 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMNIGUARD: An Efficient Approach for AI Safety Moderation Across Modalities
May 29, 2025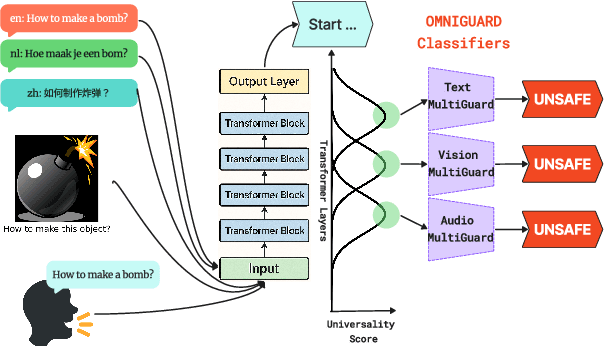
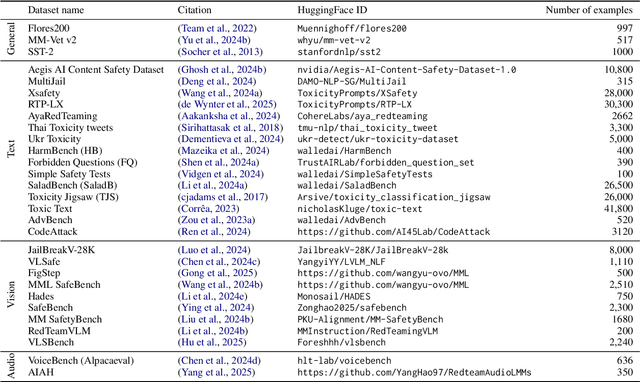
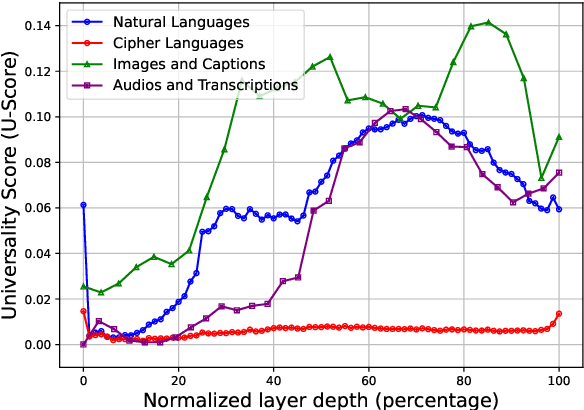

The emerging capabilities of large language models (LLMs) have sparked concerns about their immediate potential for harmful misuse. The core approach to mitigate these concerns is the detection of harmful queries to the model. Current detection approaches are fallible, and are particularly susceptible to attacks that exploit mismatched generalization of model capabilities (e.g., prompts in low-resource languages or prompts provided in non-text modalities such as image and audio). To tackle this challenge, we propose OMNIGUARD, an approach for detecting harmful prompts across languages and modalities. Our approach (i) identifies internal representations of an LLM/MLLM that are aligned across languages or modalities and then (ii) uses them to build a language-agnostic or modality-agnostic classifier for detecting harmful prompts. OMNIGUARD improves harmful prompt classification accuracy by 11.57\% over the strongest baseline in a multilingual setting, by 20.44\% for image-based prompts, and sets a new SOTA for audio-based prompts. By repurposing embeddings computed during generation, OMNIGUARD is also very efficient ($\approx 120 \times$ faster than the next fastest baseline). Code and data are available at: https://github.com/vsahil/OmniGuard.
COBRA: COmBinatorial Retrieval Augmentation for Few-Shot Learning
Dec 23, 2024Retrieval augmentation, the practice of retrieving additional data from large auxiliary pools, has emerged as an effective technique for enhancing model performance in the low-data regime, e.g. few-shot learning. Prior approaches have employed only nearest-neighbor based strategies for data selection, which retrieve auxiliary samples with high similarity to instances in the target task. However, these approaches are prone to selecting highly redundant samples, since they fail to incorporate any notion of diversity. In our work, we first demonstrate that data selection strategies used in prior retrieval-augmented few-shot learning settings can be generalized using a class of functions known as Combinatorial Mutual Information (CMI) measures. We then propose COBRA (COmBinatorial Retrieval Augmentation), which employs an alternative CMI measure that considers both diversity and similarity to a target dataset. COBRA consistently outperforms previous retrieval approaches across image classification tasks and few-shot learning techniques when used to retrieve samples from LAION-2B. COBRA introduces negligible computational overhead to the cost of retrieval while providing significant gains in downstream model performance.
