 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multi-Objective Planning with Weighted Maximization Using Large Neighbourhood Search
Apr 06, 2026Autonomous navigation often requires the simultaneous optimization of multiple objectives. The most common approach scalarizes these into a single cost function using a weighted sum, but this method is unable to find all possible trade-offs and can therefore miss critical solutions. An alternative, the weighted maximum of objectives, can find all Pareto-optimal solutions, including those in non-convex regions of the trade-off space that weighted sum methods cannot find. However, the increased computational complexity of finding weighted maximum solutions in the discrete domain has limited its practical use. To address this challenge, we propose a novel search algorithm based on the Large Neighbourhood Search framework that efficiently solves the weighted maximum planning problem. Through extensive simulations, we demonstrate that our algorithm achieves comparable solution quality to existing weighted maximum planners with a runtime improvement of 1-2 orders of magnitude, making it a viable option for autonomous navigation.
Hierarchical Informative Path Planning via Graph Guidance and Trajectory Optimization
Jan 23, 2026We study informative path planning (IPP) with travel budgets in cluttered environments, where an agent collects measurements of a latent field modeled as a Gaussian process (GP) to reduce uncertainty at target locations. Graph-based solvers provide global guarantees but assume pre-selected measurement locations, while continuous trajectory optimization supports path-based sensing but is computationally intensive and sensitive to initialization in obstacle-dense settings. We propose a hierarchical framework with three stages: (i) graph-based global planning, (ii) segment-wise budget allocation using geometric and kernel bounds, and (iii) spline-based refinement of each segment with hard constraints and obstacle pruning. By combining global guidance with local refinement, our method achieves lower posterior uncertainty than graph-only and continuous baselines, while running faster than continuous-space solvers (up to 9x faster than gradient-based methods and 20x faster than black-box optimizers) across synthetic cluttered environments and Arctic datasets.
DiffFP: Learning Behaviors from Scratch via Diffusion-based Fictitious Play
Nov 17, 2025Self-play reinforcement learning has demonstrated significant success in learning complex strategic and interactive behaviors in competitive multi-agent games. However, achieving such behaviors in continuous decision spaces remains challenging. Ensuring adaptability and generalization in self-play settings is critical for achieving competitive performance in dynamic multi-agent environments. These challenges often cause methods to converge slowly or fail to converge at all to a Nash equilibrium, making agents vulnerable to strategic exploitation by unseen opponents. To address these challenges, we propose DiffFP, a fictitious play (FP) framework that estimates the best response to unseen opponents while learning a robust and multimodal behavioral policy. Specifically, we approximate the best response using a diffusion policy that leverages generative modeling to learn adaptive and diverse strategies. Through empirical evaluation, we demonstrate that the proposed FP framework converges towards $ε$-Nash equilibria in continuous- space zero-sum games. We validate our method on complex multi-agent environments, including racing and multi-particle zero-sum games. Simulation results show that the learned policies are robust against diverse opponents and outperform baseline reinforcement learning policies. Our approach achieves up to 3$\times$ faster convergence and 30$\times$ higher success rates on average against RL-based baselines, demonstrating its robustness to opponent strategies and stability across training iterations
