 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Generalized Ordinary Differential Equations with Layer-varying Parameters
Sep 21, 2022
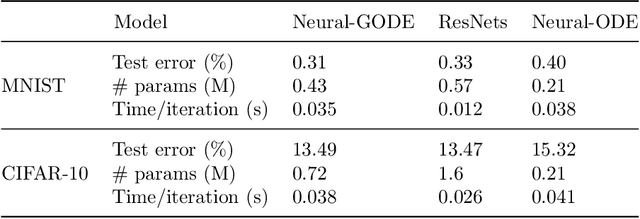

Deep residual networks (ResNets) have shown state-of-the-art performance in various real-world applications. Recently, the ResNets model was reparameterized and interpreted as solutions to a continuous ordinary differential equation or Neural-ODE model. In this study, we propose a neural generalized ordinary differential equation (Neural-GODE) model with layer-varying parameters to further extend the Neural-ODE to approximate the discrete ResNets. Specifically, we use nonparametric B-spline functions to parameterize the Neural-GODE so that the trade-off between the model complexity and computational efficiency can be easily balanced. It is demonstrated that ResNets and Neural-ODE models are special cases of the proposed Neural-GODE model. Based on two benchmark datasets, MNIST and CIFAR-10, we show that the layer-varying Neural-GODE is more flexible and general than the standard Neural-ODE. Furthermore, the Neural-GODE enjoys the computational and memory benefits while performing comparably to ResNets in prediction accuracy.
A Robust AUC Maximization Framework with Simultaneous Outlier Detection and Feature Selection for Positive-Unlabeled Classification
Mar 18, 2018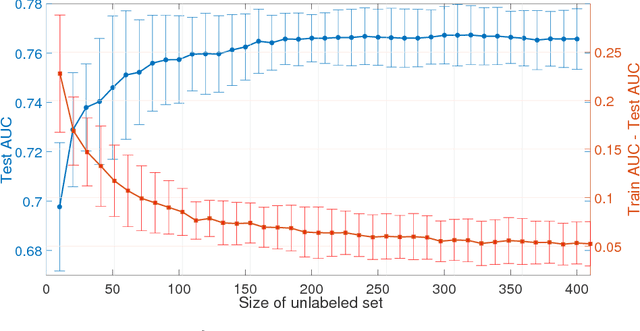
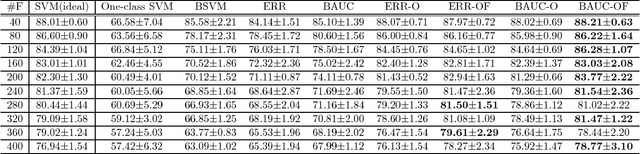
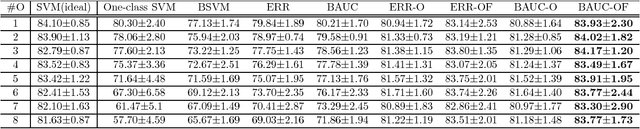
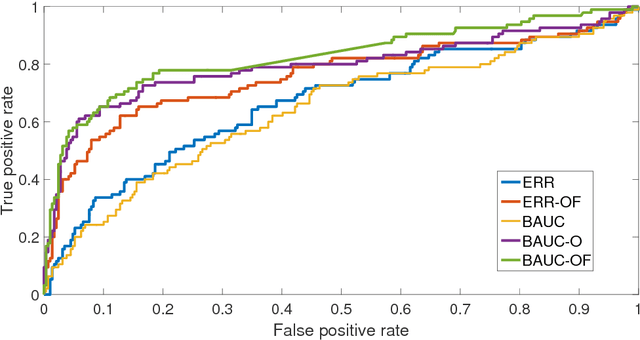
The positive-unlabeled (PU) classification is a common scenario in real-world applications such as healthcare, text classification, and bioinformatics, in which we only observe a few samples labeled as "positive" together with a large volume of "unlabeled" samples that may contain both positive and negative samples. Building robust classifier for the PU problem is very challenging, especially for complex data where the negative samples overwhelm and mislabeled samples or corrupted features exist. To address these three issues, we propose a robust learning framework that unifies AUC maximization (a robust metric for biased labels), outlier detection (for excluding wrong labels), and feature selection (for excluding corrupted features). The generalization error bounds are provided for the proposed model that give valuable insight into the theoretical performance of the method and lead to useful practical guidance, e.g., to train a model, we find that the included unlabeled samples are sufficient as long as the sample size is comparable to the number of positive samples in the training process. Empirical comparisons and two real-world applications on surgical site infection (SSI) and EEG seizure detection are also conducted to show the effectiveness of the proposed model.