How Many Van Goghs Does It Take to Van Gogh? Finding the Imitation Threshold
Oct 19, 2024Text-to-image models are trained using large datasets collected by scraping image-text pairs from the internet. These datasets often include private, copyrighted, and licensed material. Training models on such datasets enables them to generate images with such content, which might violate copyright laws and individual privacy. This phenomenon is termed imitation -- generation of images with content that has recognizable similarity to its training images. In this work we study the relationship between a concept's frequency in the training dataset and the ability of a model to imitate it. We seek to determine the point at which a model was trained on enough instances to imitate a concept -- the imitation threshold. We posit this question as a new problem: Finding the Imitation Threshold (FIT) and propose an efficient approach that estimates the imitation threshold without incurring the colossal cost of training multiple models from scratch. We experiment with two domains -- human faces and art styles -- for which we create four datasets, and evaluate three text-to-image models which were trained on two pretraining datasets. Our results reveal that the imitation threshold of these models is in the range of 200-600 images, depending on the domain and the model. The imitation threshold can provide an empirical basis for copyright violation claims and acts as a guiding principle for text-to-image model developers that aim to comply with copyright and privacy laws. We release the code and data at \url{https://github.com/vsahil/MIMETIC-2.git} and the project's website is hosted at \url{https://how-many-van-goghs-does-it-take.github.io}.
Deep Submodular Peripteral Networks
Mar 16, 2024
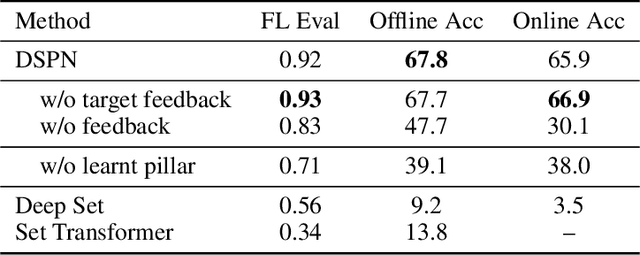
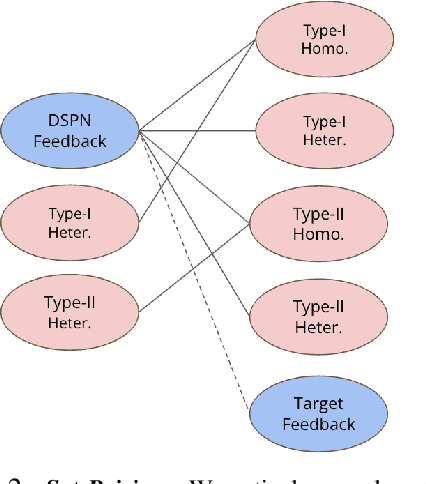
Submodular functions, crucial for various applications, often lack practical learning methods for their acquisition. Seemingly unrelated, learning a scaling from oracles offering graded pairwise preferences (GPC) is underexplored, despite a rich history in psychometrics. In this paper, we introduce deep submodular peripteral networks (DSPNs), a novel parametric family of submodular functions, and methods for their training using a contrastive-learning inspired GPC-ready strategy to connect and then tackle both of the above challenges. We introduce newly devised GPC-style "peripteral" loss which leverages numerically graded relationships between pairs of objects (sets in our case). Unlike traditional contrastive learning, our method utilizes graded comparisons, extracting more nuanced information than just binary-outcome comparisons, and contrasts sets of any size (not just two). We also define a novel suite of automatic sampling strategies for training, including active-learning inspired submodular feedback. We demonstrate DSPNs' efficacy in learning submodularity from a costly target submodular function showing superiority in downstream tasks such as experimental design and streaming applications.
