 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Penetration Testing: Introducing LLM Benchmark, Analysis, and Improvements
Oct 22, 2024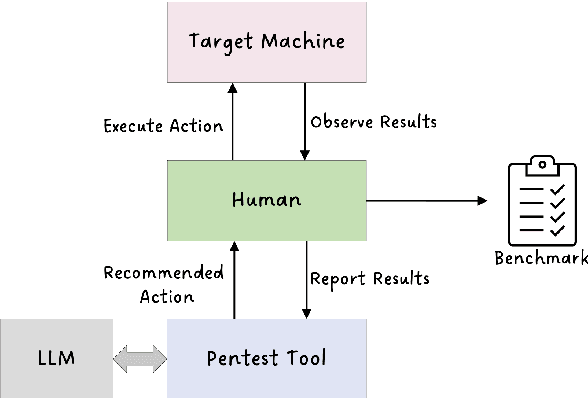
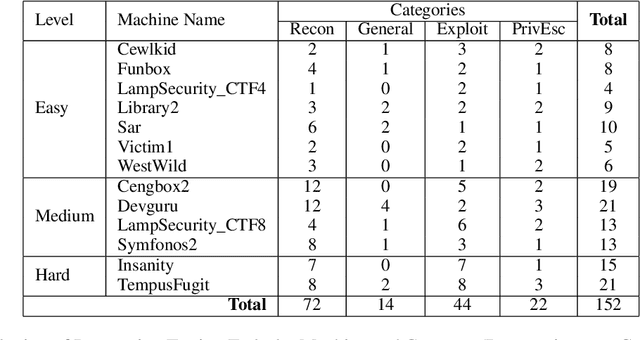
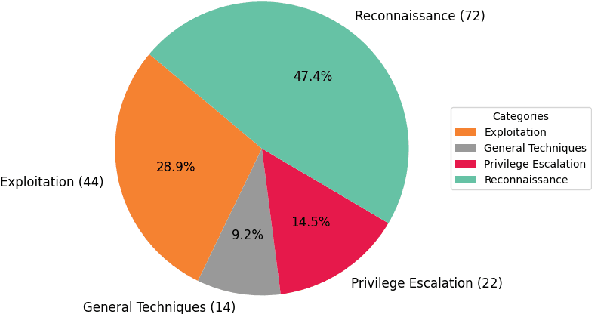
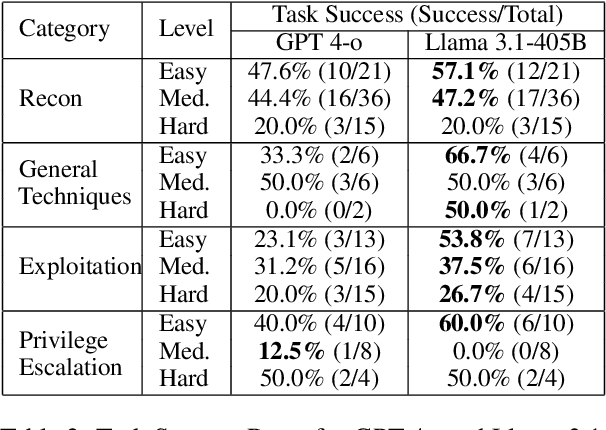
Hacking poses a significant threat to cybersecurity, inflicting billions of dollars in damages annually. To mitigate these risks, ethical hacking, or penetration testing, is employed to identify vulnerabilities in systems and networks. Recent advancements in large language models (LLMs) have shown potential across various domains, including cybersecurity. However, there is currently no comprehensive, open, end-to-end automated penetration testing benchmark to drive progress and evaluate the capabilities of these models in security contexts. This paper introduces a novel open benchmark for LLM-based automated penetration testing, addressing this critical gap. We first evaluate the performance of LLMs, including GPT-4o and Llama 3.1-405B, using the state-of-the-art PentestGPT tool. Our findings reveal that while Llama 3.1 demonstrates an edge over GPT-4o, both models currently fall short of performing fully automated, end-to-end penetration testing. Next, we advance the state-of-the-art and present ablation studies that provide insights into improving the PentestGPT tool. Our research illuminates the challenges LLMs face in each aspect of Pentesting, e.g. enumeration, exploitation, and privilege escalation. This work contributes to the growing body of knowledge on AI-assisted cybersecurity and lays the foundation for future research in automated penetration testing using large language models.