 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartially Observable Reference Policy Programming: Solving POMDPs Sans Numerical Optimisation
Jul 16, 2025This paper proposes Partially Observable Reference Policy Programming, a novel anytime online approximate POMDP solver which samples meaningful future histories very deeply while simultaneously forcing a gradual policy update. We provide theoretical guarantees for the algorithm's underlying scheme which say that the performance loss is bounded by the average of the sampling approximation errors rather than the usual maximum, a crucial requirement given the sampling sparsity of online planning. Empirical evaluations on two large-scale problems with dynamically evolving environments -- including a helicopter emergency scenario in the Corsica region requiring approximately 150 planning steps -- corroborate the theoretical results and indicate that our solver considerably outperforms current online benchmarks.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Structured Extraction of Real World Medical Knowledge using LLMs for Summarization and Search
Dec 16, 2024Creation and curation of knowledge graphs can accelerate disease discovery and analysis in real-world data. While disease ontologies aid in biological data annotation, codified categories (SNOMED-CT, ICD10, CPT) may not capture patient condition nuances or rare diseases. Multiple disease definitions across data sources complicate ontology mapping and disease clustering. We propose creating patient knowledge graphs using large language model extraction techniques, allowing data extraction via natural language rather than rigid ontological hierarchies. Our method maps to existing ontologies (MeSH, SNOMED-CT, RxNORM, HPO) to ground extracted entities. Using a large ambulatory care EHR database with 33.6M patients, we demonstrate our method through the patient search for Dravet syndrome, which received ICD10 recognition in October 2020. We describe our construction of patient-specific knowledge graphs and symptom-based patient searches. Using confirmed Dravet syndrome ICD10 codes as ground truth, we employ LLM-based entity extraction to characterize patients in grounded ontologies. We then apply this method to identify Beta-propeller protein-associated neurodegeneration (BPAN) patients, demonstrating real-world discovery where no ground truth exists.
Scaling Long-Horizon Online POMDP Planning via Rapid State Space Sampling
Nov 11, 2024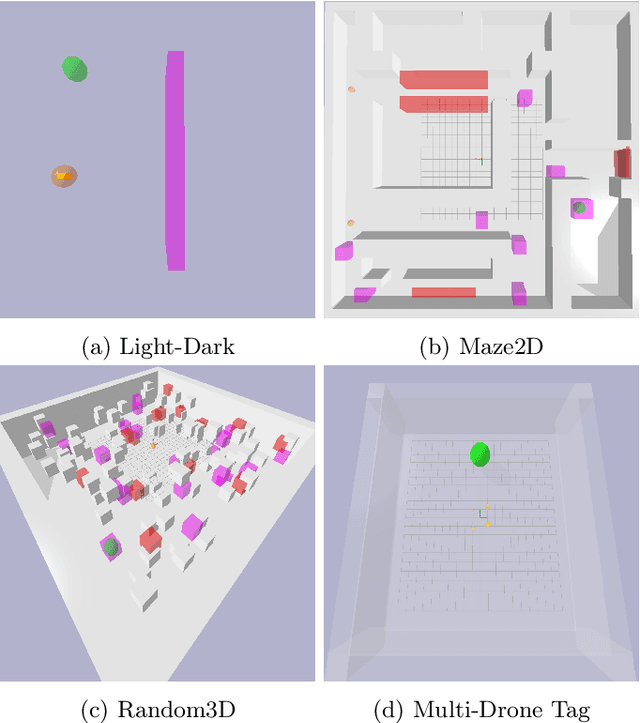
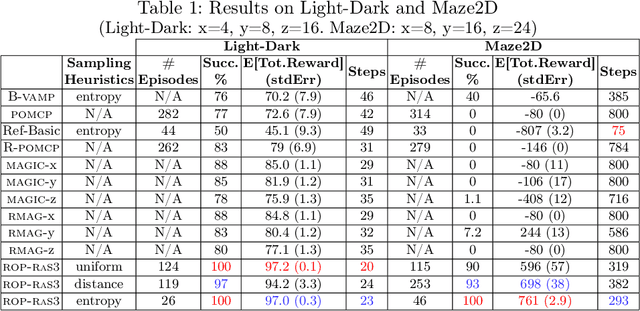
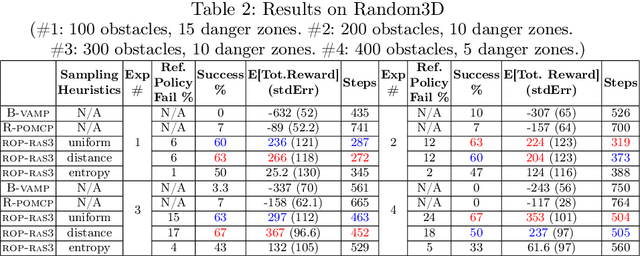
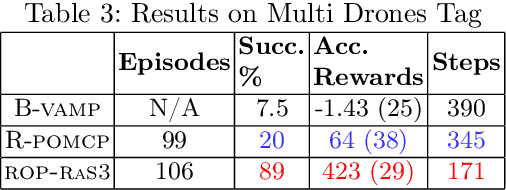
Partially Observable Markov Decision Processes (POMDPs) are a general and principled framework for motion planning under uncertainty. Despite tremendous improvement in the scalability of POMDP solvers, long-horizon POMDPs (e.g., $\geq15$ steps) remain difficult to solve. This paper proposes a new approximate online POMDP solver, called Reference-Based Online POMDP Planning via Rapid State Space Sampling (ROP-RaS3). ROP-RaS3 uses novel extremely fast sampling-based motion planning techniques to sample the state space and generate a diverse set of macro actions online which are then used to bias belief-space sampling and infer high-quality policies without requiring exhaustive enumeration of the action space -- a fundamental constraint for modern online POMDP solvers. ROP-RaS3 is evaluated on various long-horizon POMDPs, including on a problem with a planning horizon of more than 100 steps and a problem with a 15-dimensional state space that requires more than 20 look ahead steps. In all of these problems, ROP-RaS3 substantially outperforms other state-of-the-art methods by up to multiple folds.
