 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Effective Baseline for Robustness to Distributional Shift
May 15, 2021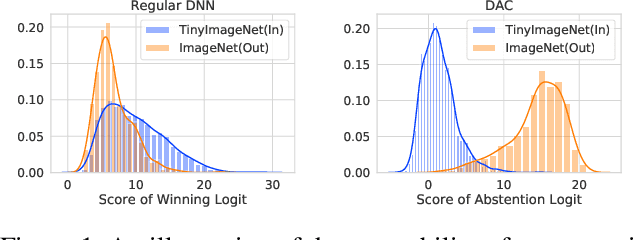
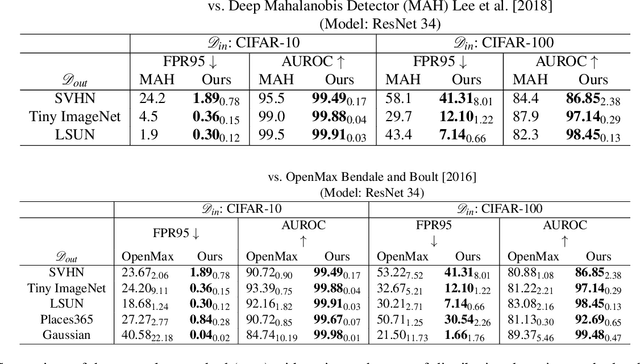
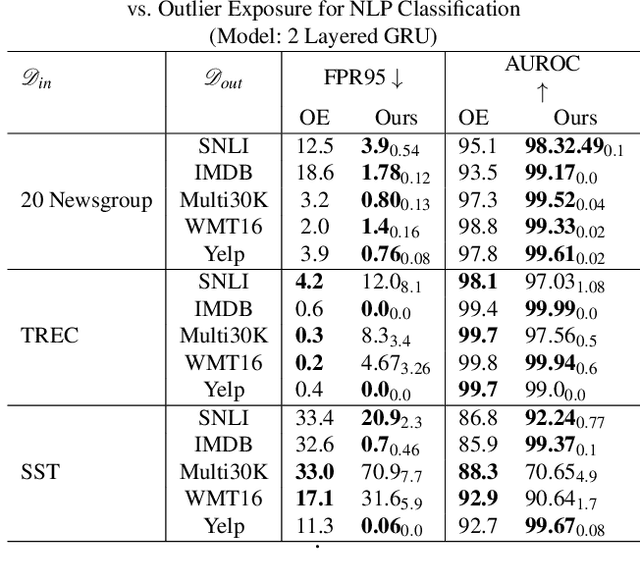
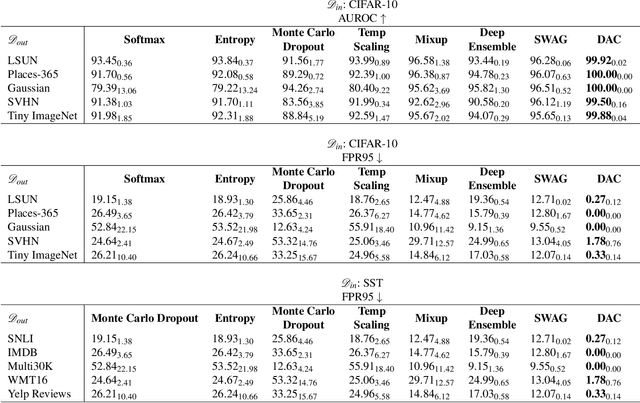
Refraining from confidently predicting when faced with categories of inputs different from those seen during training is an important requirement for the safe deployment of deep learning systems. While simple to state, this has been a particularly challenging problem in deep learning, where models often end up making overconfident predictions in such situations. In this work we present a simple, but highly effective approach to deal with out-of-distribution detection that uses the principle of abstention: when encountering a sample from an unseen class, the desired behavior is to abstain from predicting. Our approach uses a network with an extra abstention class and is trained on a dataset that is augmented with an uncurated set that consists of a large number of out-of-distribution (OoD) samples that are assigned the label of the abstention class; the model is then trained to learn an effective discriminator between in and out-of-distribution samples. We compare this relatively simple approach against a wide variety of more complex methods that have been proposed both for out-of-distribution detection as well as uncertainty modeling in deep learning, and empirically demonstrate its effectiveness on a wide variety of of benchmarks and deep architectures for image recognition and text classification, often outperforming existing approaches by significant margins. Given the simplicity and effectiveness of this method, we propose that this approach be used as a new additional baseline for future work in this domain.