SAC-MoE: Reinforcement Learning with Mixture-of-Experts for Control of Hybrid Dynamical Systems with Uncertainty
Nov 15, 2025
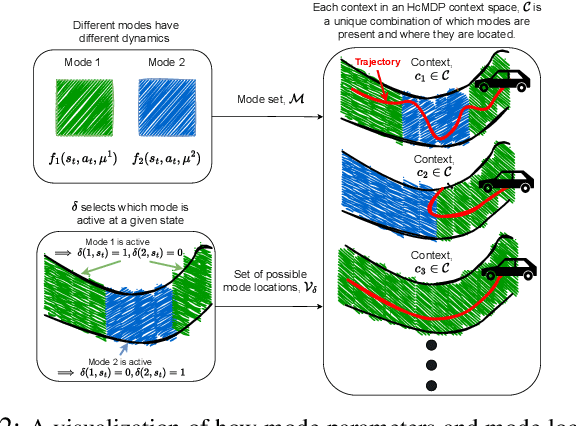
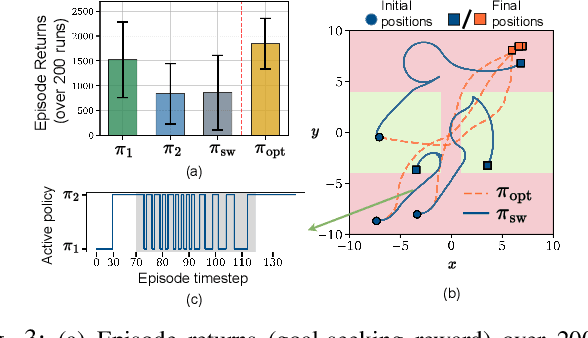
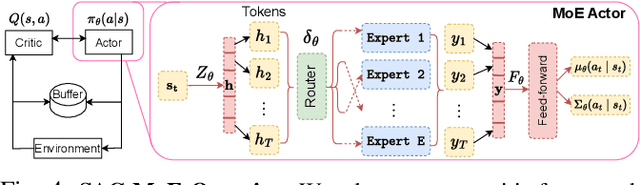
Hybrid dynamical systems result from the interaction of continuous-variable dynamics with discrete events and encompass various systems such as legged robots, vehicles and aircrafts. Challenges arise when the system's modes are characterized by unobservable (latent) parameters and the events that cause system dynamics to switch between different modes are also unobservable. Model-based control approaches typically do not account for such uncertainty in the hybrid dynamics, while standard model-free RL methods fail to account for abrupt mode switches, leading to poor generalization. To overcome this, we propose SAC-MoE which models the actor of the Soft Actor-Critic (SAC) framework as a Mixture-of-Experts (MoE) with a learned router that adaptively selects among learned experts. To further improve robustness, we develop a curriculum-based training algorithm to prioritize data collection in challenging settings, allowing better generalization to unseen modes and switching locations. Simulation studies in hybrid autonomous racing and legged locomotion tasks show that SAC-MoE outperforms baselines (up to 6x) in zero-shot generalization to unseen environments. Our curriculum strategy consistently improves performance across all evaluated policies. Qualitative analysis shows that the interpretable MoE router activates different experts for distinct latent modes.
GenPlan: Generative sequence models as adaptive planners
Dec 11, 2024Offline reinforcement learning has shown tremendous success in behavioral planning by learning from previously collected demonstrations. However, decision-making in multitask missions still presents significant challenges. For instance, a mission might require an agent to explore an unknown environment, discover goals, and navigate to them, even if it involves interacting with obstacles along the way. Such behavioral planning problems are difficult to solve due to: a) agents failing to adapt beyond the single task learned through their reward function, and b) the inability to generalize to new environments not covered in the training demonstrations, e.g., environments where all doors were unlocked in the demonstrations. Consequently, state-of-the-art decision making methods are limited to missions where the required tasks are well-represented in the training demonstrations and can be solved within a short (temporal) planning horizon. To address this, we propose GenPlan: a stochastic and adaptive planner that leverages discrete-flow models for generative sequence modeling, enabling sample-efficient exploration and exploitation. This framework relies on an iterative denoising procedure to generate a sequence of goals and actions. This approach captures multi-modal action distributions and facilitates goal and task discovery, thereby enhancing generalization to out-of-distribution tasks and environments, i.e., missions not part of the training data. We demonstrate the effectiveness of our method through multiple simulation environments. Notably, GenPlan outperforms the state-of-the-art methods by over 10% on adaptive planning tasks, where the agent adapts to multi-task missions while leveraging demonstrations on single-goal-reaching tasks.
