 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Probability Aggregation Clustering
Feb 27, 2025Traditional clustering methods typically focus on either cluster-wise global clustering or point-wise local clustering to reveal the intrinsic structures in unlabeled data. Global clustering optimizes an objective function to explore the relationships between clusters, but this approach may inevitably lead to coarse partition. In contrast, local clustering heuristically groups data based on detailed point relationships, but it tends to be less coherence and efficient. To bridge the gap between these two concepts and utilize the strengths of both, we propose Graph Probability Aggregation Clustering (GPAC), a graph-based fuzzy clustering algorithm. GPAC unifies the global clustering objective function with a local clustering constraint. The entire GPAC framework is formulated as a multi-constrained optimization problem, which can be solved using the Lagrangian method. Through the optimization process, the probability of a sample belonging to a specific cluster is iteratively calculated by aggregating information from neighboring samples within the graph. We incorporate a hard assignment variable into the objective function to further improve the convergence and stability of optimization. Furthermore, to efficiently handle large-scale datasets, we introduce an acceleration program that reduces the computational complexity from quadratic to linear, ensuring scalability. Extensive experiments conducted on synthetic, real-world, and deep learning datasets demonstrate that GPAC not only exceeds existing state-of-the-art methods in clustering performance but also excels in computational efficiency, making it a powerful tool for complex clustering challenges.
Set a Thief to Catch a Thief: Combating Label Noise through Noisy Meta Learning
Feb 22, 2025Learning from noisy labels (LNL) aims to train high-performance deep models using noisy datasets. Meta learning based label correction methods have demonstrated remarkable performance in LNL by designing various meta label rectification tasks. However, extra clean validation set is a prerequisite for these methods to perform label correction, requiring extra labor and greatly limiting their practicality. To tackle this issue, we propose a novel noisy meta label correction framework STCT, which counterintuitively uses noisy data to correct label noise, borrowing the spirit in the saying ``Set a Thief to Catch a Thief''. The core idea of STCT is to leverage noisy data which is i.i.d. with the training data as a validation set to evaluate model performance and perform label correction in a meta learning framework, eliminating the need for extra clean data. By decoupling the complex bi-level optimization in meta learning into representation learning and label correction, STCT is solved through an alternating training strategy between noisy meta correction and semi-supervised representation learning. Extensive experiments on synthetic and real-world datasets demonstrate the outstanding performance of STCT, particularly in high noise rate scenarios. STCT achieves 96.9% label correction and 95.2% classification performance on CIFAR-10 with 80% symmetric noise, significantly surpassing the current state-of-the-art.
Deep Probability Aggregation Clustering
Jul 07, 2024Combining machine clustering with deep models has shown remarkable superiority in deep clustering. It modifies the data processing pipeline into two alternating phases: feature clustering and model training. However, such alternating schedule may lead to instability and computational burden issues. We propose a centerless clustering algorithm called Probability Aggregation Clustering (PAC) to proactively adapt deep learning technologies, enabling easy deployment in online deep clustering. PAC circumvents the cluster center and aligns the probability space and distribution space by formulating clustering as an optimization problem with a novel objective function. Based on the computation mechanism of the PAC, we propose a general online probability aggregation module to perform stable and flexible feature clustering over mini-batch data and further construct a deep visual clustering framework deep PAC (DPAC). Extensive experiments demonstrate that PAC has superior clustering robustness and performance and DPAC remarkably outperforms the state-of-the-art deep clustering methods.
