 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Beyond Redundancy: Task Complexity's Role in Vision Token Specialization in VLLMs
Feb 06, 2026Vision capabilities in vision large language models (VLLMs) have consistently lagged behind their linguistic capabilities. In particular, numerous benchmark studies have demonstrated that VLLMs struggle when fine-grained visual information or spatial reasoning is required. However, we do not yet understand exactly why VLLMs struggle so much with these tasks relative to others. Some works have focused on visual redundancy as an explanation, where high-level visual information is uniformly spread across numerous tokens and specific, fine-grained visual information is discarded. In this work, we investigate this premise in greater detail, seeking to better understand exactly how various types of visual information are processed by the model and what types of visual information are discarded. To do so, we introduce a simple synthetic benchmark dataset that is specifically constructed to probe various visual features, along with a set of metrics for measuring visual redundancy, allowing us to better understand the nuances of their relationship. Then, we explore fine-tuning VLLMs on a number of complex visual tasks to better understand how redundancy and compression change based upon the complexity of the data that a model is trained on. We find that there is a connection between task complexity and visual compression, implying that having a sufficient ratio of high complexity visual data is crucial for altering the way that VLLMs distribute their visual representation and consequently improving their performance on complex visual tasks. We hope that this work will provide valuable insights for training the next generation of VLLMs.
FMG-Det: Foundation Model Guided Robust Object Detection
May 29, 2025

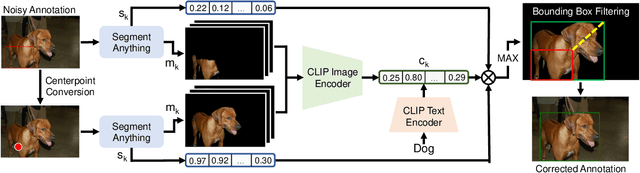

Collecting high quality data for object detection tasks is challenging due to the inherent subjectivity in labeling the boundaries of an object. This makes it difficult to not only collect consistent annotations across a dataset but also to validate them, as no two annotators are likely to label the same object using the exact same coordinates. These challenges are further compounded when object boundaries are partially visible or blurred, which can be the case in many domains. Training on noisy annotations significantly degrades detector performance, rendering them unusable, particularly in few-shot settings, where just a few corrupted annotations can impact model performance. In this work, we propose FMG-Det, a simple, efficient methodology for training models with noisy annotations. More specifically, we propose combining a multiple instance learning (MIL) framework with a pre-processing pipeline that leverages powerful foundation models to correct labels prior to training. This pre-processing pipeline, along with slight modifications to the detector head, results in state-of-the-art performance across a number of datasets, for both standard and few-shot scenarios, while being much simpler and more efficient than other approaches.
Foundation Models for Remote Sensing: An Analysis of MLLMs for Object Localization
Apr 14, 2025


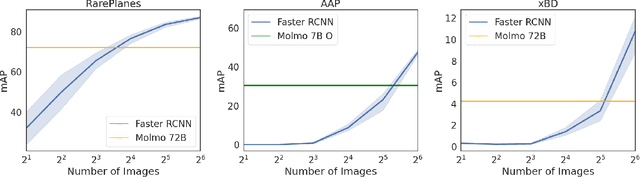
Multimodal large language models (MLLMs) have altered the landscape of computer vision, obtaining impressive results across a wide range of tasks, especially in zero-shot settings. Unfortunately, their strong performance does not always transfer to out-of-distribution domains, such as earth observation (EO) imagery. Prior work has demonstrated that MLLMs excel at some EO tasks, such as image captioning and scene understanding, while failing at tasks that require more fine-grained spatial reasoning, such as object localization. However, MLLMs are advancing rapidly and insights quickly become out-dated. In this work, we analyze more recent MLLMs that have been explicitly trained to include fine-grained spatial reasoning capabilities, benchmarking them on EO object localization tasks. We demonstrate that these models are performant in certain settings, making them well suited for zero-shot scenarios. Additionally, we provide a detailed discussion focused on prompt selection, ground sample distance (GSD) optimization, and analyzing failure cases. We hope that this work will prove valuable as others evaluate whether an MLLM is well suited for a given EO localization task and how to optimize it.
