 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Batch Active Learning Using Continual Learning Techniques
Paper and Code
May 10, 2023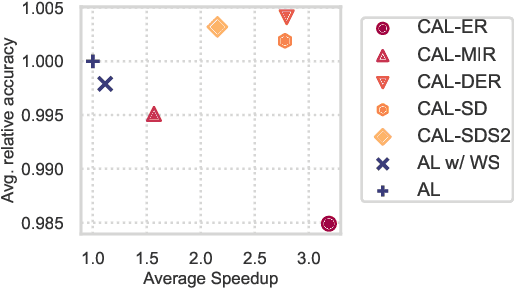
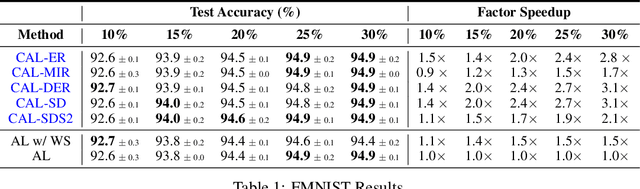
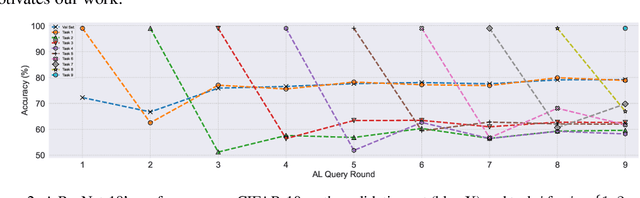
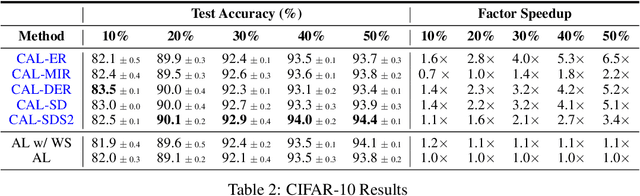
A major problem with Active Learning (AL) is high training costs since models are typically retrained from scratch after every query round. We start by demonstrating that standard AL on neural networks with warm starting fails, both to accelerate training and to avoid catastrophic forgetting when using fine-tuning over AL query rounds. We then develop a new class of techniques, circumventing this problem, by biasing further training towards previously labeled sets. We accomplish this by employing existing, and developing novel, replay-based Continual Learning (CL) algorithms that are effective at quickly learning the new without forgetting the old, especially when data comes from an evolving distribution. We call this paradigm Continual Active Learning (CAL). We show CAL achieves significant speedups using a plethora of replay schemes that use model distillation and that select diverse, uncertain points from the history. We conduct experiments across many data domains, including natural language, vision, medical imaging, and computational biology, each with different neural architectures and dataset sizes. CAL consistently provides a 3x reduction in training time, while retaining performance.