 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Learning of Attractors for Neuromorphic Computing with Wien Bridge Oscillator Networks
Dec 16, 2025


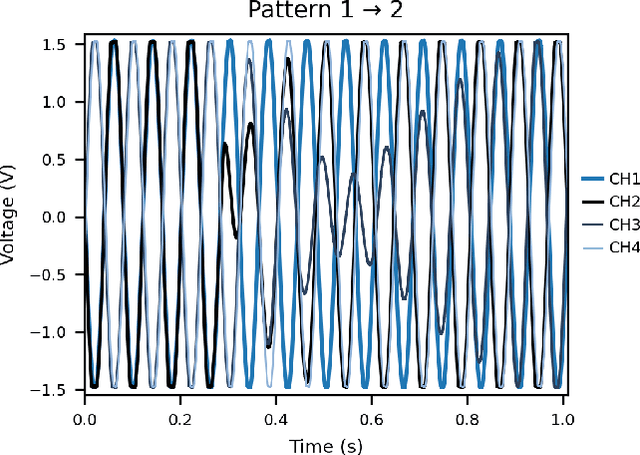
We present an oscillatory neuromorphic primitive implemented with networks of coupled Wien bridge oscillators and tunable resistive couplings. Phase relationships between oscillators encode patterns, and a local Hebbian learning rule continuously adapts the couplings, allowing learning and recall to emerge from the same ongoing analog dynamics rather than from separate training and inference phases. Using a Kuramoto-style phase model with an effective energy function, we show that learned phase patterns form attractor states and validate this behavior in simulation and hardware. We further realize a 2-4-2 architecture with a hidden layer of oscillators, whose bipartite visible-hidden coupling allows multiple internal configurations to produce the same visible phase states. When inputs are switched, transient spikes in energy followed by relaxation indicate how the network can reduce surprise by reshaping its energy landscape. These results support coupled oscillator circuits as a hardware platform for energy-based neuromorphic computing with autonomous, continuous learning.
Demonstrating the Suitability of Neuromorphic, Event-Based, Dynamic Vision Sensors for In Process Monitoring of Metallic Additive Manufacturing and Welding
Nov 20, 2024We demonstrate the suitability of high dynamic range, high-speed, neuromorphic event-based, dynamic vision sensors for metallic additive manufacturing and welding for in-process monitoring applications. In-process monitoring to enable quality control of mission critical components produced using metallic additive manufacturing is of high interest. However, the extreme light environment and high speed dynamics of metallic melt pools have made this a difficult environment in which to make measurements. Event-based sensing is an alternative measurement paradigm where data is only transmitted/recorded when a measured quantity exceeds a threshold resolution. The result is that event-based sensors consume less power and less memory/bandwidth, and they operate across a wide range of timescales and dynamic ranges. Event-driven driven imagers stand out from conventional imager technology in that they have a very high dynamic range of approximately 120 dB. Conventional 8 bit imagers only have a dynamic range of about 48 dB. This high dynamic range makes them a good candidate for monitoring manufacturing processes that feature high intensity light sources/generation such as metallic additive manufacturing and welding. In addition event based imagers are able to capture data at timescales on the order of 100 {\mu}s, which makes them attractive to capturing fast dynamics in a metallic melt pool. In this work we demonstrate that event-driven imagers have been shown to be able to observe tungsten inert gas (TIG) and laser welding melt pools. The results of this effort suggest that with additional engineering effort, neuromorphic event imagers should be capable of 3D geometry measurements of the melt pool, and anomaly detection/classification/prediction.