Autonomous Control of a Particle Accelerator using Deep Reinforcement Learning
Oct 16, 2020
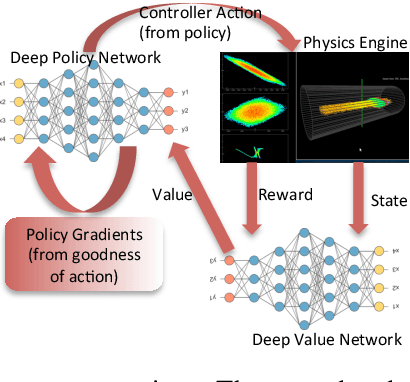

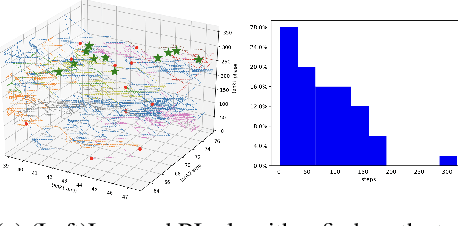
We describe an approach to learning optimal control policies for a large, linear particle accelerator using deep reinforcement learning coupled with a high-fidelity physics engine. The framework consists of an AI controller that uses deep neural nets for state and action-space representation and learns optimal policies using reward signals that are provided by the physics simulator. For this work, we only focus on controlling a small section of the entire accelerator. Nevertheless, initial results indicate that we can achieve better-than-human level performance in terms of particle beam current and distribution. The ultimate goal of this line of work is to substantially reduce the tuning time for such facilities by orders of magnitude, and achieve near-autonomous control.
Why I'm not Answering: Understanding Determinants of Classification of an Abstaining Classifier for Cancer Pathology Reports
Sep 24, 2020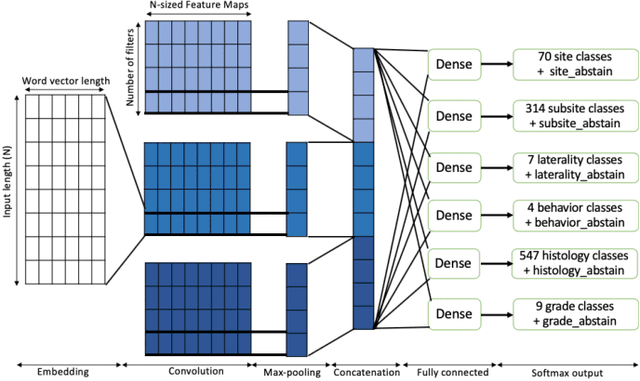

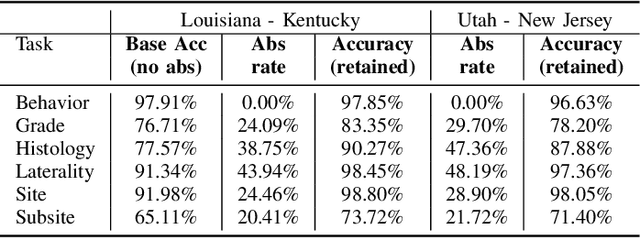
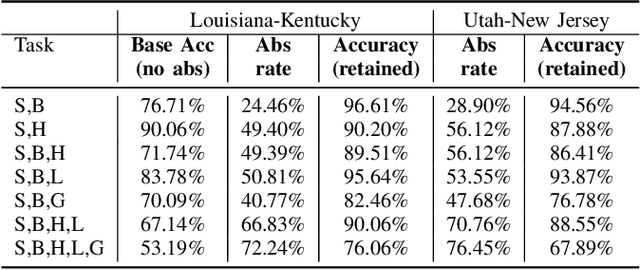
Safe deployment of deep learning systems in critical real world applications requires models to make few mistakes, and only under predictable circumstances. Development of such a model is not yet possible, in general. In this work, we address this problem with an abstaining classifier tuned to have $>$95% accuracy, and identify the determinants of abstention with LIME (the Local Interpretable Model-agnostic Explanations method). Essentially, we are training our model to learn the attributes of pathology reports that are likely to lead to incorrect classifications, albeit at the cost of reduced sensitivity. We demonstrate our method in a multitask setting to classify cancer pathology reports from the NCI SEER cancer registries on six tasks of greatest importance. For these tasks, we reduce the classification error rate by factors of 2-5 by abstaining on 25-45% of the reports. For the specific case of cancer site, we are able to identify metastasis and reports involving lymph nodes as responsible for many of the classification mistakes, and that the extent and types of mistakes vary systematically with cancer site (eg. breast, lung, and prostate). When combining across three of the tasks, our model classifies 50% of the reports with an accuracy greater than 95% for three of the six tasks and greater than 85% for all six tasks on the retained samples. By using this information, we expect to define work flows that incorporate machine learning only in the areas where it is sufficiently robust and accurate, saving human attention to areas where it is required.