Adaptformer: Sequence models as adaptive iterative planners
Nov 30, 2024Despite recent advances in learning-based behavioral planning for autonomous systems, decision-making in multi-task missions remains a challenging problem. For instance, a mission might require a robot to explore an unknown environment, locate the goals, and navigate to them, even if there are obstacles along the way. Such problems are difficult to solve due to: a) sparse rewards, meaning a reward signal is available only once all the tasks in a mission have been satisfied, and b) the agent having to perform tasks at run-time that are not covered in the training data, e.g., demonstrations only from an environment where all doors were unlocked. Consequently, state-of-the-art decision-making methods in such settings are limited to missions where the required tasks are well-represented in the training demonstrations and can be solved within a short planning horizon. To overcome these limitations, we propose Adaptformer, a stochastic and adaptive planner that utilizes sequence models for sample-efficient exploration and exploitation. This framework relies on learning an energy-based heuristic, which needs to be minimized over a sequence of high-level decisions. To generate successful action sequences for long-horizon missions, Adaptformer aims to achieve shorter sub-goals, which are proposed through an intrinsic sub-goal curriculum. Through these two key components, Adaptformer allows for generalization to out-of-distribution tasks and environments, i.e., missions that were not a part of the training data. Empirical results in multiple simulation environments demonstrate the effectiveness of our method. Notably, Adaptformer not only outperforms the state-of-the-art method by up to 25% in multi-goal maze reachability tasks but also successfully adapts to multi-task missions that the state-of-the-art method could not complete, leveraging demonstrations from single-goal-reaching tasks.