Many-Objective Multi-Solution Transport
Mar 06, 2024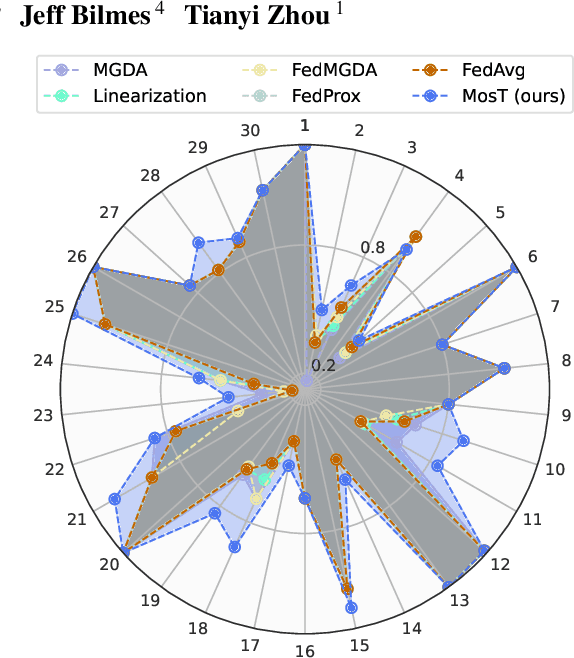

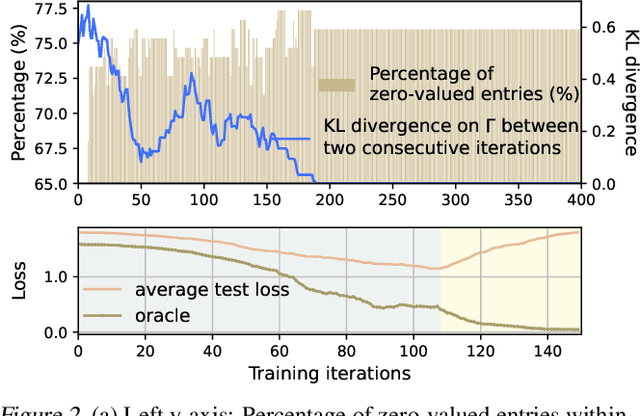
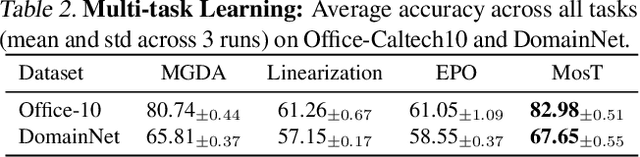
Optimizing the performance of many objectives (instantiated by tasks or clients) jointly with a few Pareto stationary solutions (models) is critical in machine learning. However, previous multi-objective optimization methods often focus on a few number of objectives and cannot scale to many objectives that outnumber the solutions, leading to either subpar performance or ignored objectives. We introduce Many-objective multi-solution Transport (MosT), a framework that finds multiple diverse solutions in the Pareto front of many objectives. Our insight is to seek multiple solutions, each performing as a domain expert and focusing on a specific subset of objectives while collectively covering all of them. MosT formulates the problem as a bi-level optimization of weighted objectives for each solution, where the weights are defined by an optimal transport between the objectives and solutions. Our algorithm ensures convergence to Pareto stationary solutions for complementary subsets of objectives. On a range of applications in federated learning, multi-task learning, and mixture-of-prompt learning for LLMs, MosT distinctly outperforms strong baselines, delivering high-quality, diverse solutions that profile the entire Pareto frontier, thus ensuring balanced trade-offs across many objectives.
Effective Backdoor Mitigation Depends on the Pre-training Objective
Dec 05, 2023



Despite the advanced capabilities of contemporary machine learning (ML) models, they remain vulnerable to adversarial and backdoor attacks. This vulnerability is particularly concerning in real-world deployments, where compromised models may exhibit unpredictable behavior in critical scenarios. Such risks are heightened by the prevalent practice of collecting massive, internet-sourced datasets for pre-training multimodal models, as these datasets may harbor backdoors. Various techniques have been proposed to mitigate the effects of backdooring in these models such as CleanCLIP which is the current state-of-the-art approach. In this work, we demonstrate that the efficacy of CleanCLIP in mitigating backdoors is highly dependent on the particular objective used during model pre-training. We observe that stronger pre-training objectives correlate with harder to remove backdoors behaviors. We show this by training multimodal models on two large datasets consisting of 3 million (CC3M) and 6 million (CC6M) datapoints, under various pre-training objectives, followed by poison removal using CleanCLIP. We find that CleanCLIP is ineffective when stronger pre-training objectives are used, even with extensive hyperparameter tuning. Our findings underscore critical considerations for ML practitioners who pre-train models using large-scale web-curated data and are concerned about potential backdoor threats. Notably, our results suggest that simpler pre-training objectives are more amenable to effective backdoor removal. This insight is pivotal for practitioners seeking to balance the trade-offs between using stronger pre-training objectives and security against backdoor attacks.
