 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferAligner: Inference-Time Alignment for Harmlessness through Cross-Model Guidance
Jan 20, 2024



With the rapid development of large language models (LLMs), they are not only used as general-purpose AI assistants but are also customized through further fine-tuning to meet the requirements of different applications. A pivotal factor in the success of current LLMs is the alignment process. Current alignment methods, such as supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF), focus on training-time alignment and are often complex and cumbersome to implement. Therefore, we develop \textbf{InferAligner}, a novel inference-time alignment method that utilizes cross-model guidance for harmlessness alignment. InferAligner utilizes safety steering vectors extracted from safety-aligned model to modify the activations of the target model when responding to harmful inputs, thereby guiding the target model to provide harmless responses. Experimental results show that our method can be very effectively applied to domain-specific models in finance, medicine, and mathematics, as well as to multimodal large language models (MLLMs) such as LLaVA. It significantly diminishes the Attack Success Rate (ASR) of both harmful instructions and jailbreak attacks, while maintaining almost unchanged performance in downstream tasks.
Watermarking LLMs with Weight Quantization
Oct 17, 2023



Abuse of large language models reveals high risks as large language models are being deployed at an astonishing speed. It is important to protect the model weights to avoid malicious usage that violates licenses of open-source large language models. This paper proposes a novel watermarking strategy that plants watermarks in the quantization process of large language models without pre-defined triggers during inference. The watermark works when the model is used in the fp32 mode and remains hidden when the model is quantized to int8, in this way, the users can only inference the model without further supervised fine-tuning of the model. We successfully plant the watermark into open-source large language model weights including GPT-Neo and LLaMA. We hope our proposed method can provide a potential direction for protecting model weights in the era of large language model applications.
SeqXGPT: Sentence-Level AI-Generated Text Detection
Oct 13, 2023Widely applied large language models (LLMs) can generate human-like content, raising concerns about the abuse of LLMs. Therefore, it is important to build strong AI-generated text (AIGT) detectors. Current works only consider document-level AIGT detection, therefore, in this paper, we first introduce a sentence-level detection challenge by synthesizing a dataset that contains documents that are polished with LLMs, that is, the documents contain sentences written by humans and sentences modified by LLMs. Then we propose \textbf{Seq}uence \textbf{X} (Check) \textbf{GPT}, a novel method that utilizes log probability lists from white-box LLMs as features for sentence-level AIGT detection. These features are composed like \textit{waves} in speech processing and cannot be studied by LLMs. Therefore, we build SeqXGPT based on convolution and self-attention networks. We test it in both sentence and document-level detection challenges. Experimental results show that previous methods struggle in solving sentence-level AIGT detection, while our method not only significantly surpasses baseline methods in both sentence and document-level detection challenges but also exhibits strong generalization capabilities.
PerturbScore: Connecting Discrete and Continuous Perturbations in NLP
Oct 13, 2023



With the rapid development of neural network applications in NLP, model robustness problem is gaining more attention. Different from computer vision, the discrete nature of texts makes it more challenging to explore robustness in NLP. Therefore, in this paper, we aim to connect discrete perturbations with continuous perturbations, therefore we can use such connections as a bridge to help understand discrete perturbations in NLP models. Specifically, we first explore how to connect and measure the correlation between discrete perturbations and continuous perturbations. Then we design a regression task as a PerturbScore to learn the correlation automatically. Through experimental results, we find that we can build a connection between discrete and continuous perturbations and use the proposed PerturbScore to learn such correlation, surpassing previous methods used in discrete perturbation measuring. Further, the proposed PerturbScore can be well generalized to different datasets, perturbation methods, indicating that we can use it as a powerful tool to study model robustness in NLP.
Origin Tracing and Detecting of LLMs
Apr 27, 2023