Event-to-Video Conversion for Overhead Object Detection
Feb 09, 2024
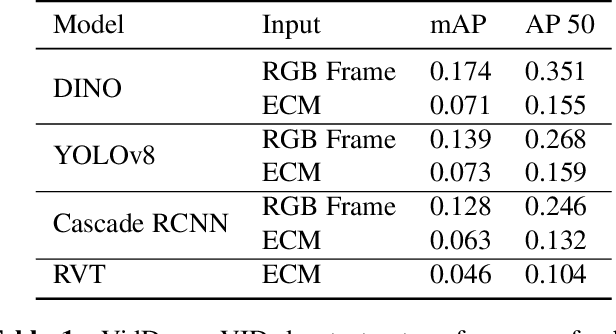
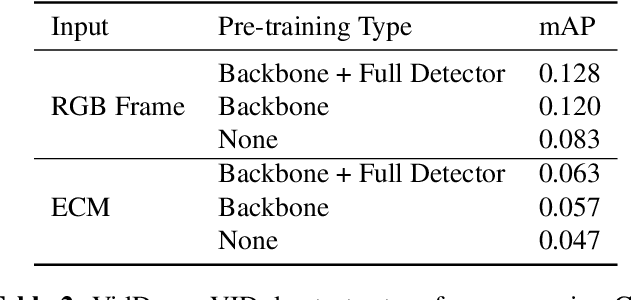
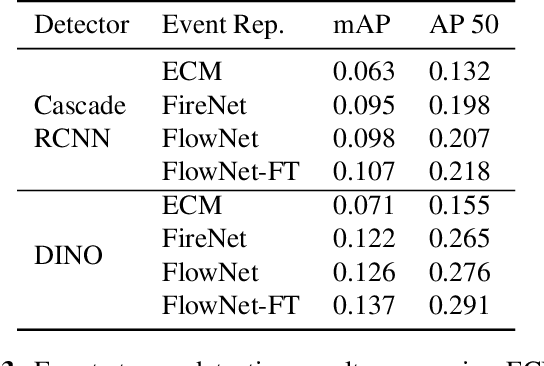
Collecting overhead imagery using an event camera is desirable due to the energy efficiency of the image sensor compared to standard cameras. However, event cameras complicate downstream image processing, especially for complex tasks such as object detection. In this paper, we investigate the viability of event streams for overhead object detection. We demonstrate that across a number of standard modeling approaches, there is a significant gap in performance between dense event representations and corresponding RGB frames. We establish that this gap is, in part, due to a lack of overlap between the event representations and the pre-training data used to initialize the weights of the object detectors. Then, we apply event-to-video conversion models that convert event streams into gray-scale video to close this gap. We demonstrate that this approach results in a large performance increase, outperforming even event-specific object detection techniques on our overhead target task. These results suggest that better alignment between event representations and existing large pre-trained models may result in greater short-term performance gains compared to end-to-end event-specific architectural improvements.
Implementing and Benchmarking the Locally Competitive Algorithm on the Loihi 2 Neuromorphic Processor
Jul 25, 2023Neuromorphic processors have garnered considerable interest in recent years for their potential in energy-efficient and high-speed computing. The Locally Competitive Algorithm (LCA) has been utilized for power efficient sparse coding on neuromorphic processors, including the first Loihi processor. With the Loihi 2 processor enabling custom neuron models and graded spike communication, more complex implementations of LCA are possible. We present a new implementation of LCA designed for the Loihi 2 processor and perform an initial set of benchmarks comparing it to LCA on CPU and GPU devices. In these experiments LCA on Loihi 2 is orders of magnitude more efficient and faster for large sparsity penalties, while maintaining similar reconstruction quality. We find this performance improvement increases as the LCA parameters are tuned towards greater representation sparsity. Our study highlights the potential of neuromorphic processors, particularly Loihi 2, in enabling intelligent, autonomous, real-time processing on small robots, satellites where there are strict SWaP (small, lightweight, and low power) requirements. By demonstrating the superior performance of LCA on Loihi 2 compared to conventional computing device, our study suggests that Loihi 2 could be a valuable tool in advancing these types of applications. Overall, our study highlights the potential of neuromorphic processors for efficient and accurate data processing on resource-constrained devices.
