 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scenario-Based Platform for Testing Autonomous Vehicle Behavior Prediction Models in Simulation
Nov 14, 2021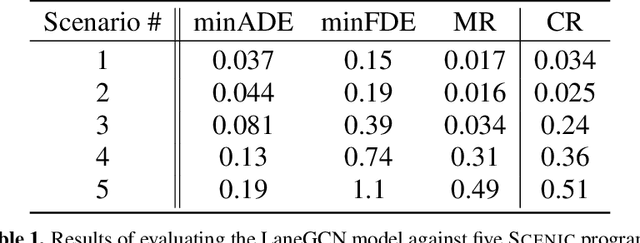

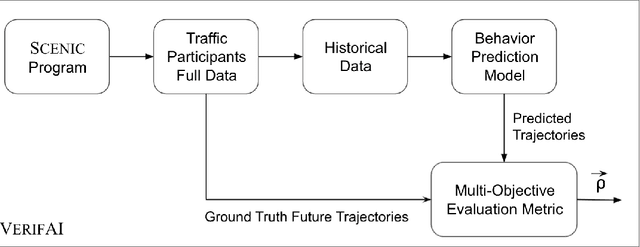
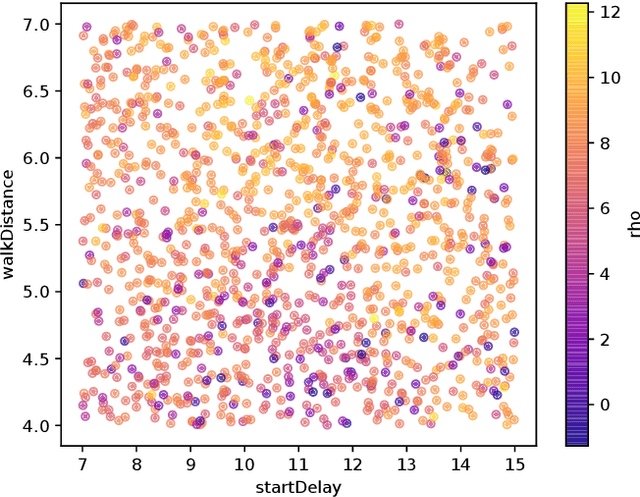
Behavior prediction remains one of the most challenging tasks in the autonomous vehicle (AV) software stack. Forecasting the future trajectories of nearby agents plays a critical role in ensuring road safety, as it equips AVs with the necessary information to plan safe routes of travel. However, these prediction models are data-driven and trained on data collected in real life that may not represent the full range of scenarios an AV can encounter. Hence, it is important that these prediction models are extensively tested in various test scenarios involving interactive behaviors prior to deployment. To support this need, we present a simulation-based testing platform which supports (1) intuitive scenario modeling with a probabilistic programming language called Scenic, (2) specifying a multi-objective evaluation metric with a partial priority ordering, (3) falsification of the provided metric, and (4) parallelization of simulations for scalable testing. As a part of the platform, we provide a library of 25 Scenic programs that model challenging test scenarios involving interactive traffic participant behaviors. We demonstrate the effectiveness and the scalability of our platform by testing a trained behavior prediction model and searching for failure scenarios.