Towards Automated Penetration Testing: Introducing LLM Benchmark, Analysis, and Improvements
Oct 22, 2024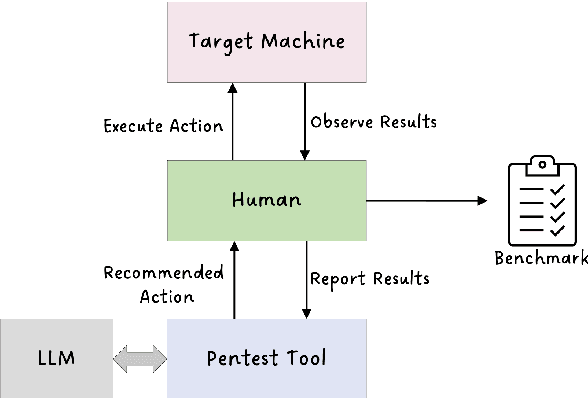
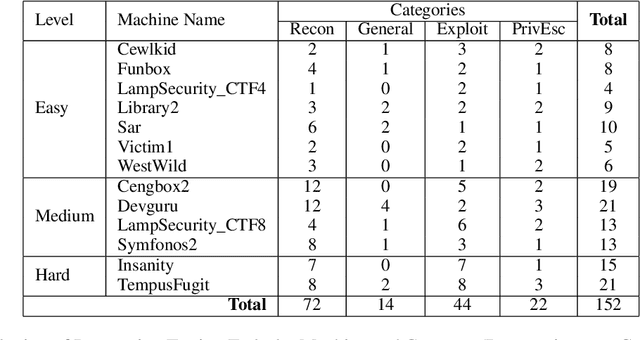
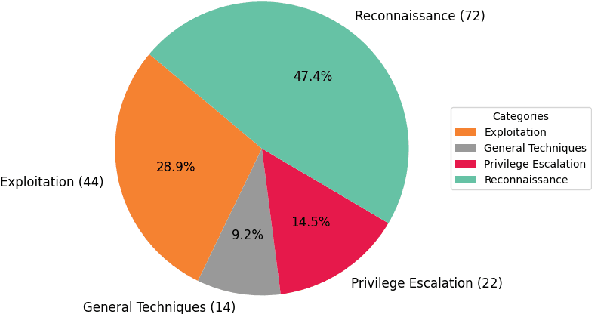
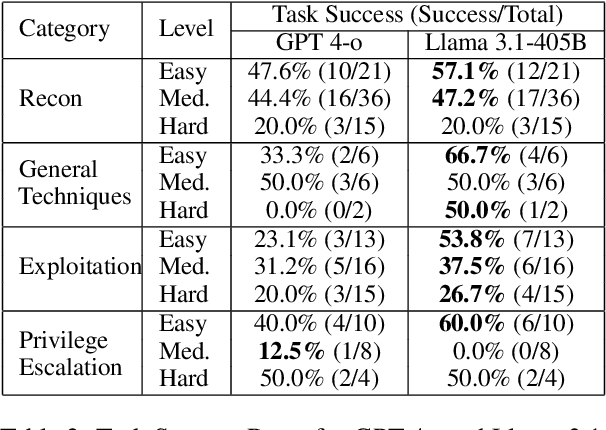
Hacking poses a significant threat to cybersecurity, inflicting billions of dollars in damages annually. To mitigate these risks, ethical hacking, or penetration testing, is employed to identify vulnerabilities in systems and networks. Recent advancements in large language models (LLMs) have shown potential across various domains, including cybersecurity. However, there is currently no comprehensive, open, end-to-end automated penetration testing benchmark to drive progress and evaluate the capabilities of these models in security contexts. This paper introduces a novel open benchmark for LLM-based automated penetration testing, addressing this critical gap. We first evaluate the performance of LLMs, including GPT-4o and Llama 3.1-405B, using the state-of-the-art PentestGPT tool. Our findings reveal that while Llama 3.1 demonstrates an edge over GPT-4o, both models currently fall short of performing fully automated, end-to-end penetration testing. Next, we advance the state-of-the-art and present ablation studies that provide insights into improving the PentestGPT tool. Our research illuminates the challenges LLMs face in each aspect of Pentesting, e.g. enumeration, exploitation, and privilege escalation. This work contributes to the growing body of knowledge on AI-assisted cybersecurity and lays the foundation for future research in automated penetration testing using large language models.