ColMix -- A Simple Data Augmentation Framework to Improve Object Detector Performance and Robustness in Aerial Images
May 22, 2023In the last decade, Convolutional Neural Network (CNN) and transformer based object detectors have achieved high performance on a large variety of datasets. Though the majority of detection literature has developed this capability on datasets such as MS COCO, these detectors have still proven effective for remote sensing applications. Challenges in this particular domain, such as small numbers of annotated objects and low object density, hinder overall performance. In this work, we present a novel augmentation method, called collage pasting, for increasing the object density without a need for segmentation masks, thereby improving the detector performance. We demonstrate that collage pasting improves precision and recall beyond related methods, such as mosaic augmentation, and enables greater control of object density. However, we find that collage pasting is vulnerable to certain out-of-distribution shifts, such as image corruptions. To address this, we introduce two simple approaches for combining collage pasting with PixMix augmentation method, and refer to our combined techniques as ColMix. Through extensive experiments, we show that employing ColMix results in detectors with superior performance on aerial imagery datasets and robust to various corruptions.
Universal Fourier Attack for Time Series
Sep 02, 2022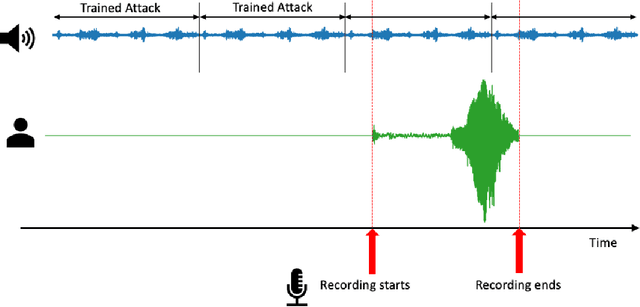
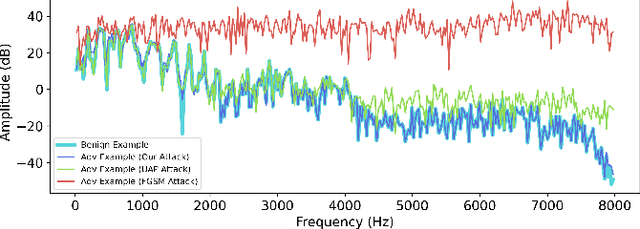
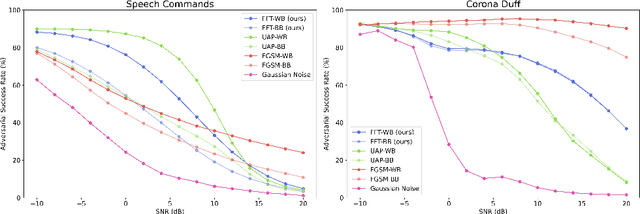
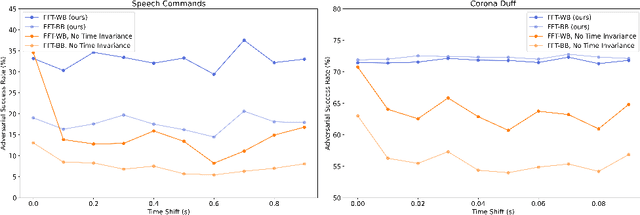
A wide variety of adversarial attacks have been proposed and explored using image and audio data. These attacks are notoriously easy to generate digitally when the attacker can directly manipulate the input to a model, but are much more difficult to implement in the real-world. In this paper we present a universal, time invariant attack for general time series data such that the attack has a frequency spectrum primarily composed of the frequencies present in the original data. The universality of the attack makes it fast and easy to implement as no computation is required to add it to an input, while time invariance is useful for real-world deployment. Additionally, the frequency constraint ensures the attack can withstand filtering. We demonstrate the effectiveness of the attack in two different domains, speech recognition and unintended radiated emission, and show that the attack is robust against common transform-and-compare defense pipelines.
