 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Backdoor Mitigation Depends on the Pre-training Objective
Dec 05, 2023



Despite the advanced capabilities of contemporary machine learning (ML) models, they remain vulnerable to adversarial and backdoor attacks. This vulnerability is particularly concerning in real-world deployments, where compromised models may exhibit unpredictable behavior in critical scenarios. Such risks are heightened by the prevalent practice of collecting massive, internet-sourced datasets for pre-training multimodal models, as these datasets may harbor backdoors. Various techniques have been proposed to mitigate the effects of backdooring in these models such as CleanCLIP which is the current state-of-the-art approach. In this work, we demonstrate that the efficacy of CleanCLIP in mitigating backdoors is highly dependent on the particular objective used during model pre-training. We observe that stronger pre-training objectives correlate with harder to remove backdoors behaviors. We show this by training multimodal models on two large datasets consisting of 3 million (CC3M) and 6 million (CC6M) datapoints, under various pre-training objectives, followed by poison removal using CleanCLIP. We find that CleanCLIP is ineffective when stronger pre-training objectives are used, even with extensive hyperparameter tuning. Our findings underscore critical considerations for ML practitioners who pre-train models using large-scale web-curated data and are concerned about potential backdoor threats. Notably, our results suggest that simpler pre-training objectives are more amenable to effective backdoor removal. This insight is pivotal for practitioners seeking to balance the trade-offs between using stronger pre-training objectives and security against backdoor attacks.
Certified Neural Network Watermarks with Randomized Smoothing
Jul 16, 2022

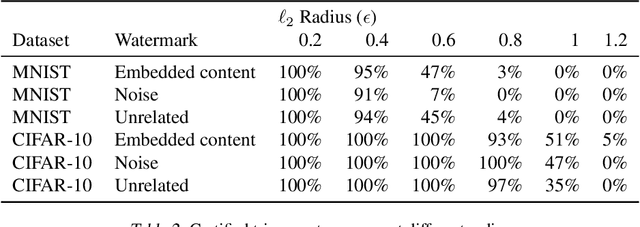

Watermarking is a commonly used strategy to protect creators' rights to digital images, videos and audio. Recently, watermarking methods have been extended to deep learning models -- in principle, the watermark should be preserved when an adversary tries to copy the model. However, in practice, watermarks can often be removed by an intelligent adversary. Several papers have proposed watermarking methods that claim to be empirically resistant to different types of removal attacks, but these new techniques often fail in the face of new or better-tuned adversaries. In this paper, we propose a certifiable watermarking method. Using the randomized smoothing technique proposed in Chiang et al., we show that our watermark is guaranteed to be unremovable unless the model parameters are changed by more than a certain l2 threshold. In addition to being certifiable, our watermark is also empirically more robust compared to previous watermarking methods. Our experiments can be reproduced with code at https://github.com/arpitbansal297/Certified_Watermarks
* ICML 2022
VQ-GNN: A Universal Framework to Scale up Graph Neural Networks using Vector Quantization
Oct 27, 2021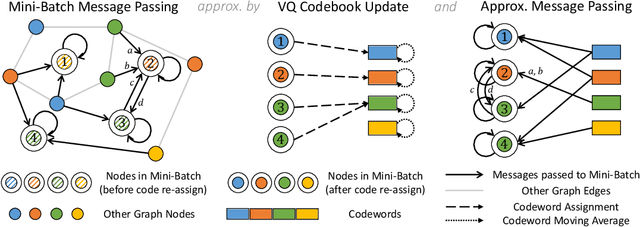
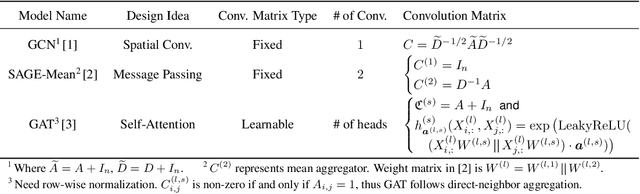
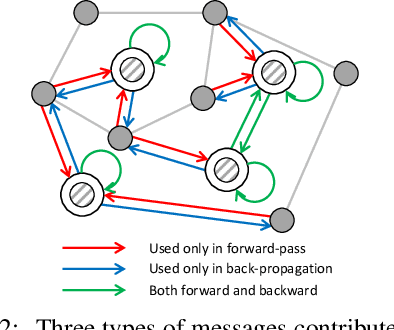

Most state-of-the-art Graph Neural Networks (GNNs) can be defined as a form of graph convolution which can be realized by message passing between direct neighbors or beyond. To scale such GNNs to large graphs, various neighbor-, layer-, or subgraph-sampling techniques are proposed to alleviate the "neighbor explosion" problem by considering only a small subset of messages passed to the nodes in a mini-batch. However, sampling-based methods are difficult to apply to GNNs that utilize many-hops-away or global context each layer, show unstable performance for different tasks and datasets, and do not speed up model inference. We propose a principled and fundamentally different approach, VQ-GNN, a universal framework to scale up any convolution-based