Secure Multiparty Generative AI
Sep 27, 2024



As usage of generative AI tools skyrockets, the amount of sensitive information being exposed to these models and centralized model providers is alarming. For example, confidential source code from Samsung suffered a data leak as the text prompt to ChatGPT encountered data leakage. An increasing number of companies are restricting the use of LLMs (Apple, Verizon, JPMorgan Chase, etc.) due to data leakage or confidentiality issues. Also, an increasing number of centralized generative model providers are restricting, filtering, aligning, or censoring what can be used. Midjourney and RunwayML, two of the major image generation platforms, restrict the prompts to their system via prompt filtering. Certain political figures are restricted from image generation, as well as words associated with women's health care, rights, and abortion. In our research, we present a secure and private methodology for generative artificial intelligence that does not expose sensitive data or models to third-party AI providers. Our work modifies the key building block of modern generative AI algorithms, e.g. the transformer, and introduces confidential and verifiable multiparty computations in a decentralized network to maintain the 1) privacy of the user input and obfuscation to the output of the model, and 2) introduce privacy to the model itself. Additionally, the sharding process reduces the computational burden on any one node, enabling the distribution of resources of large generative AI processes across multiple, smaller nodes. We show that as long as there exists one honest node in the decentralized computation, security is maintained. We also show that the inference process will still succeed if only a majority of the nodes in the computation are successful. Thus, our method offers both secure and verifiable computation in a decentralized network.
Evaluating the Performance and Robustness of LLMs in Materials Science Q&A and Property Predictions
Sep 22, 2024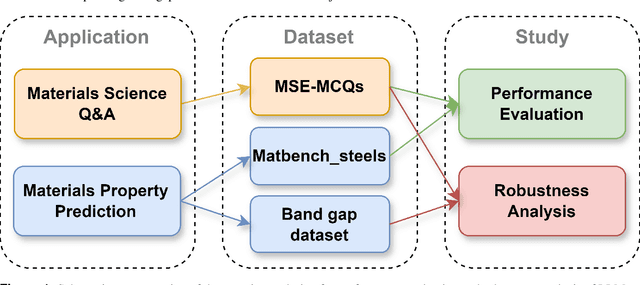

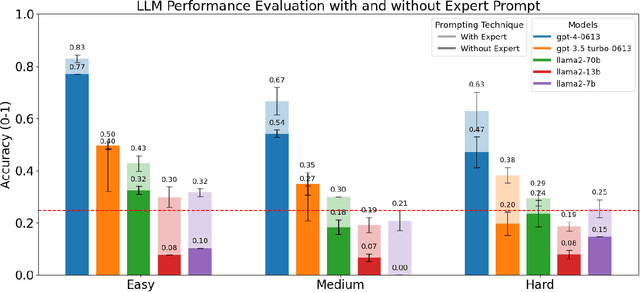
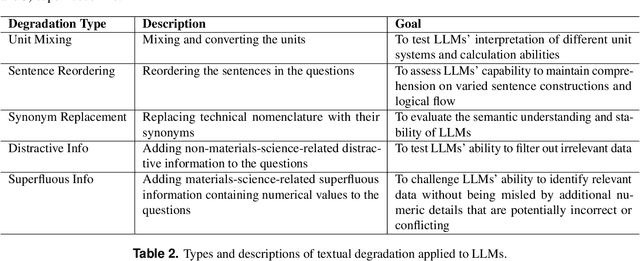
Large Language Models (LLMs) have the potential to revolutionize scientific research, yet their robustness and reliability in domain-specific applications remain insufficiently explored. This study conducts a comprehensive evaluation and robustness analysis of LLMs within the field of materials science, focusing on domain-specific question answering and materials property prediction. Three distinct datasets are used in this study: 1) a set of multiple-choice questions from undergraduate-level materials science courses, 2) a dataset including various steel compositions and yield strengths, and 3) a band gap dataset, containing textual descriptions of material crystal structures and band gap values. The performance of LLMs is assessed using various prompting strategies, including zero-shot chain-of-thought, expert prompting, and few-shot in-context learning. The robustness of these models is tested against various forms of 'noise', ranging from realistic disturbances to intentionally adversarial manipulations, to evaluate their resilience and reliability under real-world conditions. Additionally, the study uncovers unique phenomena of LLMs during predictive tasks, such as mode collapse behavior when the proximity of prompt examples is altered and performance enhancement from train/test mismatch. The findings aim to provide informed skepticism for the broad use of LLMs in materials science and to inspire advancements that enhance their robustness and reliability for practical applications.