Addressing the IEEE AV Test Challenge with Scenic and VerifAI
Aug 20, 2021

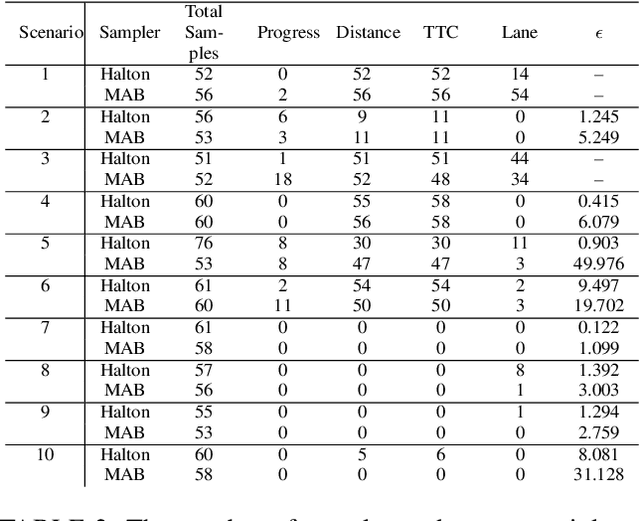
This paper summarizes our formal approach to testing autonomous vehicles (AVs) in simulation for the IEEE AV Test Challenge. We demonstrate a systematic testing framework leveraging our previous work on formally-driven simulation for intelligent cyber-physical systems. First, to model and generate interactive scenarios involving multiple agents, we used Scenic, a probabilistic programming language for specifying scenarios. A Scenic program defines an abstract scenario as a distribution over configurations of physical objects and their behaviors over time. Sampling from an abstract scenario yields many different concrete scenarios which can be run as test cases for the AV. Starting from a Scenic program encoding an abstract driving scenario, we can use the VerifAI toolkit to search within the scenario for failure cases with respect to multiple AV evaluation metrics. We demonstrate the effectiveness of our testing framework by identifying concrete failure scenarios for an open-source autopilot, Apollo, starting from a variety of realistic traffic scenarios.
Parallel and Multi-Objective Falsification with Scenic and VerifAI
Jul 09, 2021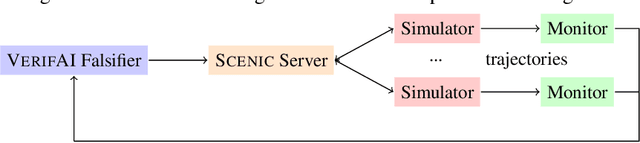

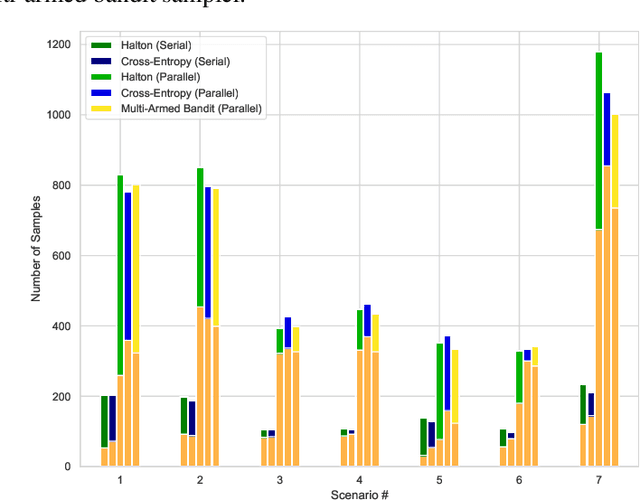
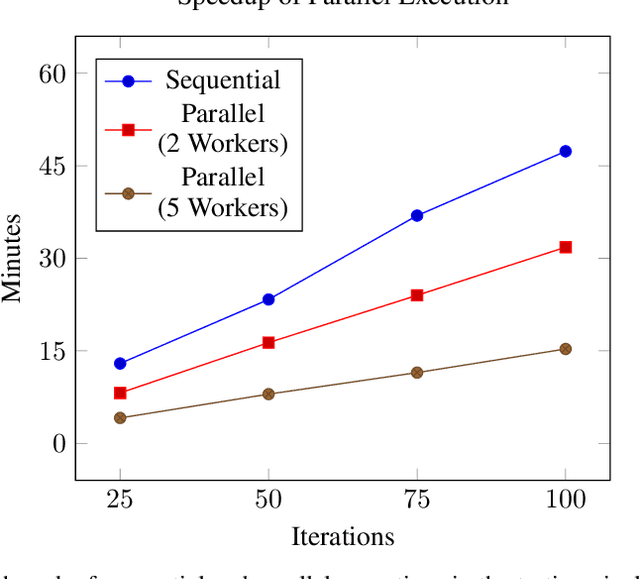
Falsification has emerged as an important tool for simulation-based verification of autonomous systems. In this paper, we present extensions to the Scenic scenario specification language and VerifAI toolkit that improve the scalability of sampling-based falsification methods by using parallelism and extend falsification to multi-objective specifications. We first present a parallelized framework that is interfaced with both the simulation and sampling capabilities of Scenic and the falsification capabilities of VerifAI, reducing the execution time bottleneck inherently present in simulation-based testing. We then present an extension of VerifAI's falsification algorithms to support multi-objective optimization during sampling, using the concept of rulebooks to specify a preference ordering over multiple metrics that can be used to guide the counterexample search process. Lastly, we evaluate the benefits of these extensions with a comprehensive set of benchmarks written in the Scenic language.