GNNs using Vector Quantization (VQ) without compromising the performance. In contrast to sampling-based techniques, our approach can effectively preserve all the messages passed to a mini-batch of nodes by learning and updating a small number of quantized reference vectors of global node representations, using VQ within each GNN layer. Our framework avoids the "neighbor explosion" problem of GNNs using quantized representations combined with a low-rank version of the graph convolution matrix. We show that such a compact low-rank version of the gigantic convolution matrix is sufficient both theoretically and experimentally. In company with VQ, we design a novel approximated message passing algorithm and a nontrivial back-propagation rule for our framework. Experiments on various types of GNN backbones demonstrate the scalability and competitive performance of our framework on large-graph node classification and link prediction benchmarks.
Comparing Human and Machine Bias in Face Recognition
Oct 25, 2021

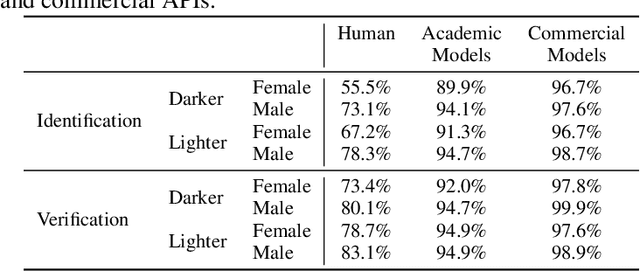
Much recent research has uncovered and discussed serious concerns of bias in facial analysis technologies, finding performance disparities between groups of people based on perceived gender, skin type, lighting condition, etc. These audits are immensely important and successful at measuring algorithmic bias but have two major challenges: the audits (1) use facial recognition datasets which lack quality metadata, like LFW and CelebA, and (2) do not compare their observed algorithmic bias to the biases of their human alternatives. In this paper, we release improvements to the LFW and CelebA datasets which will enable future researchers to obtain measurements of algorithmic bias that are not tainted by major flaws in the dataset (e.g. identical images appearing in both the gallery and test set). We also use these new data to develop a series of challenging facial identification and verification questions that we administered to various algorithms and a large, balanced sample of human reviewers. We find that both computer models and human survey participants perform significantly better at the verification task, generally obtain lower accuracy rates on dark-skinned or female subjects for both tasks, and obtain higher accuracy rates when their demographics match that of the question. Computer models are observed to achieve a higher level of accuracy than the survey participants on both tasks and exhibit bias to similar degrees as the human survey participants.
Matching Algorithms for Blood Donation
Aug 13, 2021

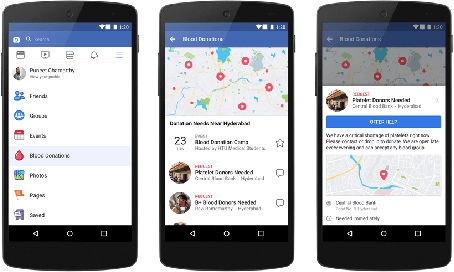
Global demand for donated blood far exceeds supply, and unmet need is greatest in low- and middle-income countries; experts suggest that large-scale coordination is necessary to alleviate demand. Using the Facebook Blood Donation tool, we conduct the first large-scale algorithmic matching of blood donors with donation opportunities. While measuring actual donation rates remains a challenge, we measure donor action (e.g., making a donation appointment) as a proxy for actual donation. We develop automated policies for matching donors with donation opportunities, based on an online matching model. We provide theoretical guarantees for these policies, both regarding the number of expected donations and the equitable treatment of blood recipients. In simulations, a simple matching strategy increases the number of donations by 5-10%; a pilot experiment with real donors shows a 5% relative increase in donor action rate (from 3.7% to 3.9%). When scaled to the global Blood Donation tool user base, this corresponds to an increase of around one hundred thousand users taking action toward donation. Further, observing donor action on a social network can shed light onto donor behavior and response to incentives. Our initial findings align with several observations made in the medical and social science literature regarding donor behavior.