On Mixup Training: Improved Calibration and Predictive Uncertainty for Deep Neural Networks
May 27, 2019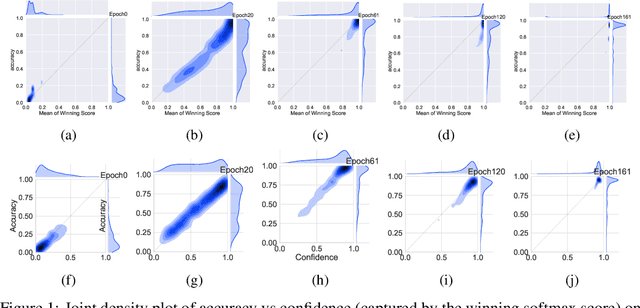
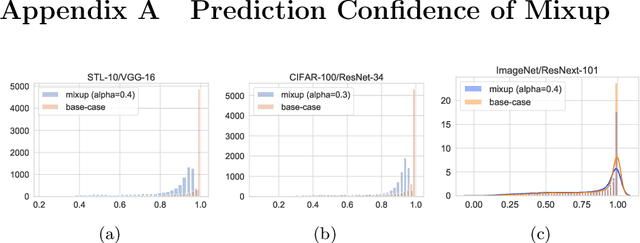
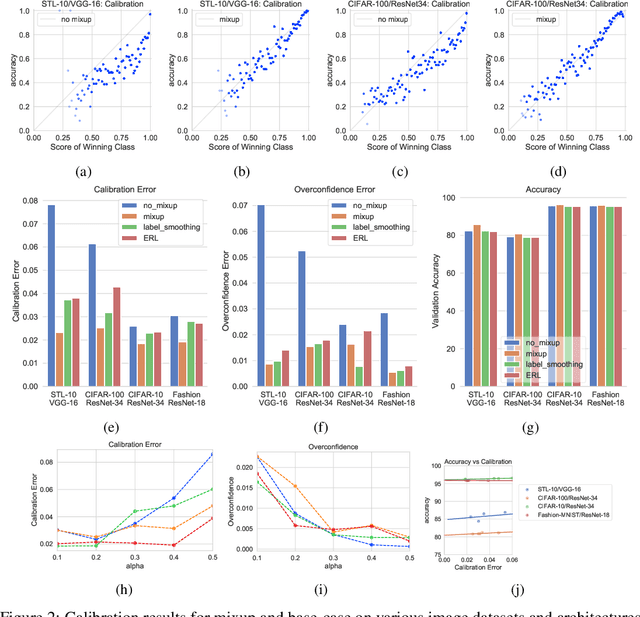
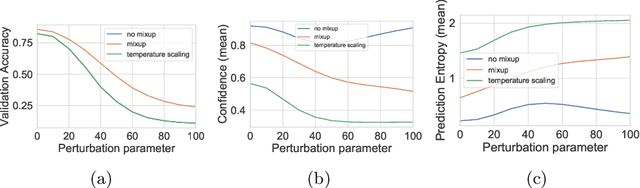
Mixup~\cite{zhang2017mixup} is a recently proposed method for training deep neural networks where additional samples are generated during training by convexly combining random pairs of images and their associated labels. While simple to implement, it has shown to be a surprisingly effective method of data augmentation for image classification; DNNs trained with mixup show noticeable gains in classification performance on a number of image classification benchmarks. In this work, we discuss a hitherto untouched aspect of mixup training -- the calibration and predictive uncertainty of models trained with mixup. We find that DNNs trained with mixup are significantly better calibrated -- i.e., the predicted softmax scores are much better indicators of the actual likelihood of a correct prediction -- than DNNs trained in the regular fashion. We conduct experiments on a number of image classification architectures and datasets -- including large-scale datasets like ImageNet -- and find this to be the case. Additionally, we find that merely mixing features does not result in the same calibration benefit and that the label smoothing in mixup training plays a significant role in improving calibration. Finally, we also observe that mixup-trained DNNs are less prone to over-confident predictions on out-of-distribution and random-noise data. We conclude that the typical overconfidence seen in neural networks, even on in-distribution data is likely a consequence of training with hard labels, suggesting that mixup training be employed for classification tasks where predictive uncertainty is a significant concern.