Entropy-Guided Control Improvisation
Mar 09, 2021
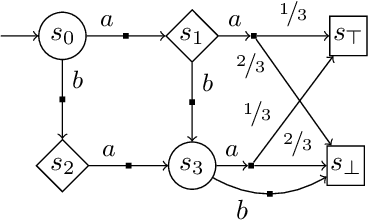
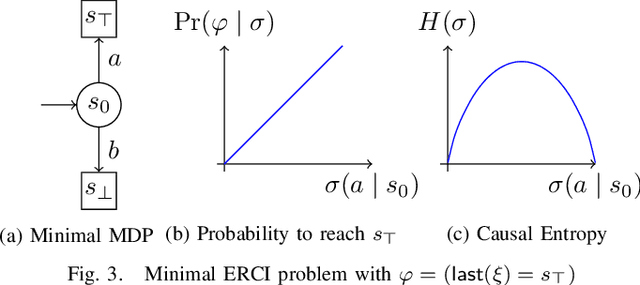
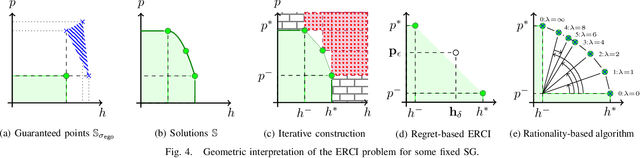
High level declarative constraints provide a powerful (and popular) way to define and construct control policies; however, most synthesis algorithms do not support specifying the degree of randomness (unpredictability) of the resulting controller. In many contexts, e.g., patrolling, testing, behavior prediction, and planning on idealized models, predictable or biased controllers are undesirable. To address these concerns, we introduce the \emph{Entropic Reactive Control Improvisation} (ERCI) framework and algorithm that supports synthesizing control policies for stochastic games that are declaratively specified by (i) a \emph{hard constraint} specifying what must occur (ii) a \emph{soft constraint} specifying what typically occurs, and (iii) a \emph{randomization constraint} specifying the unpredictability and variety of the controller, as quantified using causal entropy. This framework, which extends the state-of-the-art by supporting arbitrary combinations of adversarial and probabilistic uncertainty in the environment, enables a flexible modeling formalism which we argue, theoretically and empirically, remains tractable.