Clustering Tree-structured Data on Manifold
Sep 10, 2015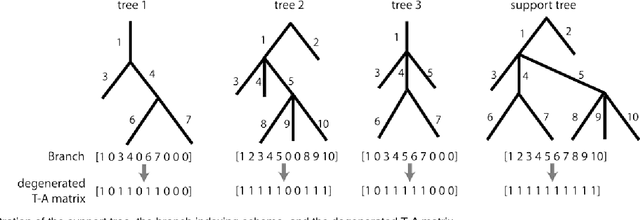
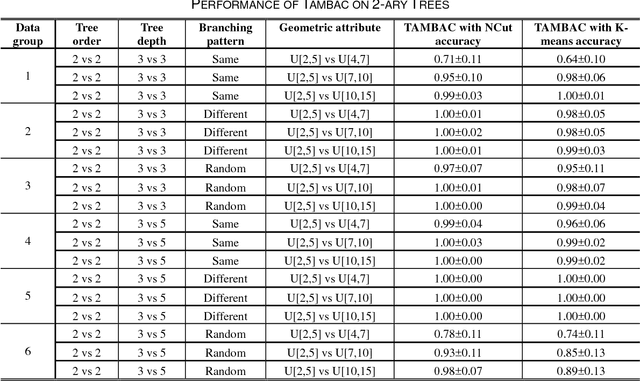
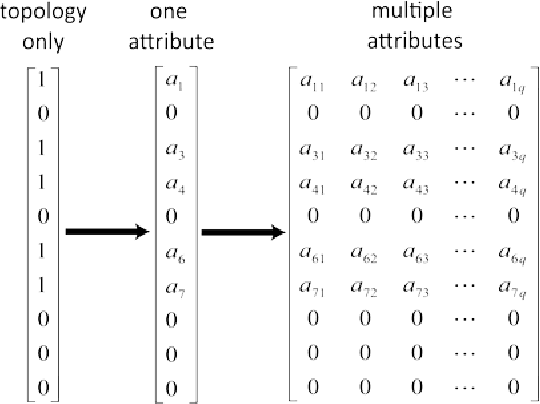
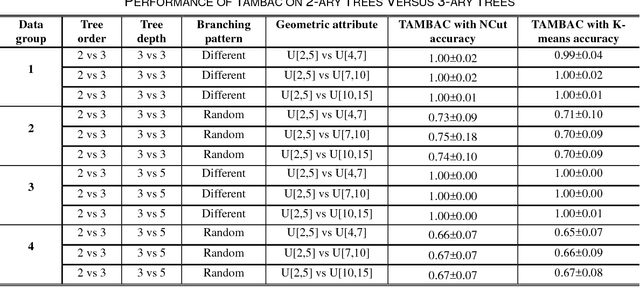
Tree-structured data usually contain both topological and geometrical information, and are necessarily considered on manifold instead of Euclidean space for appropriate data parameterization and analysis. In this study, we propose a novel tree-structured data parameterization, called Topology-Attribute matrix (T-A matrix), so the data clustering task can be conducted on matrix manifold. We incorporate the structure constraints embedded in data into the negative matrix factorization method to determine meta-trees from the T-A matrix, and the signature vector of each single tree can then be extracted by meta-tree decomposition. The meta-tree space turns out to be a cone space, in which we explore the distance metric and implement the clustering algorithm based on the concepts like Fr\'echet mean. Finally, the T-A matrix based clustering (TAMBAC) framework is evaluated and compared using both simulated data and real retinal images to illustrate its efficiency and accuracy.