* This work is a derivative work of a conference proceedings paper submitted to the International Modal Analysis Conference 2024, and is subject to some copyright restrictions associated with the Society of Experimental Mechanics. A variation of this paper is also published in the Weapons Engineering Symposium and Journal (WESJ) which is not publically accessible
Comparing Quantum Annealing and Spiking Neuromorphic Computing for Sampling Binary Sparse Coding QUBO Problems
May 30, 2024We consider the problem of computing a sparse binary representation of an image. To be precise, given an image and an overcomplete, non-orthonormal basis, we aim to find a sparse binary vector indicating the minimal set of basis vectors that when added together best reconstruct the given input. We formulate this problem with an $L_2$ loss on the reconstruction error, and an $L_0$ (or, equivalently, an $L_1$) loss on the binary vector enforcing sparsity. This yields a quadratic binary optimization problem (QUBO), whose optimal solution(s) in general is NP-hard to find. The method of unsupervised and unnormalized dictionary feature learning for a desired sparsity level to best match the data is presented. Next, we solve the sparse representation QUBO by implementing it both on a D-Wave quantum annealer with Pegasus chip connectivity via minor embedding, as well as on the Intel Loihi 2 spiking neuromorphic processor. On the quantum annealer, we sample from the sparse representation QUBO using parallel quantum annealing combined with quantum evolution Monte Carlo, also known as iterated reverse annealing. On Loihi 2, we use a stochastic winner take all network of neurons. The solutions are benchmarked against simulated annealing, a classical heuristic, and the optimal solutions are computed using CPLEX. Iterated reverse quantum annealing performs similarly to simulated annealing, although simulated annealing is always able to sample the optimal solution whereas quantum annealing was not always able to. The Loihi 2 solutions that are sampled are on average more sparse than the solutions from any of the other methods. Loihi 2 outperforms a D-Wave quantum annealer standard linear-schedule anneal, while iterated reverse quantum annealing performs much better than both unmodified linear-schedule quantum annealing and iterated warm starting on Loihi 2.
How Robust Are Energy-Based Models Trained With Equilibrium Propagation?
Jan 21, 2024Deep neural networks (DNNs) are easily fooled by adversarial perturbations that are imperceptible to humans. Adversarial training, a process where adversarial examples are added to the training set, is the current state-of-the-art defense against adversarial attacks, but it lowers the model's accuracy on clean inputs, is computationally expensive, and offers less robustness to natural noise. In contrast, energy-based models (EBMs), which were designed for efficient implementation in neuromorphic hardware and physical systems, incorporate feedback connections from each layer to the previous layer, yielding a recurrent, deep-attractor architecture which we hypothesize should make them naturally robust. Our work is the first to explore the robustness of EBMs to both natural corruptions and adversarial attacks, which we do using the CIFAR-10 and CIFAR-100 datasets. We demonstrate that EBMs are more robust than transformers and display comparable robustness to adversarially-trained DNNs on gradient-based (white-box) attacks, query-based (black-box) attacks, and natural perturbations without sacrificing clean accuracy, and without the need for adversarial training or additional training techniques.
On visual self-supervision and its effect on model robustness
Dec 08, 2021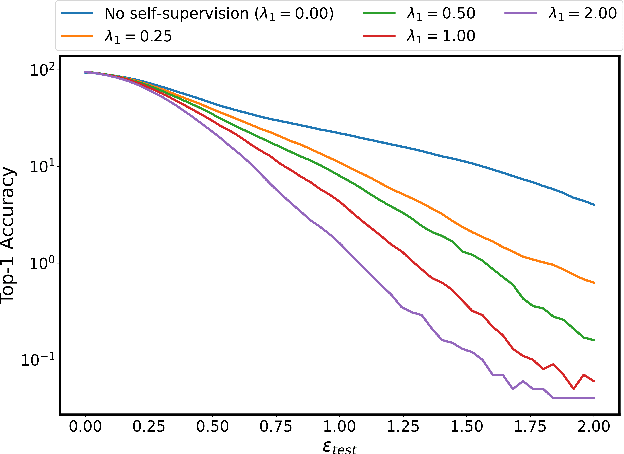

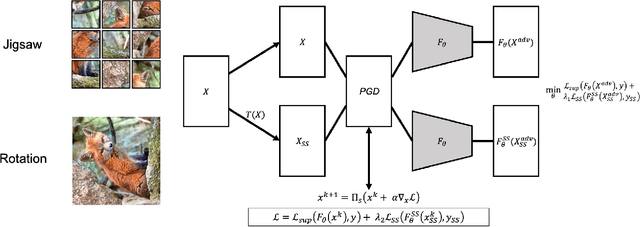

Recent self-supervision methods have found success in learning feature representations that could rival ones from full supervision, and have been shown to be beneficial to the model in several ways: for example improving models robustness and out-of-distribution detection. In our paper, we conduct an empirical study to understand more precisely in what way can self-supervised learning - as a pre-training technique or part of adversarial training - affects model robustness to $l_2$ and $l_{\infty}$ adversarial perturbations and natural image corruptions. Self-supervision can indeed improve model robustness, however it turns out the devil is in the details. If one simply adds self-supervision loss in tandem with adversarial training, then one sees improvement in accuracy of the model when evaluated with adversarial perturbations smaller or comparable to the value of $\epsilon_{train}$ that the robust model is trained with. However, if one observes the accuracy for $\epsilon_{test} \ge \epsilon_{train}$, the model accuracy drops. In fact, the larger the weight of the supervision loss, the larger the drop in performance, i.e. harming the robustness of the model. We identify primary ways in which self-supervision can be added to adversarial training, and observe that using a self-supervised loss to optimize both network parameters and find adversarial examples leads to the strongest improvement in model robustness, as this can be viewed as a form of ensemble adversarial training. Although self-supervised pre-training yields benefits in improving adversarial training as compared to random weight initialization, we observe no benefit in model robustness or accuracy if self-supervision is incorporated into adversarial training.