Enhancing Safety in Mixed Traffic: Learning-Based Modeling and Efficient Control of Autonomous and Human-Driven Vehicles
Apr 10, 2024
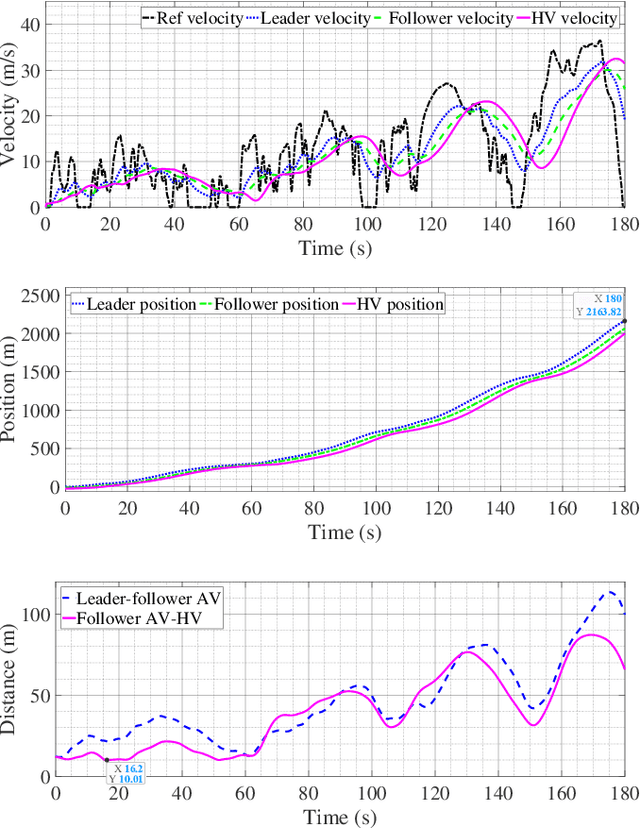
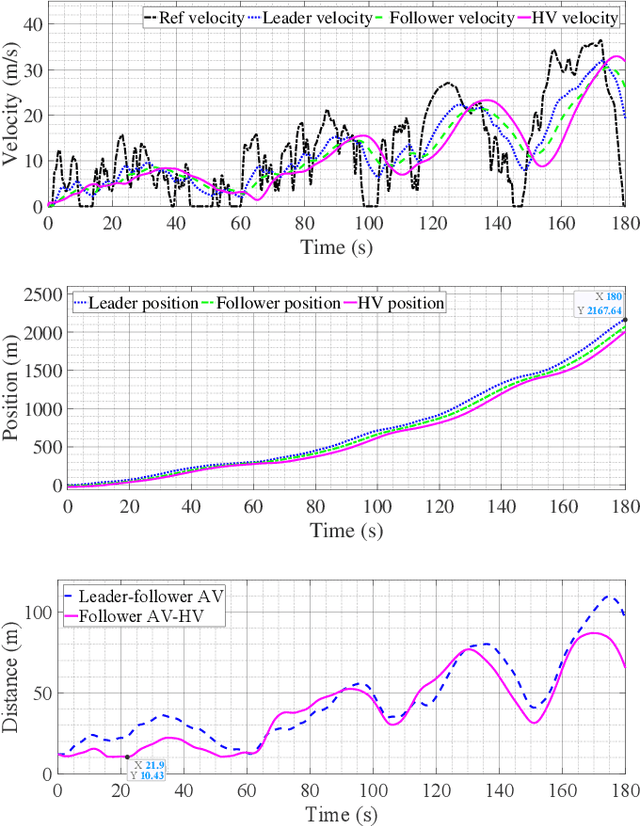
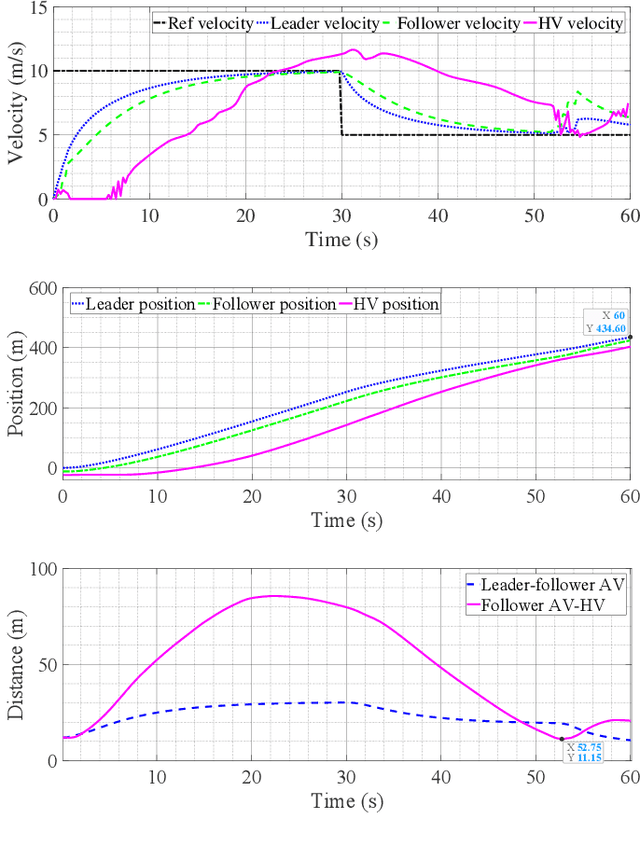
With the increasing presence of autonomous vehicles (AVs) on public roads, developing robust control strategies to navigate the uncertainty of human-driven vehicles (HVs) is crucial. This paper introduces an advanced method for modeling HV behavior, combining a first-principles model with Gaussian process (GP) learning to enhance velocity prediction accuracy and provide a measurable uncertainty. We validated this innovative HV model using real-world data from field experiments and applied it to develop a GP-enhanced model predictive control (GP-MPC) strategy. This strategy aims to improve safety in mixed vehicle platoons by integrating uncertainty assessment into distance constraints. Comparative simulation studies with a conventional model predictive control (MPC) approach demonstrated that our GP-MPC strategy ensures more reliable safe distancing and fosters efficient vehicular dynamics, achieving notably higher speeds within the platoon. By incorporating a sparse GP technique in HV modeling and adopting a dynamic GP prediction within the MPC framework, we significantly reduced the computation time of GP-MPC, marking it only 4.6% higher than that of the conventional MPC. This represents a substantial improvement, making the process about 100 times faster than our preliminary work without these approximations. Our findings underscore the effectiveness of learning-based HV modeling in enhancing both safety and operational efficiency in mixed-traffic environments, paving the way for more harmonious AV-HV interactions.