Dictionary Learning with Accumulator Neurons
May 30, 2022
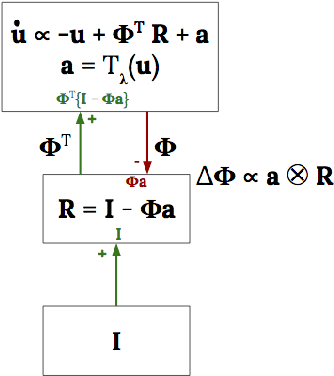
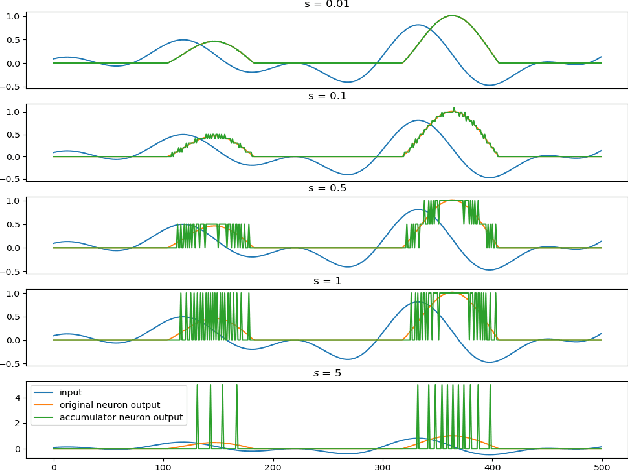

The Locally Competitive Algorithm (LCA) uses local competition between non-spiking leaky integrator neurons to infer sparse representations, allowing for potentially real-time execution on massively parallel neuromorphic architectures such as Intel's Loihi processor. Here, we focus on the problem of inferring sparse representations from streaming video using dictionaries of spatiotemporal features optimized in an unsupervised manner for sparse reconstruction. Non-spiking LCA has previously been used to achieve unsupervised learning of spatiotemporal dictionaries composed of convolutional kernels from raw, unlabeled video. We demonstrate how unsupervised dictionary learning with spiking LCA (\hbox{S-LCA}) can be efficiently implemented using accumulator neurons, which combine a conventional leaky-integrate-and-fire (\hbox{LIF}) spike generator with an additional state variable that is used to minimize the difference between the integrated input and the spiking output. We demonstrate dictionary learning across a wide range of dynamical regimes, from graded to intermittent spiking, for inferring sparse representations of both static images drawn from the CIFAR database as well as video frames captured from a DVS camera. On a classification task that requires identification of the suite from a deck of cards being rapidly flipped through as viewed by a DVS camera, we find essentially no degradation in performance as the LCA model used to infer sparse spatiotemporal representations migrates from graded to spiking. We conclude that accumulator neurons are likely to provide a powerful enabling component of future neuromorphic hardware for implementing online unsupervised learning of spatiotemporal dictionaries optimized for sparse reconstruction of streaming video from event based DVS cameras.