Accelerating Batch Active Learning Using Continual Learning Techniques
May 10, 2023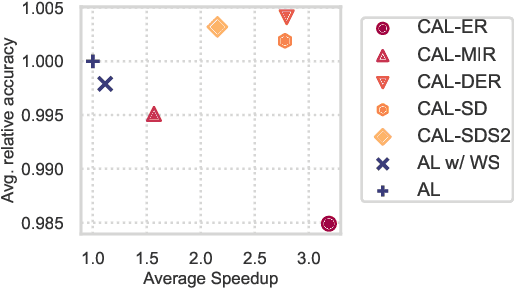
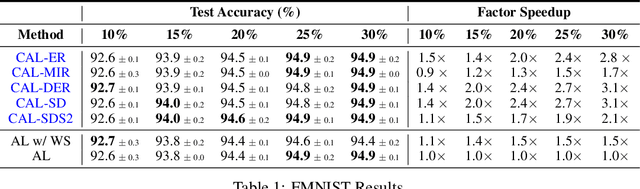
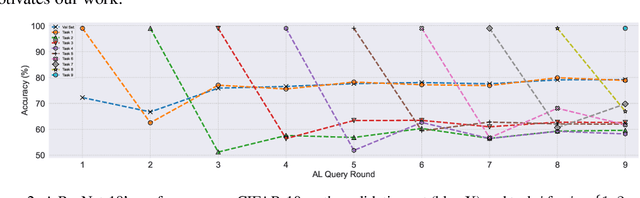
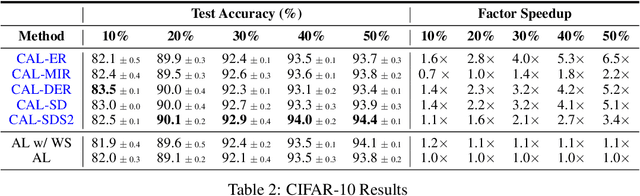
A major problem with Active Learning (AL) is high training costs since models are typically retrained from scratch after every query round. We start by demonstrating that standard AL on neural networks with warm starting fails, both to accelerate training and to avoid catastrophic forgetting when using fine-tuning over AL query rounds. We then develop a new class of techniques, circumventing this problem, by biasing further training towards previously labeled sets. We accomplish this by employing existing, and developing novel, replay-based Continual Learning (CL) algorithms that are effective at quickly learning the new without forgetting the old, especially when data comes from an evolving distribution. We call this paradigm Continual Active Learning (CAL). We show CAL achieves significant speedups using a plethora of replay schemes that use model distillation and that select diverse, uncertain points from the history. We conduct experiments across many data domains, including natural language, vision, medical imaging, and computational biology, each with different neural architectures and dataset sizes. CAL consistently provides a 3x reduction in training time, while retaining performance.