A Multi-module Robust Method for Transient Stability Assessment against False Label Injection Cyberattacks
Jun 10, 2024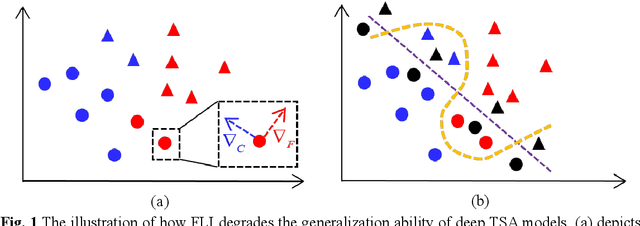
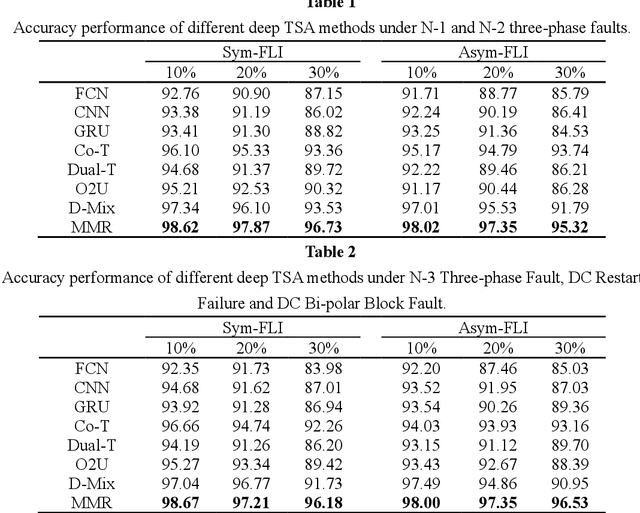
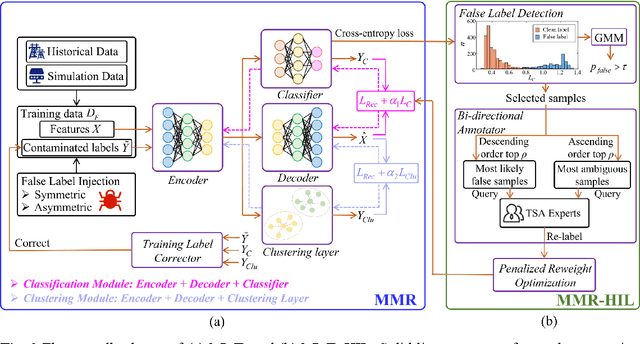
The success of deep learning in transient stability assessment (TSA) heavily relies on high-quality training data. However, the label information in TSA datasets is vulnerable to contamination through false label injection (FLI) cyberattacks, resulting in degraded performance of deep TSA models. To address this challenge, a Multi-Module Robust TSA method (MMR) is proposed to rectify the supervised training process misguided by FLI in an unsupervised manner. In MMR, a supervised classification module and an unsupervised clustering module are alternatively trained to improve the clustering friendliness of representation leaning, thereby achieving accurate clustering assignments. Leveraging the clustering assignments, we construct a training label corrector to rectify the injected false labels and progressively enhance robustness and resilience against FLI. However, there is still a gap on accuracy and convergence speed between MMR and FLI-free deep TSA models. To narrow this gap, we further propose a human-in-the-loop training strategy, named MMR-HIL. In MMR-HIL, potential false samples can be detected by modeling the training loss with a Gaussian distribution. From these samples, the most likely false samples and most ambiguous samples are re-labeled by a TSA experts guided bi-directional annotator and then subjected to penalized optimization, aimed at improving accuracy and convergence speed. Extensive experiments indicate that MMR and MMR-HIL both exhibit powerful robustness against FLI in TSA performance. Moreover, the contaminated labels can also be effectively corrected, demonstrating superior resilience of the proposed methods.