Combating Label Noise in Deep Learning Using Abstention
May 27, 2019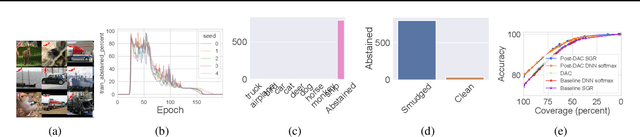
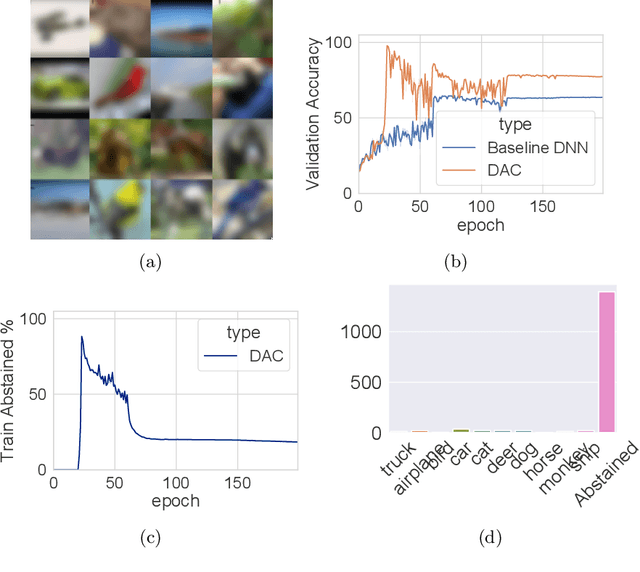
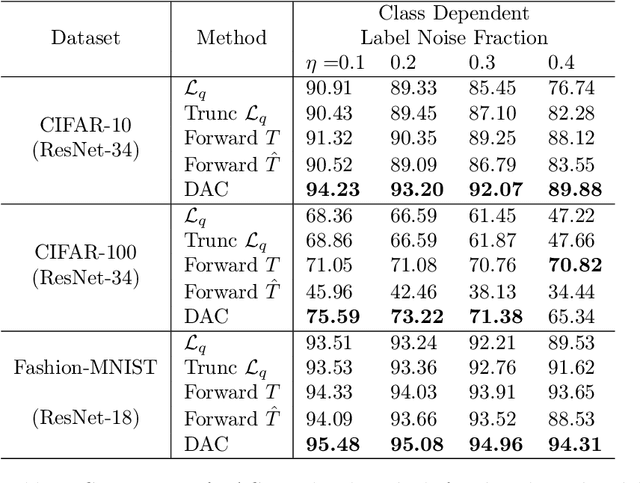
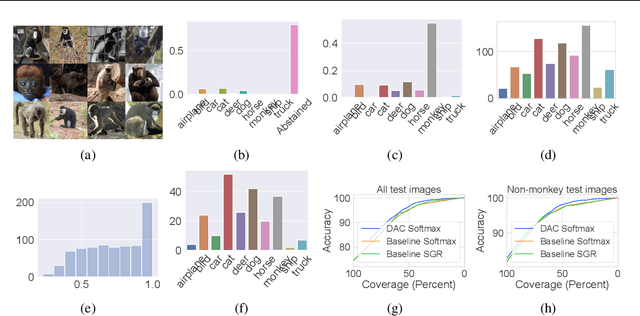
We introduce a novel method to combat label noise when training deep neural networks for classification. We propose a loss function that permits abstention during training thereby allowing the DNN to abstain on confusing samples while continuing to learn and improve classification performance on the non-abstained samples. We show how such a deep abstaining classifier (DAC) can be used for robust learning in the presence of different types of label noise. In the case of structured or systematic label noise -- where noisy training labels or confusing examples are correlated with underlying features of the data-- training with abstention enables representation learning for features that are associated with unreliable labels. In the case of unstructured (arbitrary) label noise, abstention during training enables the DAC to be used as an effective data cleaner by identifying samples that are likely to have label noise. We provide analytical results on the loss function behavior that enable dynamic adaption of abstention rates based on learning progress during training. We demonstrate the utility of the deep abstaining classifier for various image classification tasks under different types of label noise; in the case of arbitrary label noise, we show significant improvements over previously published results on multiple image benchmarks.
Efficient Distributed Semi-Supervised Learning using Stochastic Regularization over Affinity Graphs
May 30, 2018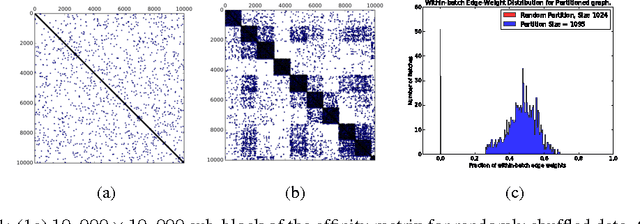
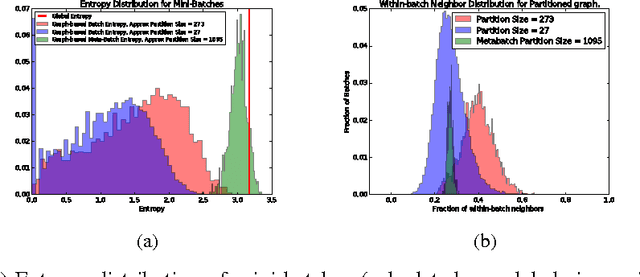