Learning-Based Modeling of Human-Autonomous Vehicle Interaction for Enhancing Safety in Mixed-Vehicle Platooning Control
Mar 16, 2023



As autonomous vehicles (AVs) become more prevalent on public roads, they will inevitably interact with human-driven vehicles (HVs) in mixed traffic scenarios. To ensure safe interactions between AVs and HVs, it is crucial to account for the uncertain behaviors of HVs when developing control strategies for AVs. In this paper, we propose an efficient learning-based modeling approach for HVs that combines a first-principles model with a Gaussian process (GP) learning-based component. The GP model corrects the velocity prediction of the first-principles model and estimates its uncertainty. Utilizing this model, a model predictive control (MPC) strategy, referred to as GP-MPC, was designed to enhance the safe control of a mixed vehicle platoon by integrating the uncertainty assessment into the distance constraint. We compare our GP-MPC strategy with a baseline MPC that uses only the first-principles model in simulation studies. We show that our GP-MPC strategy provides more robust safe distance guarantees and enables more efficient travel behaviors (higher travel speeds) for all vehicles in the mixed platoon. Moreover, by incorporating a sparse GP technique in HV modeling and a dynamic GP prediction in MPC, we achieve an average computation time for GP-MPC at each time step that is only 5% longer than the baseline MPC, which is approximately 100 times faster than our previous work that did not use these approximations. This work demonstrates how learning-based modeling of HVs can enhance safety and efficiency in mixed traffic involving AV-HV interaction.
Gaussian Process Learning-Based Model Predictive Control for Safe Interactions of a Platoon of Autonomous and Human-Driven Vehicles
Nov 09, 2022With the continued integration of autonomous vehicles (AVs) into public roads, a mixed traffic environment with large-scale human-driven vehicles (HVs) and AVs interactions is imminent. In challenging traffic scenarios, such as emergency braking, it is crucial to account for the reactive and uncertain behavior of HVs when developing control strategies for AVs. This paper studies the safe control of a platoon of AVs interacting with a human-driven vehicle in longitudinal car-following scenarios. We first propose the use of a model that combines a first-principles model (nominal model) with a Gaussian process (GP) learning-based component for predicting behaviors of the human-driven vehicle when it interacts with AVs. The modeling accuracy of the proposed method shows a $9\%$ reduction in root mean square error (RMSE) in predicting a HV's velocity compared to the nominal model. Exploiting the properties of this model, we design a model predictive control (MPC) strategy for a platoon of AVs to ensure a safe distance between each vehicle, as well as a (probabilistic) safety of the human-driven car following the platoon. Compared to a baseline MPC that uses only a nominal model for HVs, our method achieves better velocity-tracking performance for the autonomous vehicle platoon and more robust constraint satisfaction control for a platoon of mixed vehicles system. Simulation studies demonstrate a $4.2\%$ decrease in the control cost and an approximate $1m$ increase in the minimum distance between autonomous and human-driven vehicles to better guarantee safety in challenging traffic scenarios.