An Interpretable Power System Transient Stability Assessment Method with Expert Guiding Neural-Regression-Tree
Apr 03, 2024



Deep learning based transient stability assessment (TSA) has achieved great success, yet the lack of interpretability hinders its industrial application. Although a great number of studies have tried to explore the interpretability of network solutions, many problems still remain unsolved: (1) the difference between the widely accepted power system knowledge and the generated interpretive rules is large, (2) the probability characteristics of the neural network have not been fully considered during generating the interpretive rules, (3) the cost of the trade-off between accuracy and interpretability is too heavy to take. To address these issues, an interpretable power system Transient Stability Assessment method with Expert guiding Neural-Regression-Tree (TSA-ENRT) is proposed. TSA-ENRT utilizes an expert guiding nonlinear regression tree to approximate the neural network prediction and the neural network can be explained by the interpretive rules generated by the tree model. The nonlinearity of the expert guiding nonlinear regression tree is endowed with the extracted knowledge from a simple two-machine three-bus power system, which forms an expert knowledge base and thus the generated interpretive rules are more consistent with human cognition. Besides, the expert guiding tree model can build a bridge between the interpretive rules and the probability prediction of neural network in a regression way. By regularizing the neural network with the average decision length of ENRT, the association of the neural network and tree model is constructed in the model training level which provides a better trade-off between accuracy and interpretability. Extensive experiments indicate the interpretive rules generated by the proposed TSA-ENRT are highly consistent with the neural network prediction and more agreed with human expert cognition.
B-LSTM-MIONet: Bayesian LSTM-based Neural Operators for Learning the Response of Complex Dynamical Systems to Length-Variant Multiple Input Functions
Nov 29, 2023Deep Operator Network (DeepONet) is a neural network framework for learning nonlinear operators such as those from ordinary differential equations (ODEs) describing complex systems. Multiple-input deep neural operators (MIONet) extended DeepONet to allow multiple input functions in different Banach spaces. MIONet offers flexibility in training dataset grid spacing, without constraints on output location. However, it requires offline inputs and cannot handle varying sequence lengths in testing datasets, limiting its real-time application in dynamic complex systems. This work redesigns MIONet, integrating Long Short Term Memory (LSTM) to learn neural operators from time-dependent data. This approach overcomes data discretization constraints and harnesses LSTM's capability with variable-length, real-time data. Factors affecting learning performance, like algorithm extrapolation ability are presented. The framework is enhanced with uncertainty quantification through a novel Bayesian method, sampling from MIONet parameter distributions. Consequently, we develop the B-LSTM-MIONet, incorporating LSTM's temporal strengths with Bayesian robustness, resulting in a more precise and reliable model for noisy datasets.
Self-Evolutionary Clustering
Feb 21, 2022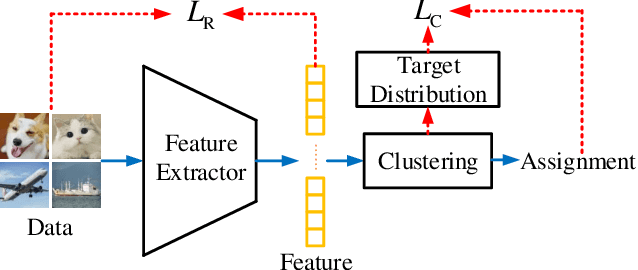
