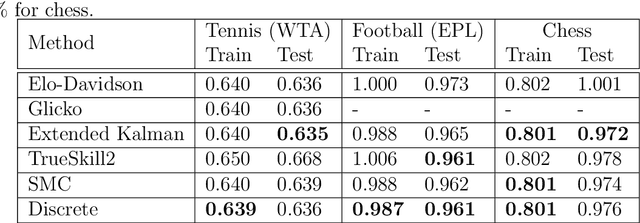
This paper offers a comprehensive review of the main methodologies used for skill rating in competitive sports. We advocate for a state-space model perspective, wherein players' skills are represented as time-varying, and match results serve as the sole observed quantities. The state-space model perspective facilitates the decoupling of modeling and inference, enabling a more focused approach highlighting model assumptions, while also fostering the development of general-purpose inference tools. We explore the essential steps involved in constructing a state-space model for skill rating before turning to a discussion on the three stages of inference: filtering, smoothing and parameter estimation. Throughout, we examine the computational challenges of scaling up to high-dimensional scenarios involving numerous players and matches, highlighting approximations and reductions used to address these challenges effectively. We provide concise summaries of popular methods documented in the literature, along with their inferential paradigms and introduce new approaches to skill rating inference based on sequential Monte Carlo and finite state-spaces. We close with numerical experiments demonstrating a practical workflow on real data across different sports.