The Impact of an XAI-Augmented Approach on Binary Classification with Scarce Data
Jul 01, 2024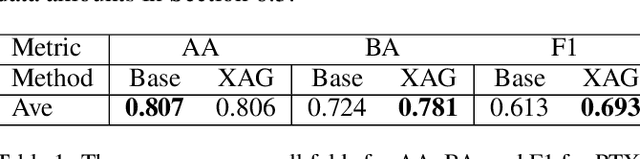
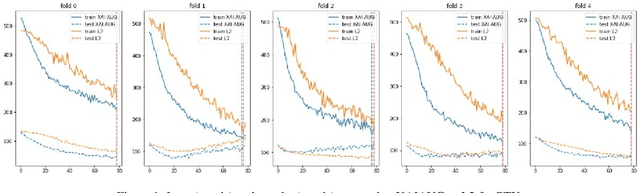

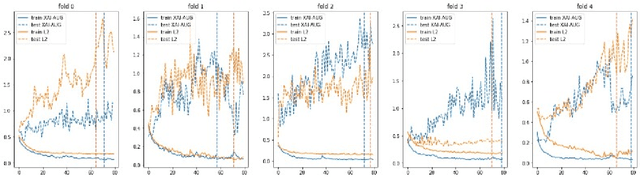
Point-of-Care Ultrasound (POCUS) is the practice of clinicians conducting and interpreting ultrasound scans right at the patient's bedside. However, the expertise needed to interpret these images is considerable and may not always be present in emergency situations. This reality makes algorithms such as machine learning classifiers extremely valuable to augment human decisions. POCUS devices are becoming available at a reasonable cost in the size of a mobile phone. The challenge of turning POCUS devices into life-saving tools is that interpretation of ultrasound images requires specialist training and experience. Unfortunately, the difficulty to obtain positive training images represents an important obstacle to building efficient and accurate classifiers. Hence, the problem we try to investigate is how to explore strategies to increase accuracy of classifiers trained with scarce data. We hypothesize that training with a few data instances may not suffice for classifiers to generalize causing them to overfit. Our approach uses an Explainable AI-Augmented approach to help the algorithm learn more from less and potentially help the classifier better generalize.
E3: Ensemble of Expert Embedders for Adapting Synthetic Image Detectors to New Generators Using Limited Data
Apr 12, 2024As generative AI progresses rapidly, new synthetic image generators continue to emerge at a swift pace. Traditional detection methods face two main challenges in adapting to these generators: the forensic traces of synthetic images from new techniques can vastly differ from those learned during training, and access to data for these new generators is often limited. To address these issues, we introduce the Ensemble of Expert Embedders (E3), a novel continual learning framework for updating synthetic image detectors. E3 enables the accurate detection of images from newly emerged generators using minimal training data. Our approach does this by first employing transfer learning to develop a suite of expert embedders, each specializing in the forensic traces of a specific generator. Then, all embeddings are jointly analyzed by an Expert Knowledge Fusion Network to produce accurate and reliable detection decisions. Our experiments demonstrate that E3 outperforms existing continual learning methods, including those developed specifically for synthetic image detection.
Interpretable Models for Detecting and Monitoring Elevated Intracranial Pressure
Mar 04, 2024


Detecting elevated intracranial pressure (ICP) is crucial in diagnosing and managing various neurological conditions. These fluctuations in pressure are transmitted to the optic nerve sheath (ONS), resulting in changes to its diameter, which can then be detected using ultrasound imaging devices. However, interpreting sonographic images of the ONS can be challenging. In this work, we propose two systems that actively monitor the ONS diameter throughout an ultrasound video and make a final prediction as to whether ICP is elevated. To construct our systems, we leverage subject matter expert (SME) guidance, structuring our processing pipeline according to their collection procedure, while also prioritizing interpretability and computational efficiency. We conduct a number of experiments, demonstrating that our proposed systems are able to outperform various baselines. One of our SMEs then manually validates our top system's performance, lending further credibility to our approach while demonstrating its potential utility in a clinical setting.