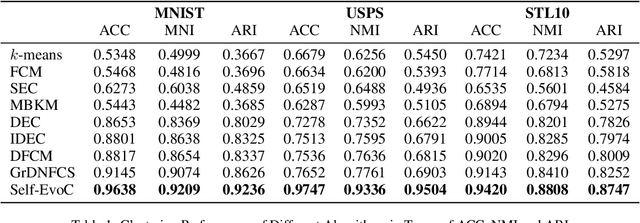
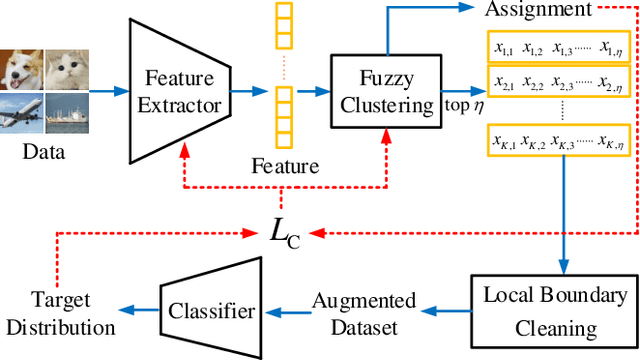

Deep clustering outperforms conventional clustering by mutually promoting representation learning and cluster assignment. However, most existing deep clustering methods suffer from two major drawbacks. First, most cluster assignment methods are based on simple distance comparison and highly dependent on the target distribution generated by a handcrafted nonlinear mapping. These facts largely limit the possible performance that deep clustering methods can reach. Second, the clustering results can be easily guided towards wrong direction by the misassigned samples in each cluster. The existing deep clustering methods are incapable of discriminating such samples. To address these issues, a novel modular Self-Evolutionary Clustering (Self-EvoC) framework is constructed, which boosts the clustering performance by classification in a self-supervised manner. Fuzzy theory is used to score the sample membership with probability which evaluates the intermediate clustering result certainty of each sample. Based on which, the most reliable samples can be selected and augmented. The augmented data are employed to fine-tune an off-the-shelf deep network classifier with the labels from the clustering, which results in a model to generate the target distribution. The proposed framework can efficiently discriminate sample outliers and generate better target distribution with the assistance of self-supervised classifier. Extensive experiments indicate that the Self-EvoC remarkably outperforms state-of-the-art deep clustering methods on three benchmark datasets.
Feature Selection Convolutional Neural Networks for Visual Tracking
Nov 09, 2018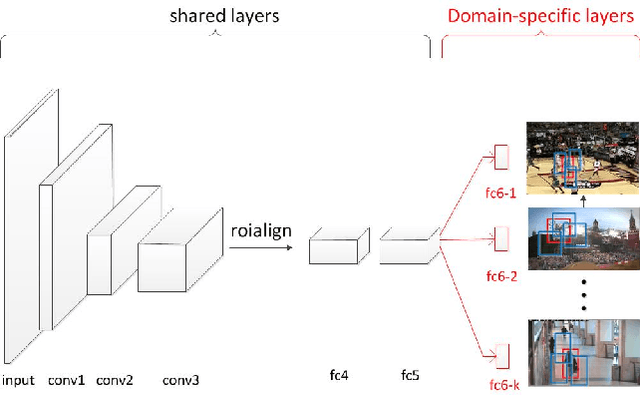
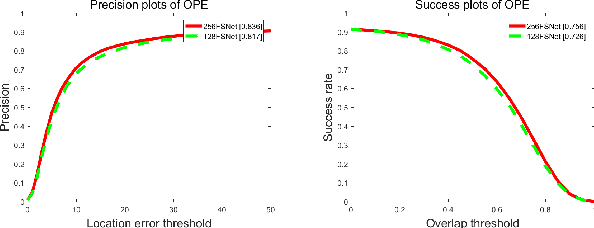
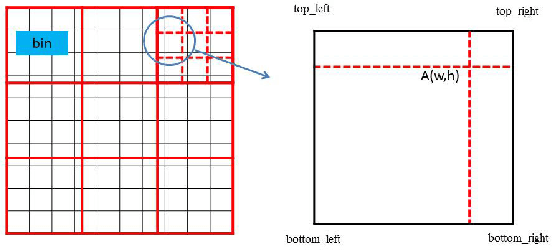

Most of the existing tracking methods based on CNN(convolutional neural networks) are too slow for real-time application despite the excellent tracking precision compared with the traditional ones. Moreover, neural networks are memory intensive which will take up lots of hardware resources. In this paper, a feature selection visual tracking algorithm combining CNN based MDNet(Multi-Domain Network) and RoIAlign was developed. We find that there is a lot of redundancy in feature maps from convolutional layers. So valid feature maps are selected by mutual information and others are abandoned which can reduce the complexity and computation of the network and do not affect the precision. The major problem of MDNet also lies in the time efficiency. Considering the computational complexity of MDNet is mainly caused by the large amount of convolution operations and fine-tuning of the network during tracking, a RoIAlign layer which could conduct the convolution over the whole image instead of each RoI is added to accelerate the convolution and a new strategy of fine-tuning the fully-connected layers is used to accelerate the update. With RoIAlign employed, the computation speed has been increased and it shows greater precision than RoIPool. Because RoIAlign can process float number coordinates by bilinear interpolation. These strategies can accelerate the processing, reduce the complexity with very low impact on precision and it can run at around 10 fps(while the speed of MDNet is about 1 fps). The proposed algorithm has been evaluated on a benchmark: OTB100, on which high precision and speed have been obtained.