Scenic: A Language for Scenario Specification and Data Generation
Oct 13, 2020
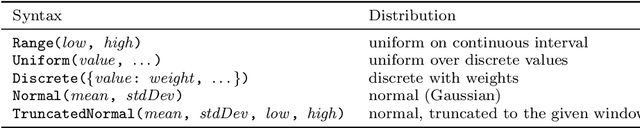
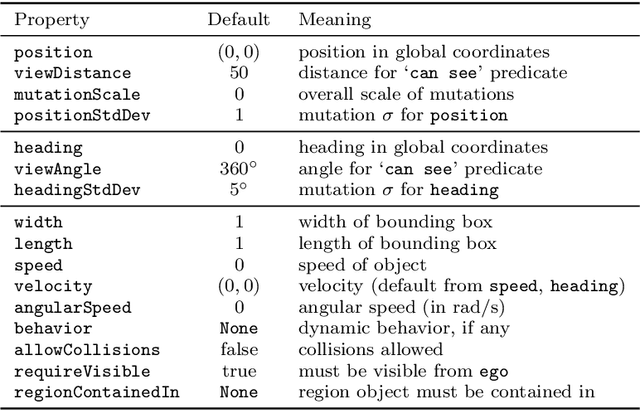
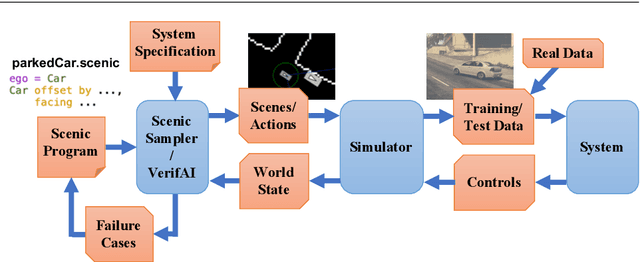
We propose a new probabilistic programming language for the design and analysis of cyber-physical systems, especially those based on machine learning. Specifically, we consider the problems of training a system to be robust to rare events, testing its performance under different conditions, and debugging failures. We show how a probabilistic programming language can help address these problems by specifying distributions encoding interesting types of inputs, then sampling these to generate specialized training and test data. More generally, such languages can be used to write environment models, an essential prerequisite to any formal analysis. In this paper, we focus on systems like autonomous cars and robots, whose environment at any point in time is a 'scene', a configuration of physical objects and agents. We design a domain-specific language, Scenic, for describing scenarios that are distributions over scenes and the behaviors of their agents over time. As a probabilistic programming language, Scenic allows assigning distributions to features of the scene, as well as declaratively imposing hard and soft constraints over the scene. We develop specialized techniques for sampling from the resulting distribution, taking advantage of the structure provided by Scenic's domain-specific syntax. Finally, we apply Scenic in a case study on a convolutional neural network designed to detect cars in road images, improving its performance beyond that achieved by state-of-the-art synthetic data generation methods.
Formal Analysis and Redesign of a Neural Network-Based Aircraft Taxiing System with VerifAI
May 14, 2020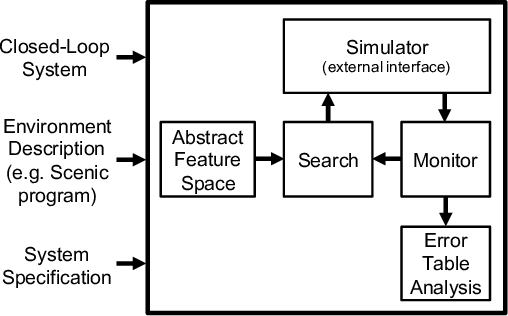

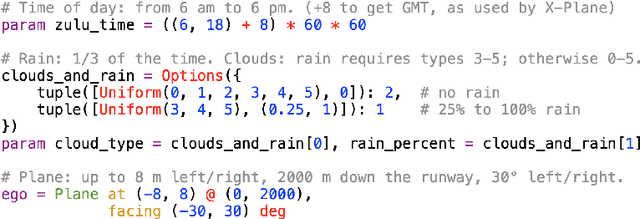
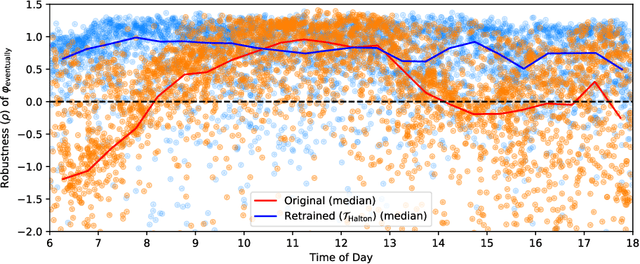
We demonstrate a unified approach to rigorous design of safety-critical autonomous systems using the VerifAI toolkit for formal analysis of AI-based systems. VerifAI provides an integrated toolchain for tasks spanning the design process, including modeling, falsification, debugging, and ML component retraining. We evaluate all of these applications in an industrial case study on an experimental autonomous aircraft taxiing system developed by Boeing, which uses a neural network to track the centerline of a runway. We define runway scenarios using the Scenic probabilistic programming language, and use them to drive tests in the X-Plane flight simulator. We first perform falsification, automatically finding environment conditions causing the system to violate its specification by deviating significantly from the centerline (or even leaving the runway entirely). Next, we use counterexample analysis to identify distinct failure cases, and confirm their root causes with specialized testing. Finally, we use the results of falsification and debugging to retrain the network, eliminating several failure cases and improving the overall performance of the closed-loop system.