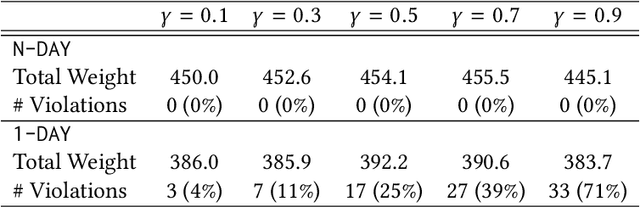
Indecision Modeling
Dec 15, 2020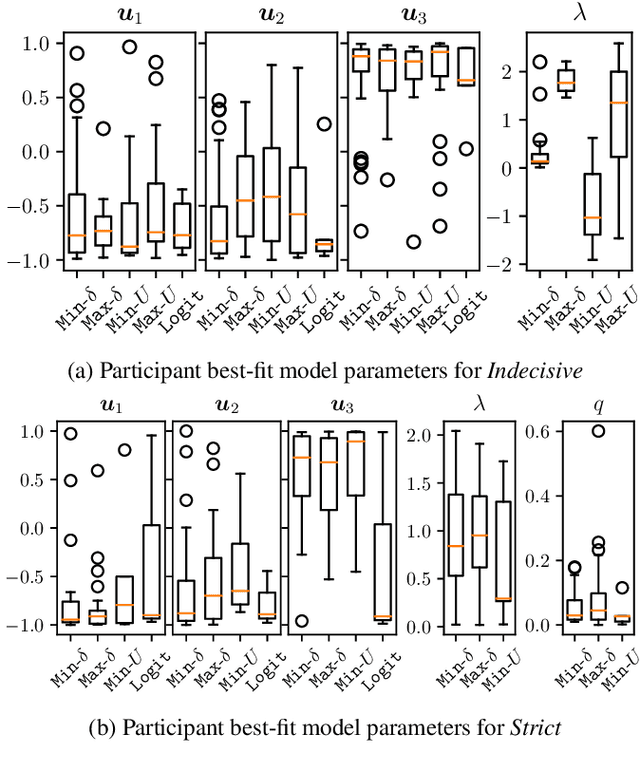
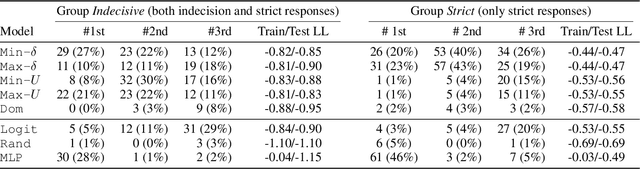
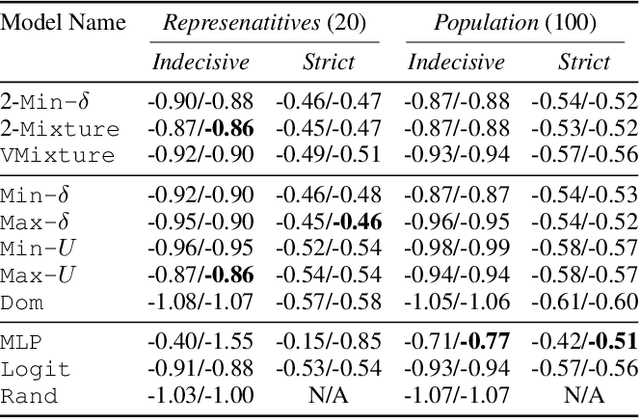
AI systems are often used to make or contribute to important decisions in a growing range of applications, including criminal justice, hiring, and medicine. Since these decisions impact human lives, it is important that the AI systems act in ways which align with human values. Techniques for preference modeling and social choice help researchers learn and aggregate peoples' preferences, which are used to guide AI behavior; thus, it is imperative that these learned preferences are accurate. These techniques often assume that people are willing to express strict preferences over alternatives; which is not true in practice. People are often indecisive, and especially so when their decision has moral implications. The philosophy and psychology literature shows that indecision is a measurable and nuanced behavior -- and that there are several different reasons people are indecisive. This complicates the task of both learning and aggregating preferences, since most of the relevant literature makes restrictive assumptions on the meaning of indecision. We begin to close this gap by formalizing several mathematical \emph{indecision} models based on theories from philosophy, psychology, and economics; these models can be used to describe (indecisive) agent decisions, both when they are allowed to express indecision and when they are not. We test these models using data collected from an online survey where participants choose how to (hypothetically) allocate organs to patients waiting for a transplant.