Deep Sparse Coding for Invariant Multimodal Halle Berry Neurons
Jun 12, 2018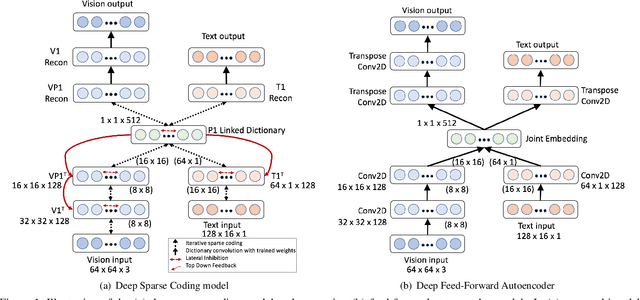
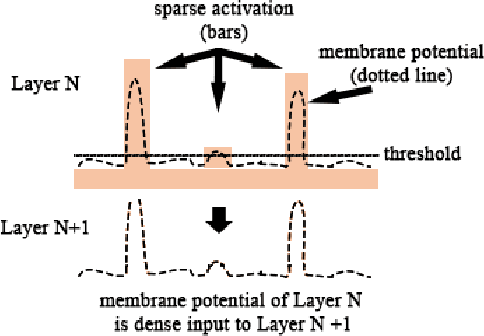
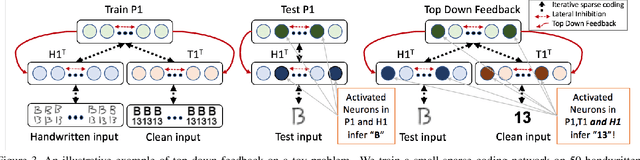
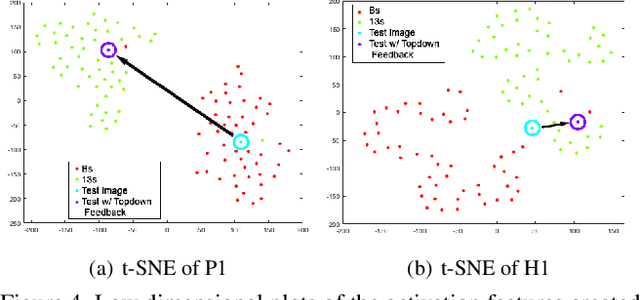
Deep feed-forward convolutional neural networks (CNNs) have become ubiquitous in virtually all machine learning and computer vision challenges; however, advancements in CNNs have arguably reached an engineering saturation point where incremental novelty results in minor performance gains. Although there is evidence that object classification has reached human levels on narrowly defined tasks, for general applications, the biological visual system is far superior to that of any computer. Research reveals there are numerous missing components in feed-forward deep neural networks that are critical in mammalian vision. The brain does not work solely in a feed-forward fashion, but rather all of the neurons are in competition with each other; neurons are integrating information in a bottom up and top down fashion and incorporating expectation and feedback in the modeling process. Furthermore, our visual cortex is working in tandem with our parietal lobe, integrating sensory information from various modalities. In our work, we sought to improve upon the standard feed-forward deep learning model by augmenting them with biologically inspired concepts of sparsity, top-down feedback, and lateral inhibition. We define our model as a sparse coding problem using hierarchical layers. We solve the sparse coding problem with an additional top-down feedback error driving the dynamics of the neural network. While building and observing the behavior of our model, we were fascinated that multimodal, invariant neurons naturally emerged that mimicked, "Halle Berry neurons" found in the human brain. Furthermore, our sparse representation of multimodal signals demonstrates qualitative and quantitative superiority to the standard feed-forward joint embedding in common vision and machine learning tasks.
