 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Is a Dataset Worth? Scaling Laws, the Vendi Score, and Matrix Spectral Functions
May 28, 2026Neural scaling laws appraise data through dataset size, while the Vendi Score uses quantum entropy to measure dataset value. We show both that common neural-scaling-law objectives and the Vendi Score are submodular. We further show that the Vendi Score is a special case of a broader class of submodular objectives that we call matrix spectral functions. This also includes determinantal (DPP) objectives, as well as many others. We also introduce weakly matrix monotone functions and show how they lead to weakly submodular matrix spectral functions, yielding a broad family of practical objectives for data appraisal. We develop secular-equation-based updates that avoid repeated eigendecompositions during greedy optimization, reducing marginal-gain evaluation for $m$-dimensional embeddings by an $O(m)$ factor relative to oracle queries. This yields an average empirical speedup of about 35,000x, making direct optimization of the Vendi Score feasible on ImageNet-1K-scale datasets. Thus enabled, we compare how well several objectives predict the value of training subsets for held-out test performance under fixed-size, class-balanced, and fixed training-budget regimes, including the Vendi Score, DPPs, facility location, and three new matrix spectral variants. Across multiple datasets, facility location performs the best. Direct optimization also reveals that, while the Vendi Score is predictive over moderate score ranges, pushing the objective to higher values can make it a poor downstream performance proxy. We also find that uniformly at random fixed-size subsets, both unconstrained and class-balanced, are remarkably concentrated in both appraisal scores and held-out performance. Finally, we show that size, class balance, and training budget do not alone determine data value: even when controlling for these factors, performance ranges smoothly from good to bad.
Benchmarking Single-Factor Physical Video-to-Audio Generation
May 28, 2026Generative video-to-audio (V2A) models produce highly plausible soundtracks, but it remains unclear whether they capture the underlying physical processes. Existing evaluations emphasize perceptual realism and overlook physical correctness under controlled interventions. In this paper, we introduce FlatSounds, a benchmark that audits the physical reasoning of V2A models through: 1) controlled counterfactual pairs in which a single physical factor is varied, and 2) single-video pattern tests that probe internal consistency and directional trends. These settings test whether the generated audio correctly reflects specific physical properties and timings. Our evaluation of state-of-the-art models reveals a consistent trade-off: models rely more on text captions than the visual stream to infer physics and semantics. Captions generally improve physical and semantic accuracy, but paradoxically degrade temporal alignment. Our results highlight the need to move beyond audio quality toward learning physical processes directly from pixels. Finally, we find that our physics-based metrics correlate strongly with human preference tests on our own data. Project webpage: https://research.nvidia.com/labs/cosmos-lab/flatsounds/
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
COBRA: COmBinatorial Retrieval Augmentation for Few-Shot Learning
Dec 23, 2024Retrieval augmentation, the practice of retrieving additional data from large auxiliary pools, has emerged as an effective technique for enhancing model performance in the low-data regime, e.g. few-shot learning. Prior approaches have employed only nearest-neighbor based strategies for data selection, which retrieve auxiliary samples with high similarity to instances in the target task. However, these approaches are prone to selecting highly redundant samples, since they fail to incorporate any notion of diversity. In our work, we first demonstrate that data selection strategies used in prior retrieval-augmented few-shot learning settings can be generalized using a class of functions known as Combinatorial Mutual Information (CMI) measures. We then propose COBRA (COmBinatorial Retrieval Augmentation), which employs an alternative CMI measure that considers both diversity and similarity to a target dataset. COBRA consistently outperforms previous retrieval approaches across image classification tasks and few-shot learning techniques when used to retrieve samples from LAION-2B. COBRA introduces negligible computational overhead to the cost of retrieval while providing significant gains in downstream model performance.
How Many Van Goghs Does It Take to Van Gogh? Finding the Imitation Threshold
Oct 19, 2024Text-to-image models are trained using large datasets collected by scraping image-text pairs from the internet. These datasets often include private, copyrighted, and licensed material. Training models on such datasets enables them to generate images with such content, which might violate copyright laws and individual privacy. This phenomenon is termed imitation -- generation of images with content that has recognizable similarity to its training images. In this work we study the relationship between a concept's frequency in the training dataset and the ability of a model to imitate it. We seek to determine the point at which a model was trained on enough instances to imitate a concept -- the imitation threshold. We posit this question as a new problem: Finding the Imitation Threshold (FIT) and propose an efficient approach that estimates the imitation threshold without incurring the colossal cost of training multiple models from scratch. We experiment with two domains -- human faces and art styles -- for which we create four datasets, and evaluate three text-to-image models which were trained on two pretraining datasets. Our results reveal that the imitation threshold of these models is in the range of 200-600 images, depending on the domain and the model. The imitation threshold can provide an empirical basis for copyright violation claims and acts as a guiding principle for text-to-image model developers that aim to comply with copyright and privacy laws. We release the code and data at \url{https://github.com/vsahil/MIMETIC-2.git} and the project's website is hosted at \url{https://how-many-van-goghs-does-it-take.github.io}.