Improving Policy-Constrained Kidney Exchange via Pre-Screening
Oct 22, 2020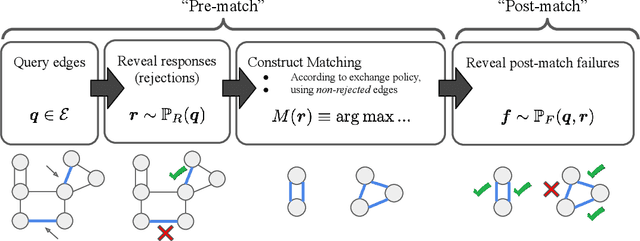
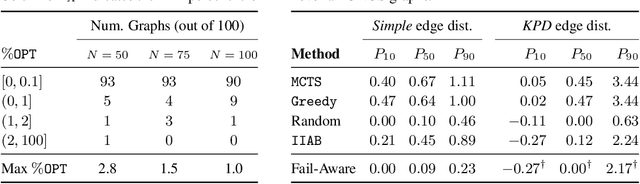
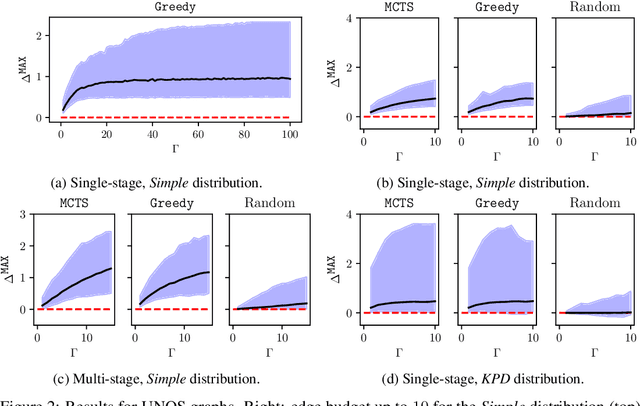
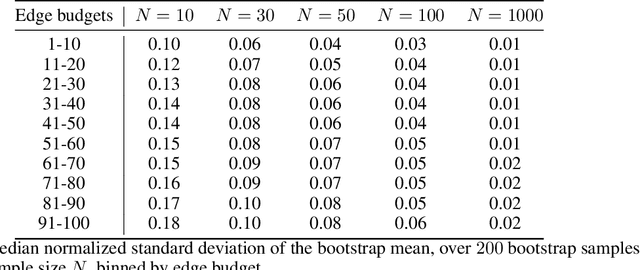
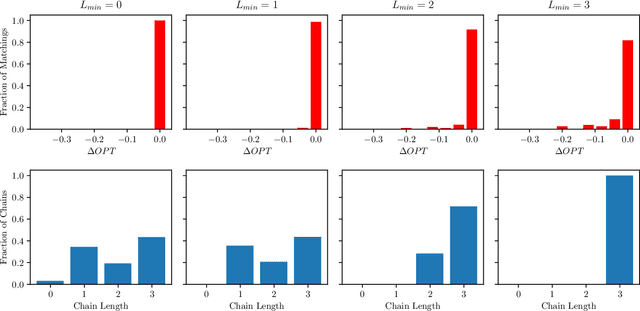
In barter exchanges, participants swap goods with one another without exchanging money; exchanges are often facilitated by a central clearinghouse, with the goal of maximizing the aggregate quality (or number) of swaps. Barter exchanges are subject to many forms of uncertainty--in participant preferences, the feasibility and quality of various swaps, and so on. Our work is motivated by kidney exchange, a real-world barter market in which patients in need of a kidney transplant swap their willing living donors, in order to find a better match. Modern exchanges include 2- and 3-way swaps, making the kidney exchange clearing problem NP-hard. Planned transplants often fail for a variety of reasons--if the donor organ is refused by the recipient's medical team, or if the donor and recipient are found to be medically incompatible. Due to 2- and 3-way swaps, failed transplants can "cascade" through an exchange; one US-based exchange estimated that about 85% of planned transplants failed in 2019. Many optimization-based approaches have been designed to avoid these failures; however most exchanges cannot implement these methods due to legal and policy constraints. Instead we consider a setting where exchanges can query the preferences of certain donors and recipients--asking whether they would accept a particular transplant. We characterize this as a two-stage decision problem, in which the exchange program (a) queries a small number of transplants before committing to a matching, and (b) constructs a matching according to fixed policy. We show that selecting these edges is a challenging combinatorial problem, which is non-monotonic and non-submodular, in addition to being NP-hard. We propose both a greedy heuristic and a Monte Carlo tree search, which outperforms previous approaches, using experiments on both synthetic data and real kidney exchange data from the United Network for Organ Sharing.