Fast Dynamic Convolutional Neural Networks for Visual Tracking
Jul 25, 2018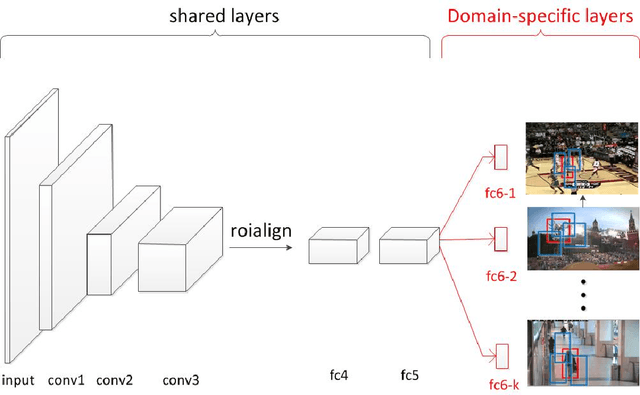

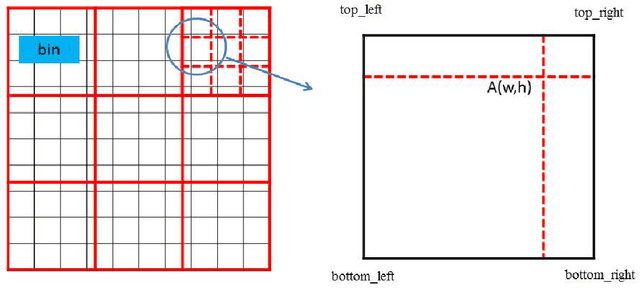
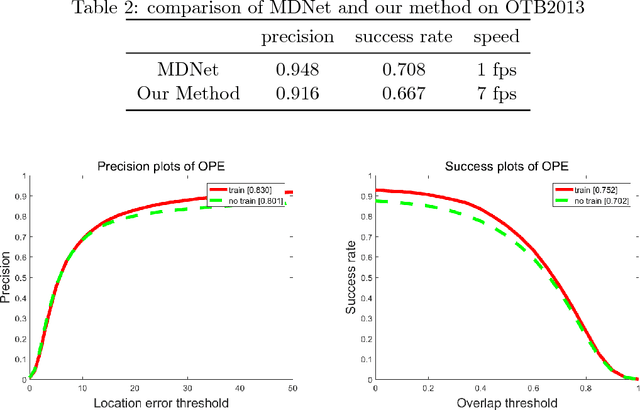
Most of the existing tracking methods based on CNN(convolutional neural networks) are too slow for real-time application despite the excellent tracking precision compared with the traditional ones. In this paper, a fast dynamic visual tracking algorithm combining CNN based MDNet(Multi-Domain Network) and RoIAlign was developed. The major problem of MDNet also lies in the time efficiency. Considering the computational complexity of MDNet is mainly caused by the large amount of convolution operations and fine-tuning of the network during tracking, a RoIPool layer which could conduct the convolution over the whole image instead of each RoI is added to accelerate the convolution and a new strategy of fine-tuning the fully-connected layers is used to accelerate the update. With RoIPool employed, the computation speed has been increased but the tracking precision has dropped simultaneously. RoIPool could lose some positioning precision because it can not handle locations represented by floating numbers. So RoIAlign, instead of RoIPool, which can process floating numbers of locations by bilinear interpolation has been added to the network. The results show the target localization precision has been improved and it hardly increases the computational cost. These strategies can accelerate the processing and make it 7x faster than MDNet with very low impact on precision and it can run at around 7 fps. The proposed algorithm has been evaluated on two benchmarks: OTB100 and VOT2016, on which high precision and speed have been obtained. The influence of the network structure and training data are also discussed with experiments.