Digital Signal Processing Using Deep Neural Networks
Sep 21, 2021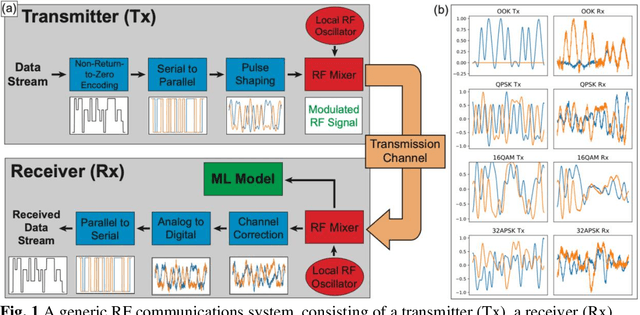

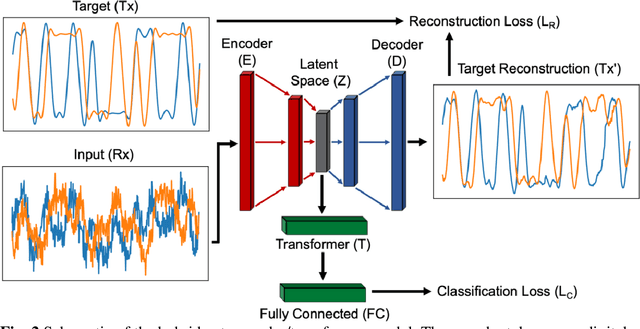

Currently there is great interest in the utility of deep neural networks (DNNs) for the physical layer of radio frequency (RF) communications. In this manuscript, we describe a custom DNN specially designed to solve problems in the RF domain. Our model leverages the mechanisms of feature extraction and attention through the combination of an autoencoder convolutional network with a transformer network, to accomplish several important communications network and digital signals processing (DSP) tasks. We also present a new open dataset and physical data augmentation model that enables training of DNNs that can perform automatic modulation classification, infer and correct transmission channel effects, and directly demodulate baseband RF signals.
Image Compression: Sparse Coding vs. Bottleneck Autoencoders
Jan 23, 2018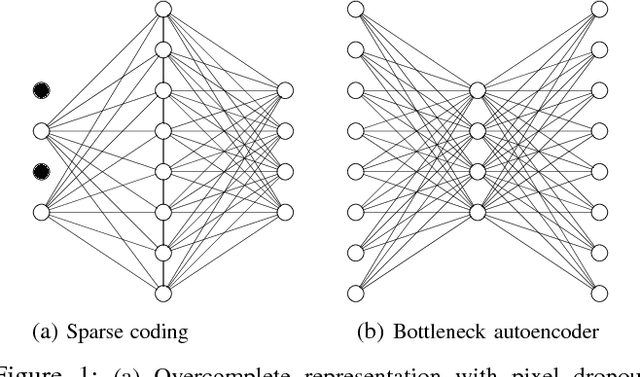
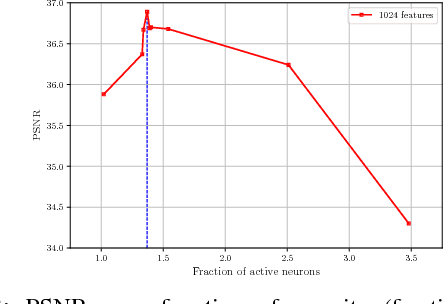


Bottleneck autoencoders have been actively researched as a solution to image compression tasks. However, we observed that bottleneck autoencoders produce subjectively low quality reconstructed images. In this work, we explore the ability of sparse coding to improve reconstructed image quality for the same degree of compression. We observe that sparse image compression produces visually superior reconstructed images and yields higher values of pixel-wise measures of reconstruction quality (PSNR and SSIM) compared to bottleneck autoencoders. % In addition, we find that using alternative metrics that correlate better with human perception, such as feature perceptual loss and the classification accuracy, sparse image compression scores up to 18.06\% and 2.7\% higher, respectively, compared to bottleneck autoencoders. Although computationally much more intensive, we find that sparse coding is otherwise superior to bottleneck autoencoders for the same degree of compression.