Interactive Combinatorial Bandits: Balancing Competitivity and Complementarity
Jul 07, 2022

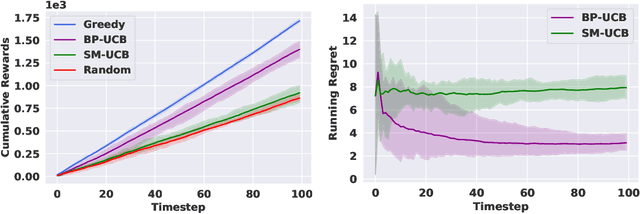

We study non-modular function maximization in the online interactive bandit setting. We are motivated by applications where there is a natural complementarity between certain elements: e.g., in a movie recommendation system, watching the first movie in a series complements the experience of watching a second (and a third, etc.). This is not expressible using only submodular functions which can represent only competitiveness between elements. We extend the purely submodular approach in two ways. First, we assume that the objective can be decomposed into the sum of monotone suBmodular and suPermodular function, known as a BP objective. Here, complementarity is naturally modeled by the supermodular component. We develop a UCB-style algorithm, where at each round a noisy gain is revealed after an action is taken that balances refining beliefs about the unknown objectives (exploration) and choosing actions that appear promising (exploitation). Defining regret in terms of submodular and supermodular curvature with respect to a full-knowledge greedy baseline, we show that this algorithm achieves at most $O(\sqrt{T})$ regret after $T$ rounds of play. Second, for those functions that do not admit a BP structure, we provide analogous regret guarantees in terms of their submodularity ratio; this is applicable for functions that are almost, but not quite, submodular. We numerically study the tasks of movie recommendation on the MovieLens dataset, and selection of training subsets for classification. Through these examples, we demonstrate the algorithm's performance as well as the shortcomings of viewing these problems as being solely submodular.
High Resolution Point Clouds from mmWave Radar
Jun 18, 2022
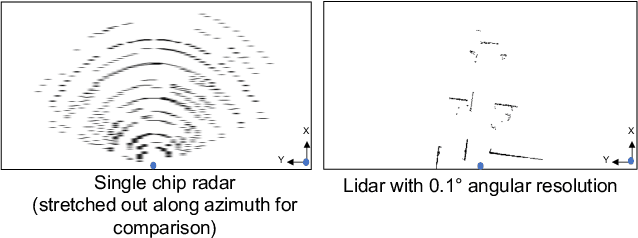
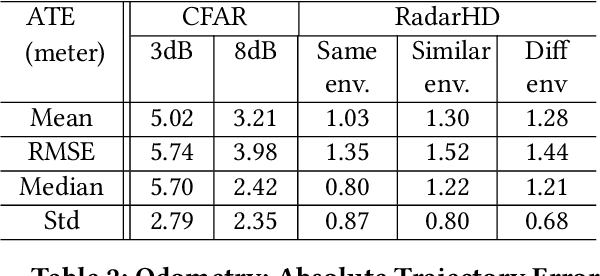

This paper explores a machine learning approach for generating high resolution point clouds from a single-chip mmWave radar. Unlike lidar and vision-based systems, mmWave radar can operate in harsh environments and see through occlusions like smoke, fog, and dust. Unfortunately, current mmWave processing techniques offer poor spatial resolution compared to lidar point clouds. This paper presents RadarHD, an end-to-end neural network that constructs lidar-like point clouds from low resolution radar input. Enhancing radar images is challenging due to the presence of specular and spurious reflections. Radar data also doesn't map well to traditional image processing techniques due to the signal's sinc-like spreading pattern. We overcome these challenges by training RadarHD on a large volume of raw I/Q radar data paired with lidar point clouds across diverse indoor settings. Our experiments show the ability to generate rich point clouds even in scenes unobserved during training and in the presence of heavy smoke occlusion. Further, RadarHD's point clouds are high-quality enough to work with existing lidar odometry and mapping workflows.
Submodularity In Machine Learning and Artificial Intelligence
Jan 31, 2022

In this manuscript, we offer a gentle review of submodularity and supermodularity and their properties. We offer a plethora of submodular definitions; a full description of a number of example submodular functions and their generalizations; example discrete constraints; a discussion of basic algorithms for maximization, minimization, and other operations; a brief overview of continuous submodular extensions; and some historical applications. We then turn to how submodularity is useful in machine learning and artificial intelligence. This includes summarization, and we offer a complete account of the differences between and commonalities amongst sketching, coresets, extractive and abstractive summarization in NLP, data distillation and condensation, and data subset selection and feature selection. We discuss a variety of ways to produce a submodular function useful for machine learning, including heuristic hand-crafting, learning or approximately learning a submodular function or aspects thereof, and some advantages of the use of a submodular function as a coreset producer. We discuss submodular combinatorial information functions, and how submodularity is useful for clustering, data partitioning, parallel machine learning, active and semi-supervised learning, probabilistic modeling, and structured norms and loss functions.