Formal Scenario-Based Testing of Autonomous Vehicles: From Simulation to the Real World
Mar 17, 2020
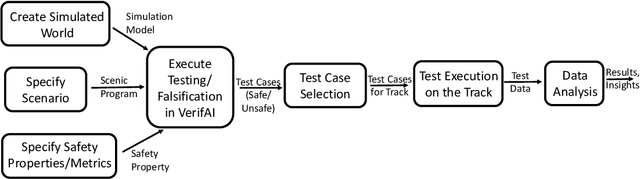
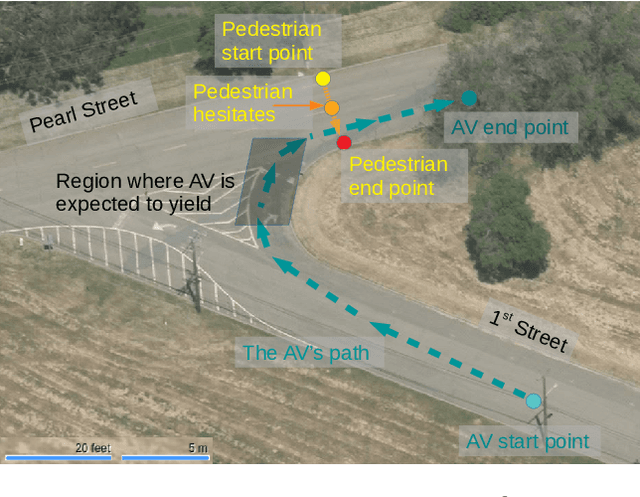
We present a new approach to automated scenario-based testing of the safety of autonomous vehicles, especially those using advanced artificial intelligence-based components, spanning both simulation-based evaluation as well as testing in the real world. Our approach is based on formal methods, combining formal specification of scenarios and safety properties, algorithmic test case generation using formal simulation, test case selection for track testing, executing test cases on the track, and analyzing the resulting data. Experiments with a real autonomous vehicle at an industrial testing ground support our hypotheses that (i) formal simulation can be effective at identifying test cases to run on the track, and (ii) the gap between simulated and real worlds can be systematically evaluated and bridged.