We describe a computationally efficient, stochastic graph-regularization technique that can be utilized for the semi-supervised training of deep neural networks in a parallel or distributed setting. We utilize a technique, first described in [13] for the construction of mini-batches for stochastic gradient descent (SGD) based on synthesized partitions of an affinity graph that are consistent with the graph structure, but also preserve enough stochasticity for convergence of SGD to good local minima. We show how our technique allows a graph-based semi-supervised loss function to be decomposed into a sum over objectives, facilitating data parallelism for scalable training of machine learning models. Empirical results indicate that our method significantly improves classification accuracy compared to the fully-supervised case when the fraction of labeled data is low, and in the parallel case, achieves significant speed-up in terms of wall-clock time to convergence. We show the results for both sequential and distributed-memory semi-supervised DNN training on a speech corpus.
Semi-Supervised Phone Classification using Deep Neural Networks and Stochastic Graph-Based Entropic Regularization
May 30, 2018

We describe a graph-based semi-supervised learning framework in the context of deep neural networks that uses a graph-based entropic regularizer to favor smooth solutions over a graph induced by the data. The main contribution of this work is a computationally efficient, stochastic graph-regularization technique that uses mini-batches that are consistent with the graph structure, but also provides enough stochasticity (in terms of mini-batch data diversity) for convergence of stochastic gradient descent methods to good solutions. For this work, we focus on results of frame-level phone classification accuracy on the TIMIT speech corpus but our method is general and scalable to much larger data sets. Results indicate that our method significantly improves classification accuracy compared to the fully-supervised case when the fraction of labeled data is low, and it is competitive with other methods in the fully labeled case.