Clustering Tree-structured Data on Manifold
Sep 10, 2015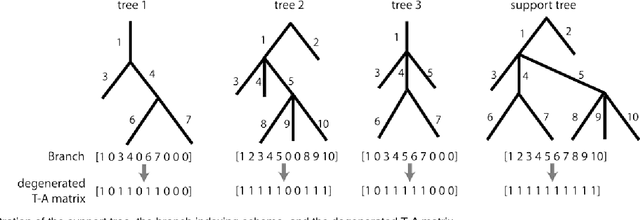
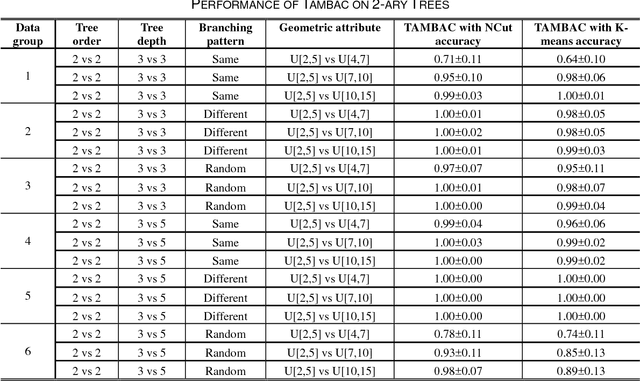
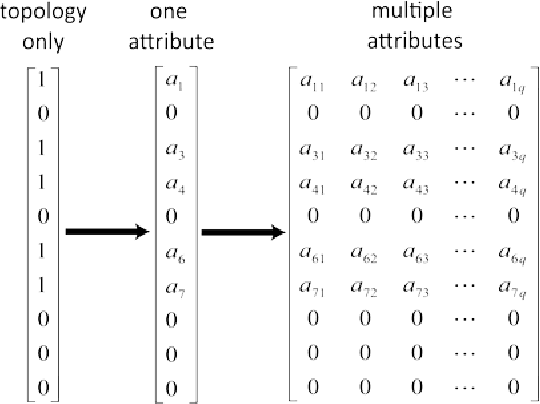
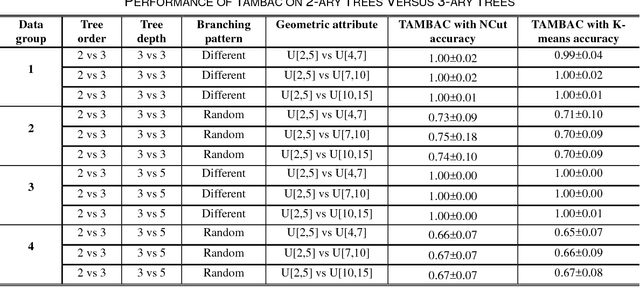
Tree-structured data usually contain both topological and geometrical information, and are necessarily considered on manifold instead of Euclidean space for appropriate data parameterization and analysis. In this study, we propose a novel tree-structured data parameterization, called Topology-Attribute matrix (T-A matrix), so the data clustering task can be conducted on matrix manifold. We incorporate the structure constraints embedded in data into the negative matrix factorization method to determine meta-trees from the T-A matrix, and the signature vector of each single tree can then be extracted by meta-tree decomposition. The meta-tree space turns out to be a cone space, in which we explore the distance metric and implement the clustering algorithm based on the concepts like Fr\'echet mean. Finally, the T-A matrix based clustering (TAMBAC) framework is evaluated and compared using both simulated data and real retinal images to illustrate its efficiency and accuracy.