VERIFAI: A Toolkit for the Design and Analysis of Artificial Intelligence-Based Systems
Feb 14, 2019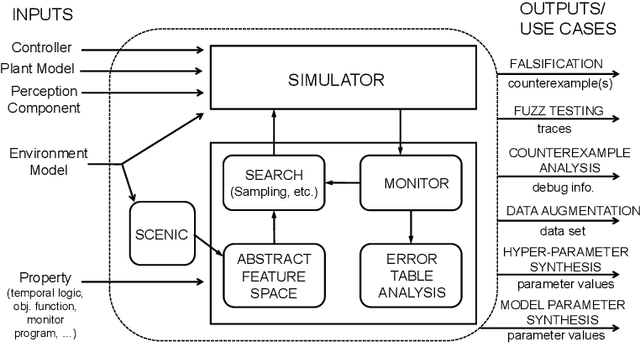



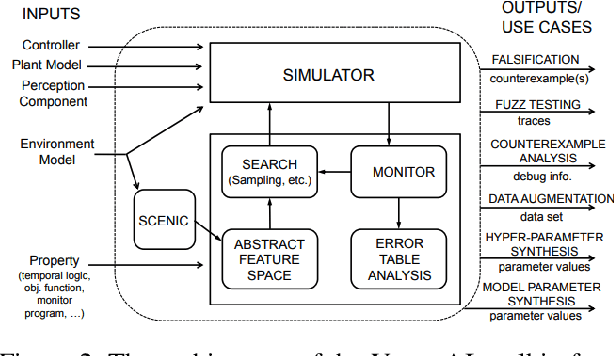
We present VERIFAI, a software toolkit for the formal design and analysis of systems that include artificial intelligence (AI) and machine learning (ML) components. VERIFAI particularly seeks to address challenges with applying formal methods to perception and ML components, including those based on neural networks, and to model and analyze system behavior in the presence of environment uncertainty. We describe the initial version of VERIFAI which centers on simulation guided by formal models and specifications. Several use cases are illustrated with examples, including temporal-logic falsification, model-based systematic fuzz testing, parameter synthesis, counterexample analysis, and data set augmentation.
Scenic: Language-Based Scene Generation
Sep 25, 2018
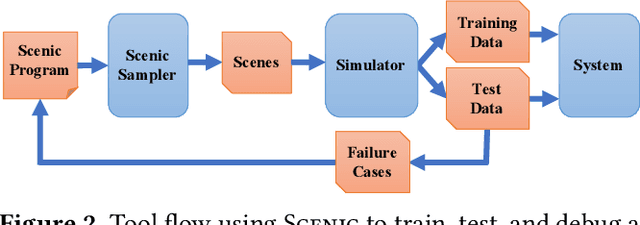
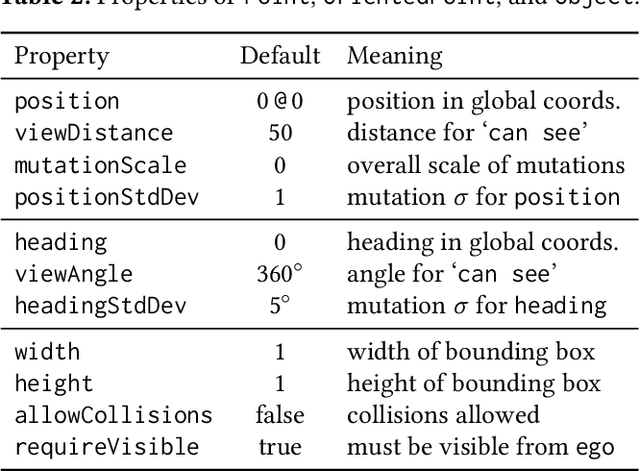

Synthetic data has proved increasingly useful in both training and testing machine learning models such as neural networks. The major problem in synthetic data generation is producing meaningful data that is not simply random but reflects properties of real-world data or covers particular cases of interest. In this paper, we show how a probabilistic programming language can be used to guide data synthesis by encoding domain knowledge about what data is useful. Specifically, we focus on data sets arising from "scenes", configurations of physical objects; for example, images of cars on a road. We design a domain-specific language, Scenic, for describing "scenarios" that are distributions over scenes. The syntax of Scenic makes it easy to specify complex relationships between the positions and orientations of objects. As a probabilistic programming language, Scenic allows assigning distributions to features of the scene, as well as declaratively imposing hard and soft constraints over the scene. A Scenic scenario thereby implicitly defines a distribution over scenes, and we formulate the problem of sampling from this distribution as "scene improvisation". We implement an improviser for Scenic scenarios and apply it in a case study generating synthetic data sets for a convolutional neural network designed to detect cars in road images. Our experiments demonstrate the usefulness of our approach by using Scenic to analyze and improve the performance of the network in various scenarios.
