 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Batch Active Learning Using Continual Learning Techniques
May 10, 2023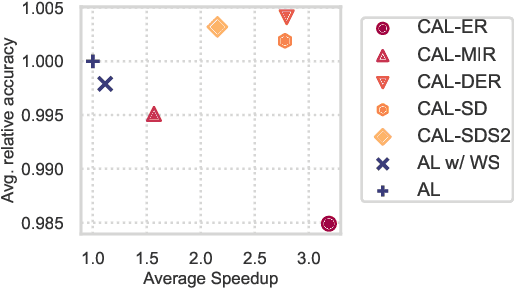
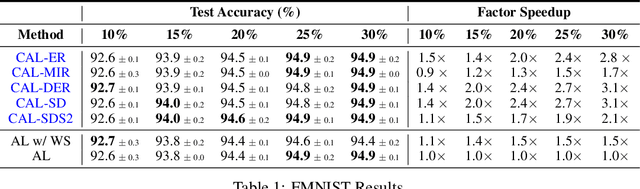
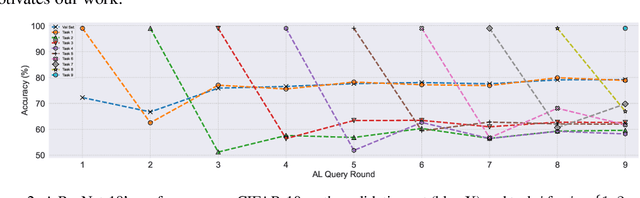
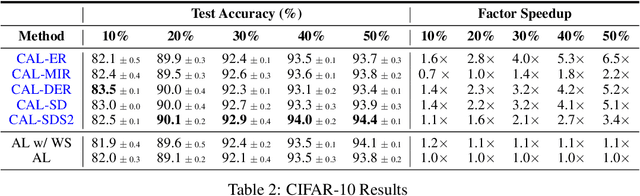
A major problem with Active Learning (AL) is high training costs since models are typically retrained from scratch after every query round. We start by demonstrating that standard AL on neural networks with warm starting fails, both to accelerate training and to avoid catastrophic forgetting when using fine-tuning over AL query rounds. We then develop a new class of techniques, circumventing this problem, by biasing further training towards previously labeled sets. We accomplish this by employing existing, and developing novel, replay-based Continual Learning (CL) algorithms that are effective at quickly learning the new without forgetting the old, especially when data comes from an evolving distribution. We call this paradigm Continual Active Learning (CAL). We show CAL achieves significant speedups using a plethora of replay schemes that use model distillation and that select diverse, uncertain points from the history. We conduct experiments across many data domains, including natural language, vision, medical imaging, and computational biology, each with different neural architectures and dataset sizes. CAL consistently provides a 3x reduction in training time, while retaining performance.
GaNDLF: A Generally Nuanced Deep Learning Framework for Scalable End-to-End Clinical Workflows in Medical Imaging
Feb 26, 2021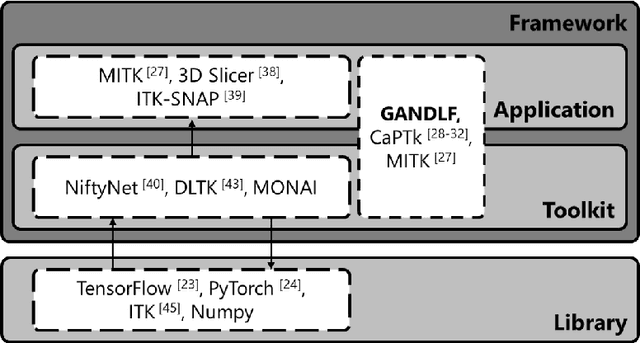

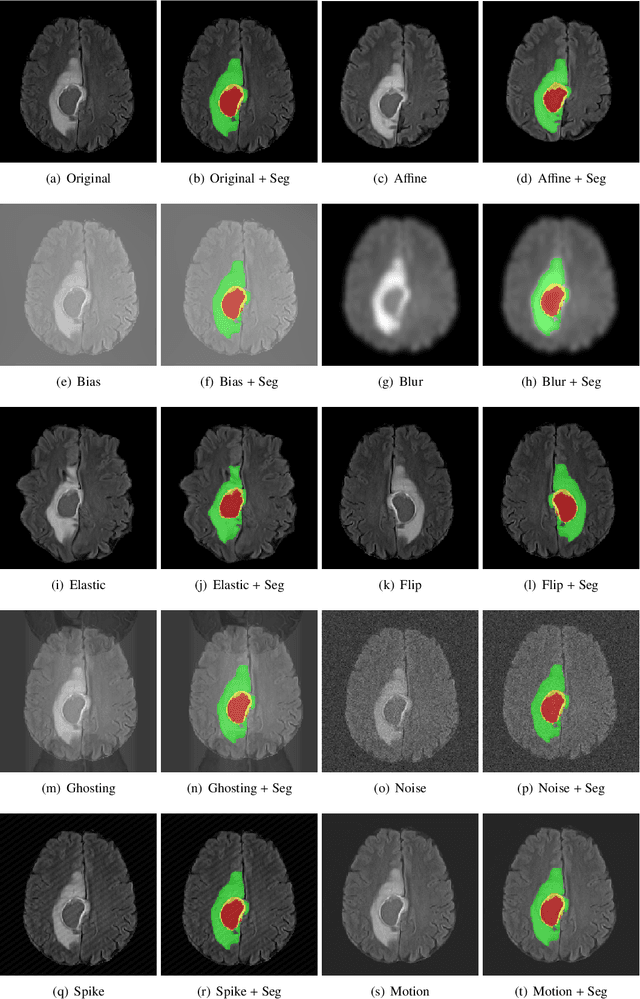
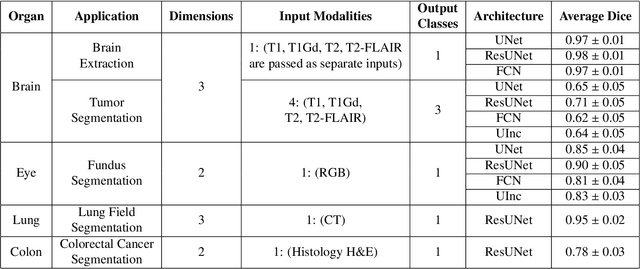
Deep Learning (DL) has greatly highlighted the potential impact of optimized machine learning in both the scientific and clinical communities. The advent of open-source DL libraries from major industrial entities, such as TensorFlow (Google), PyTorch (Facebook), and MXNet (Apache), further contributes to DL promises on the democratization of computational analytics. However, increased technical and specialized background is required to develop DL algorithms, and the variability of implementation details hinders their reproducibility. Towards lowering the barrier and making the mechanism of DL development, training, and inference more stable, reproducible, and scalable, without requiring an extensive technical background, this manuscript proposes the \textbf{G}ener\textbf{a}lly \textbf{N}uanced \textbf{D}eep \textbf{L}earning \textbf{F}ramework (GaNDLF). With built-in support for $k$-fold cross-validation, data augmentation, multiple modalities and output classes, and multi-GPU training, as well as the ability to work with both radiographic and histologic imaging, GaNDLF aims to provide an end-to-end solution for all DL-related tasks, to tackle problems in medical imaging and provide a robust application framework for deployment in clinical workflows.