Kidney Exchange with Inhomogeneous Edge Existence Uncertainty
Jul 07, 2020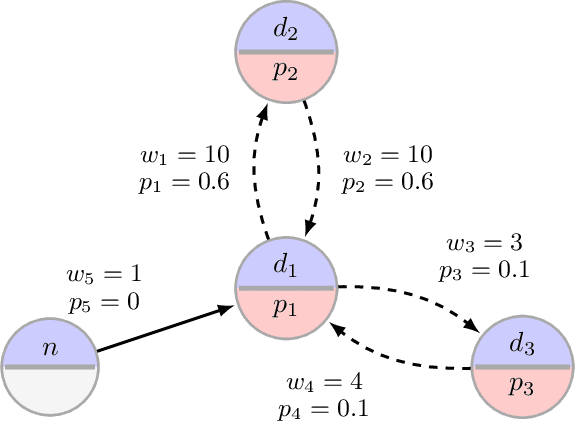

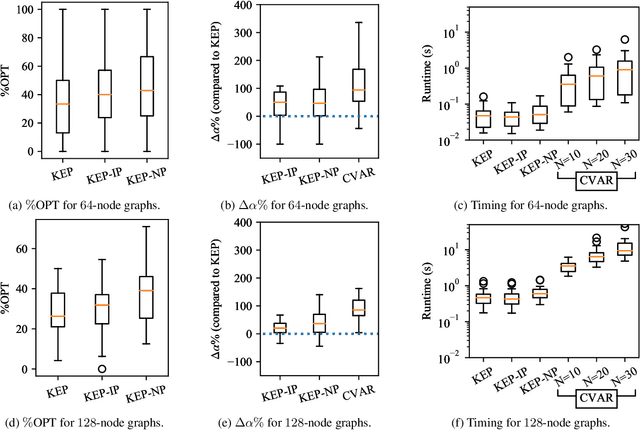
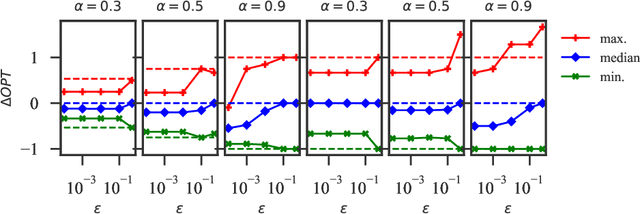
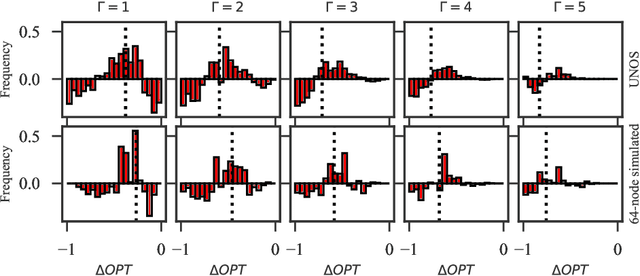
Motivated by kidney exchange, we study a stochastic cycle and chain packing problem, where we aim to identify structures in a directed graph to maximize the expectation of matched edge weights. All edges are subject to failure, and the failures can have nonidentical probabilities. To the best of our knowledge, the state-of-the-art approaches are only tractable when failure probabilities are identical. We formulate a relevant non-convex optimization problem and propose a tractable mixed-integer linear programming reformulation to solve it. In addition, we propose a model that integrates both risks and the expected utilities of the matching by incorporating conditional value at risk (CVaR) into the objective function, providing a robust formulation for this problem. Subsequently, we propose a sample-average-approximation (SAA) based approach to solve this problem. We test our approaches on data from the United Network for Organ Sharing (UNOS) and compare against state-of-the-art approaches. Our model provides better performance with the same running time as a leading deterministic approach (PICEF). Our CVaR extensions with an SAA-based method improves the $\alpha \times 100\%$ ($0<\alpha\leqslant 1$) worst-case performance substantially compared to existing models.