The extraordinary performance of large language models (LLMs) heightens the importance of detecting whether the context is generated by an AI system. More importantly, while more and more companies and institutions release their LLMs, the origin can be hard to trace. Since LLMs are heading towards the time of AGI, similar to the origin tracing in anthropology, it is of great importance to trace the origin of LLMs. In this paper, we first raise the concern of the origin tracing of LLMs and propose an effective method to trace and detect AI-generated contexts. We introduce a novel algorithm that leverages the contrastive features between LLMs and extracts model-wise features to trace the text origins. Our proposed method works under both white-box and black-box settings therefore can be widely generalized to detect various LLMs.(e.g. can be generalized to detect GPT-3 models without the GPT-3 models). Also, our proposed method requires only limited data compared with the supervised learning methods and can be extended to trace new-coming model origins. We construct extensive experiments to examine whether we can trace the origins of given texts. We provide valuable observations based on the experimental results, such as the difficulty level of AI origin tracing, and the AI origin similarities, and call for ethical concerns of LLM providers. We are releasing all codes and data as a toolkit and benchmark for future AI origin tracing and detecting studies. \footnote{We are releasing all available resource at \url{https://github.com/OpenLMLab/}.}
Kidney Exchange with Inhomogeneous Edge Existence Uncertainty
Jul 07, 2020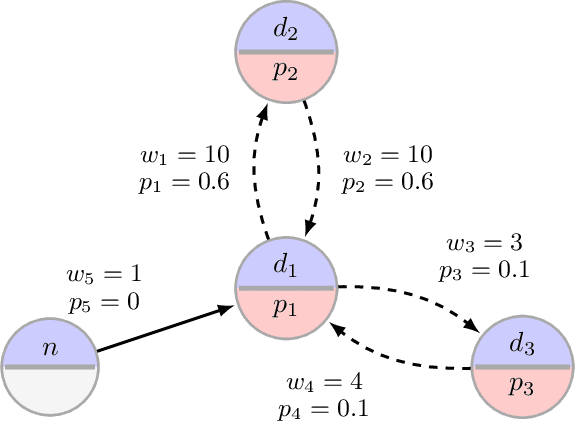

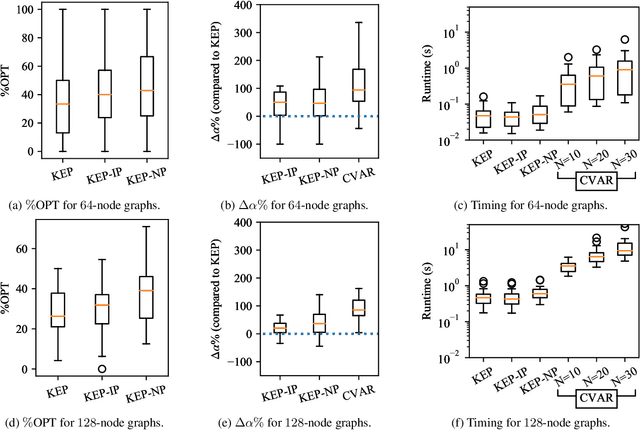
Motivated by kidney exchange, we study a stochastic cycle and chain packing problem, where we aim to identify structures in a directed graph to maximize the expectation of matched edge weights. All edges are subject to failure, and the failures can have nonidentical probabilities. To the best of our knowledge, the state-of-the-art approaches are only tractable when failure probabilities are identical. We formulate a relevant non-convex optimization problem and propose a tractable mixed-integer linear programming reformulation to solve it. In addition, we propose a model that integrates both risks and the expected utilities of the matching by incorporating conditional value at risk (CVaR) into the objective function, providing a robust formulation for this problem. Subsequently, we propose a sample-average-approximation (SAA) based approach to solve this problem. We test our approaches on data from the United Network for Organ Sharing (UNOS) and compare against state-of-the-art approaches. Our model provides better performance with the same running time as a leading deterministic approach (PICEF). Our CVaR extensions with an SAA-based method improves the $\alpha \times 100\%$ ($0<\alpha\leqslant 1$) worst-case performance substantially compared to existing models.
Recommendation Engine for Lower Interest Borrowing on Peer to Peer Lending (P2PL) Platform
Jul 20, 2019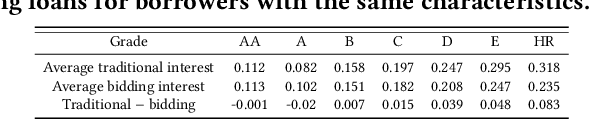