DEC-LOS-RRT: Decentralized Path Planning for Multi-robot Systems with Line-of-sight Constrained Communication
Mar 04, 2022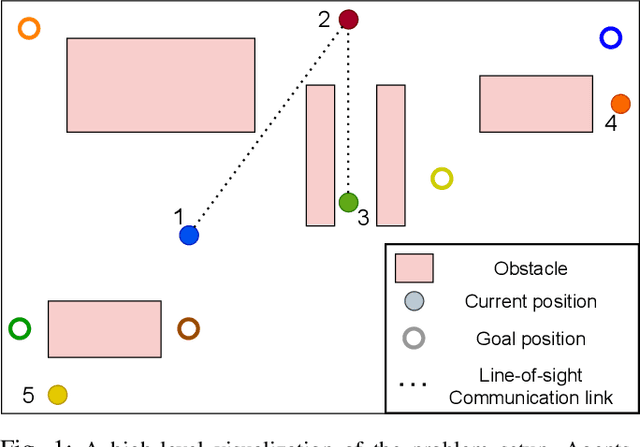
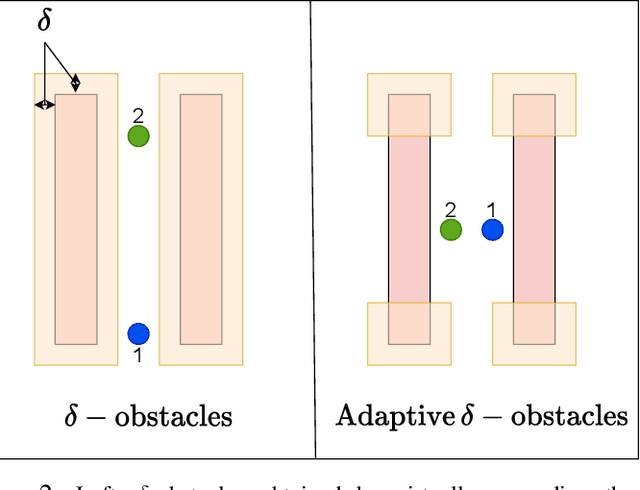
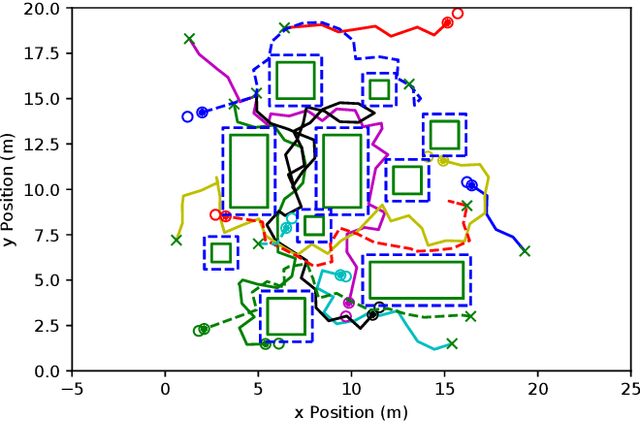
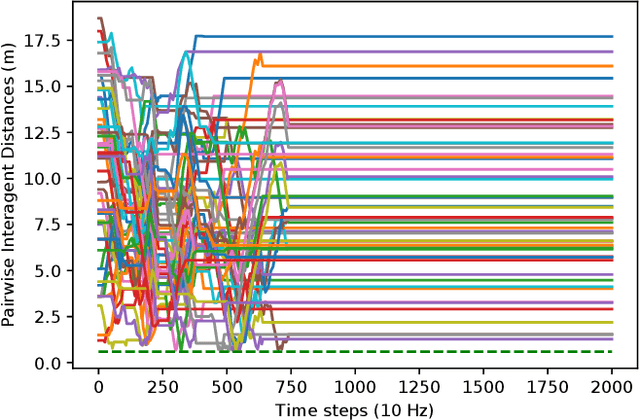
Decentralized planning for multi-agent systems, such as fleets of robots in a search-and-rescue operation, is often constrained by limitations on how agents can communicate with each other. One such limitation is the case when agents can communicate with each other only when they are in line-of-sight (LOS). Developing decentralized planning methods that guarantee safety is difficult in this case, as agents that are occluded from each other might not be able to communicate until it's too late to avoid a safety violation. In this paper, we develop a decentralized planning method that explicitly avoids situations where lack of visibility of other agents would lead to an unsafe situation. Building on top of an existing Rapidly-exploring Random Tree (RRT)-based approach, our method guarantees safety at each iteration. Simulation studies show the effectiveness of our method and compare the degradation in performance with respect to a clairvoyant decentralized planning algorithm where agents can communicate despite not being in LOS of each other.
* 8 pages, 8 figures, Presented at CCTA 2022