Just How Toxic is Data Poisoning? A Unified Benchmark for Backdoor and Data Poisoning Attacks
Jun 22, 2020

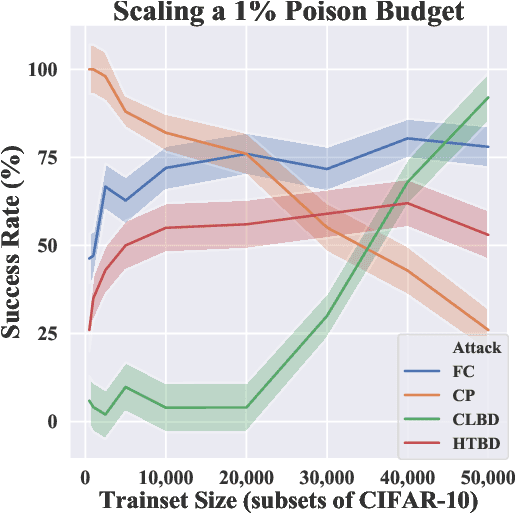
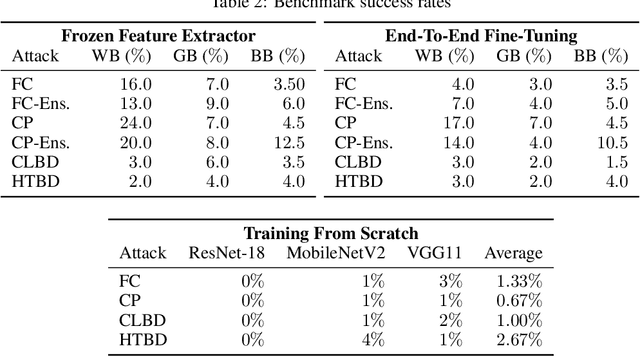
Data poisoning and backdoor attacks manipulate training data in order to cause models to fail during inference. A recent survey of industry practitioners found that data poisoning is the number one concern among threats ranging from model stealing to adversarial attacks. However, we find that the impressive performance evaluations from data poisoning attacks are, in large part, artifacts of inconsistent experimental design. Moreover, we find that existing poisoning methods have been tested in contrived scenarios, and they fail in realistic settings. In order to promote fair comparison in future work, we develop unified benchmarks for data poisoning and backdoor attacks.
Scalable Robust Kidney Exchange
Nov 08, 2018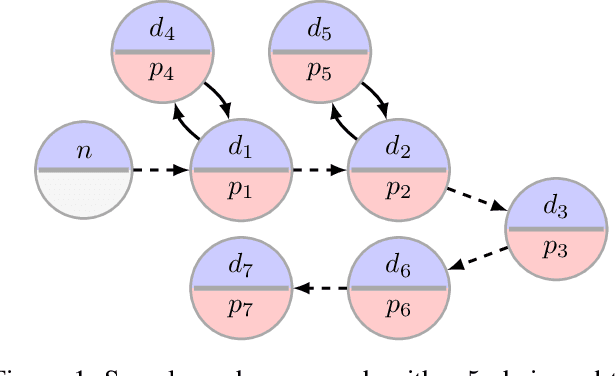
In barter exchanges, participants directly trade their endowed goods in a constrained economic setting without money. Transactions in barter exchanges are often facilitated via a central clearinghouse that must match participants even in the face of uncertainty---over participants, existence and quality of potential trades, and so on. Leveraging robust combinatorial optimization techniques, we address uncertainty in kidney exchange, a real-world barter market where patients swap (in)compatible paired donors. We provide two scalable robust methods to handle two distinct types of uncertainty in kidney exchange---over the quality and the existence of a potential match. The latter case directly addresses a weakness in all stochastic-optimization-based methods to the kidney exchange clearing problem, which all necessarily require explicit estimates of the probability of a transaction existing---a still-unsolved problem in this nascent market. We also propose a novel, scalable kidney exchange formulation that eliminates the need for an exponential-time constraint generation process in competing formulations, maintains provable optimality, and serves as a subsolver for our robust approach. For each type of uncertainty we demonstrate the benefits of robustness on real data from a large, fielded kidney exchange in the United States. We conclude by drawing parallels between robustness and notions of fairness in the kidney exchange setting.