Constrained Sampling and Counting: Universal Hashing Meets SAT Solving
Dec 21, 2015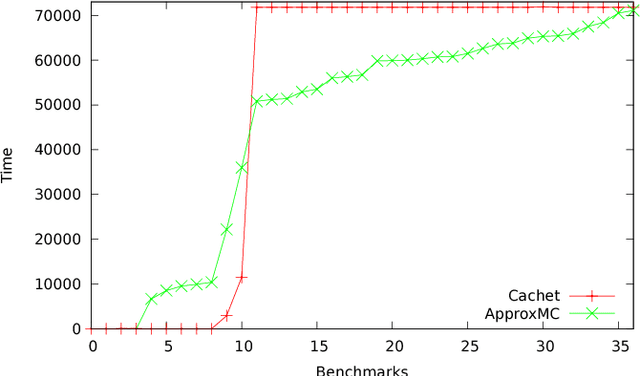
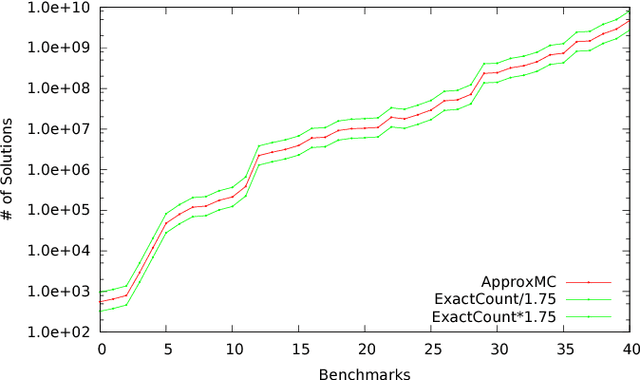
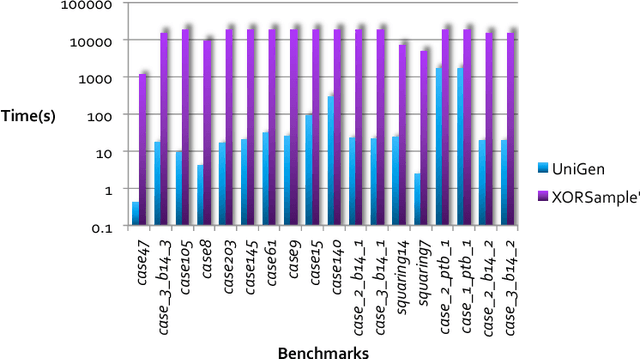
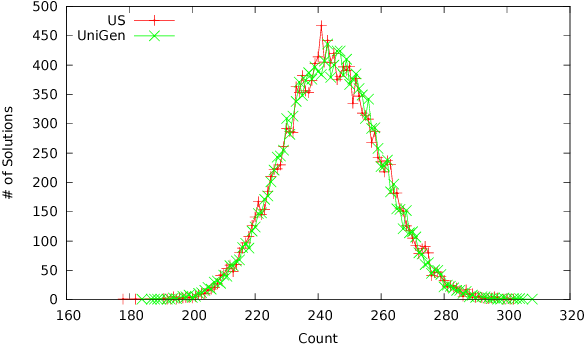
Constrained sampling and counting are two fundamental problems in artificial intelligence with a diverse range of applications, spanning probabilistic reasoning and planning to constrained-random verification. While the theory of these problems was thoroughly investigated in the 1980s, prior work either did not scale to industrial size instances or gave up correctness guarantees to achieve scalability. Recently, we proposed a novel approach that combines universal hashing and SAT solving and scales to formulas with hundreds of thousands of variables without giving up correctness guarantees. This paper provides an overview of the key ingredients of the approach and discusses challenges that need to be overcome to handle larger real-world instances.