Comparing Bad Apples to Good Oranges: Aligning Large Language Models via Joint Preference Optimization
Mar 31, 2024A common technique for aligning large language models (LLMs) relies on acquiring human preferences by comparing multiple generations conditioned on a fixed context. This only leverages the pairwise comparisons when the generations are placed in an identical context. However, such conditional rankings often fail to capture the complex and multidimensional aspects of human preferences. In this work, we revisit the traditional paradigm of preference acquisition and propose a new axis that is based on eliciting preferences jointly over the instruction-response pairs. While prior preference optimizations are designed for conditional ranking protocols (e.g., DPO), our proposed preference acquisition protocol introduces DOVE, a new preference optimization objective that upweights the joint probability of the chosen instruction-response pair over the rejected instruction-response pair. Interestingly, we find that the LLM trained with joint instruction-response preference data using DOVE outperforms the LLM trained with DPO by 5.2% and 3.3% win-rate for the summarization and open-ended dialogue datasets, respectively. Our findings reveal that joint preferences over instruction and response pairs can significantly enhance the alignment of LLMs by tapping into a broader spectrum of human preference elicitation. The data and code is available at https://github.com/Hritikbansal/dove.
Deep Submodular Peripteral Networks
Mar 16, 2024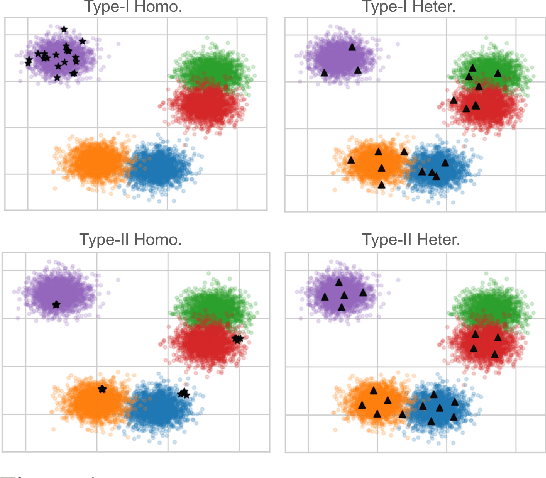
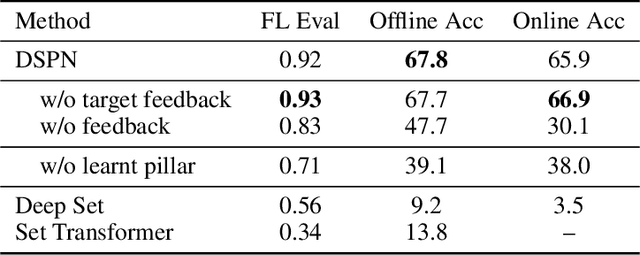
Submodular functions, crucial for various applications, often lack practical learning methods for their acquisition. Seemingly unrelated, learning a scaling from oracles offering graded pairwise preferences (GPC) is underexplored, despite a rich history in psychometrics. In this paper, we introduce deep submodular peripteral networks (DSPNs), a novel parametric family of submodular functions, and methods for their training using a contrastive-learning inspired GPC-ready strategy to connect and then tackle both of the above challenges. We introduce newly devised GPC-style "peripteral" loss which leverages numerically graded relationships between pairs of objects (sets in our case). Unlike traditional contrastive learning, our method utilizes graded comparisons, extracting more nuanced information than just binary-outcome comparisons, and contrasts sets of any size (not just two). We also define a novel suite of automatic sampling strategies for training, including active-learning inspired submodular feedback. We demonstrate DSPNs' efficacy in learning submodularity from a costly target submodular function showing superiority in downstream tasks such as experimental design and streaming applications.
An Experimental Design Framework for Label-Efficient Supervised Finetuning of Large Language Models
Jan 12, 2024



Supervised finetuning (SFT) on instruction datasets has played a crucial role in achieving the remarkable zero-shot generalization capabilities observed in modern large language models (LLMs). However, the annotation efforts required to produce high quality responses for instructions are becoming prohibitively expensive, especially as the number of tasks spanned by instruction datasets continues to increase. Active learning is effective in identifying useful subsets of samples to annotate from an unlabeled pool, but its high computational cost remains a barrier to its widespread applicability in the context of LLMs. To mitigate the annotation cost of SFT and circumvent the computational bottlenecks of active learning, we propose using experimental design. Experimental design techniques select the most informative samples to label, and typically maximize some notion of uncertainty and/or diversity. In our work, we implement a framework that evaluates several existing and novel experimental design techniques and find that these methods consistently yield significant gains in label efficiency with little computational overhead. On generative tasks, our methods achieve the same generalization performance with only $50\%$ of annotation cost required by random sampling.