Online Peer to Peer Lending (P2PL) systems connect lenders and borrowers directly, thereby making it convenient to borrow and lend money without intermediaries such as banks. Many recommendation systems have been developed for lenders to achieve higher interest rates and avoid defaulting loans. However, there has not been much research in developing recommendation systems to help borrowers make wise decisions. On P2PL platforms, borrowers can either apply for bidding loans, where the interest rate is determined by lenders bidding on a loan or traditional loans where the P2PL platform determines the interest rate. Different borrower grades -- determining the credit worthiness of borrowers get different interest rates via these two mechanisms. Hence, it is essential to determine which type of loans borrowers should apply for. In this paper, we build a recommendation system that recommends to any new borrower the type of loan they should apply for. Using our recommendation system, any borrower can achieve lowered interest rates with a higher likelihood of getting funded.
A Robust AUC Maximization Framework with Simultaneous Outlier Detection and Feature Selection for Positive-Unlabeled Classification
Mar 18, 2018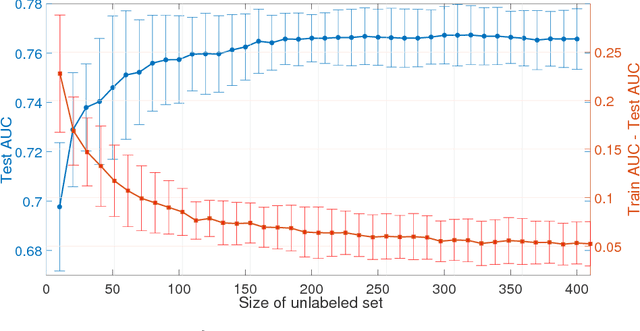
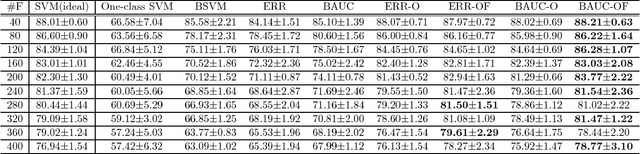
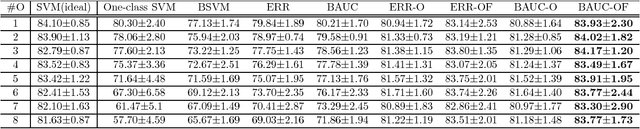
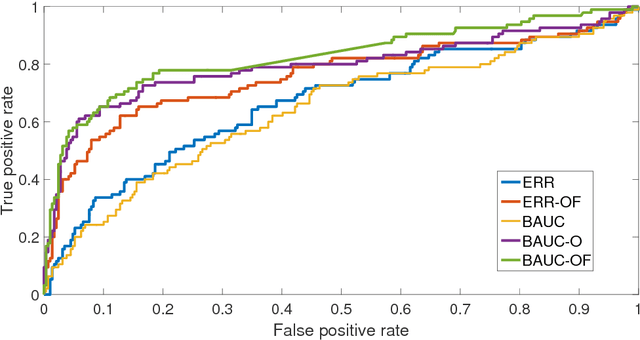
The positive-unlabeled (PU) classification is a common scenario in real-world applications such as healthcare, text classification, and bioinformatics, in which we only observe a few samples labeled as "positive" together with a large volume of "unlabeled" samples that may contain both positive and negative samples. Building robust classifier for the PU problem is very challenging, especially for complex data where the negative samples overwhelm and mislabeled samples or corrupted features exist. To address these three issues, we propose a robust learning framework that unifies AUC maximization (a robust metric for biased labels), outlier detection (for excluding wrong labels), and feature selection (for excluding corrupted features). The generalization error bounds are provided for the proposed model that give valuable insight into the theoretical performance of the method and lead to useful practical guidance, e.g., to train a model, we find that the included unlabeled samples are sufficient as long as the sample size is comparable to the number of positive samples in the training process. Empirical comparisons and two real-world applications on surgical site infection (SSI) and EEG seizure detection are also conducted to show the effectiveness of the proposed model.