Efficient Distributed Semi-Supervised Learning using Stochastic Regularization over Affinity Graphs
May 30, 2018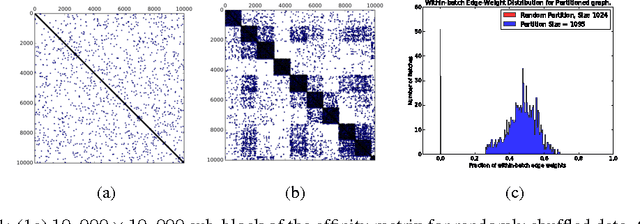
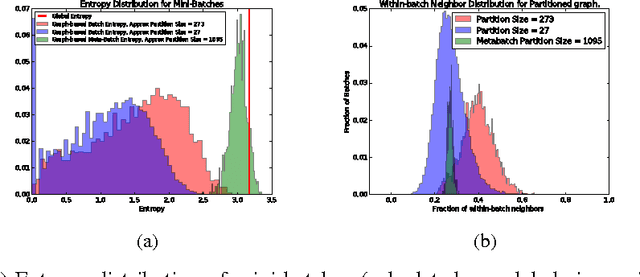

We describe a computationally efficient, stochastic graph-regularization technique that can be utilized for the semi-supervised training of deep neural networks in a parallel or distributed setting. We utilize a technique, first described in [13] for the construction of mini-batches for stochastic gradient descent (SGD) based on synthesized partitions of an affinity graph that are consistent with the graph structure, but also preserve enough stochasticity for convergence of SGD to good local minima. We show how our technique allows a graph-based semi-supervised loss function to be decomposed into a sum over objectives, facilitating data parallelism for scalable training of machine learning models. Empirical results indicate that our method significantly improves classification accuracy compared to the fully-supervised case when the fraction of labeled data is low, and in the parallel case, achieves significant speed-up in terms of wall-clock time to convergence. We show the results for both sequential and distributed-memory semi-supervised DNN training on a speech corpus.
Image Compression: Sparse Coding vs. Bottleneck Autoencoders
Jan 23, 2018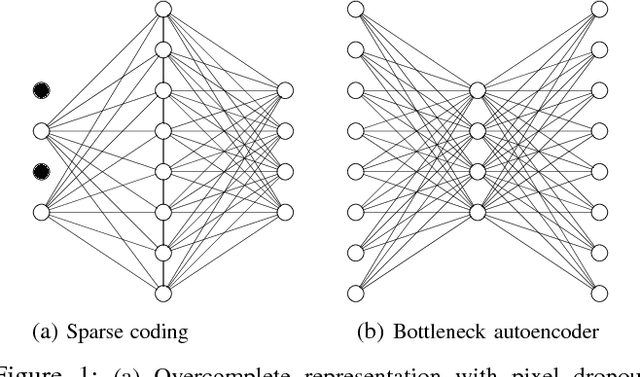
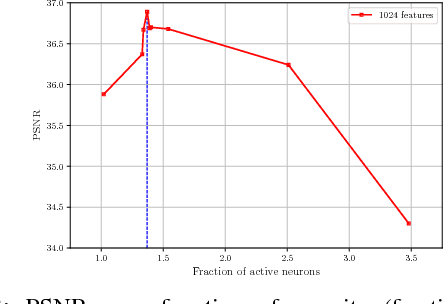


Bottleneck autoencoders have been actively researched as a solution to image compression tasks. However, we observed that bottleneck autoencoders produce subjectively low quality reconstructed images. In this work, we explore the ability of sparse coding to improve reconstructed image quality for the same degree of compression. We observe that sparse image compression produces visually superior reconstructed images and yields higher values of pixel-wise measures of reconstruction quality (PSNR and SSIM) compared to bottleneck autoencoders. % In addition, we find that using alternative metrics that correlate better with human perception, such as feature perceptual loss and the classification accuracy, sparse image compression scores up to 18.06\% and 2.7\% higher, respectively, compared to bottleneck autoencoders. Although computationally much more intensive, we find that sparse coding is otherwise superior to bottleneck autoencoders for the same degree of compression.
Does Phase Matter For Monaural Source Separation?
Nov 02, 2017


The "cocktail party" problem of fully separating multiple sources from a single channel audio waveform remains unsolved. Current biological understanding of neural encoding suggests that phase information is preserved and utilized at every stage of the auditory pathway. However, current computational approaches primarily discard phase information in order to mask amplitude spectrograms of sound. In this paper, we seek to address whether preserving phase information in spectral representations of sound provides better results in monaural separation of vocals from a musical track by using a neurally plausible sparse generative model. Our results demonstrate that preserving phase information reduces artifacts in the separated tracks, as quantified by the signal to artifact ratio (GSAR). Furthermore, our proposed method achieves state-of-the-art performance for source separation, as quantified by a mean signal to interference ratio (GSIR) of 19.46.