 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Chains to Graphs: Self-Structured Reasoning for General-Domain LLMs
Jan 07, 2026Large Language Models (LLMs) show strong reasoning ability in open-domain question answering, yet their reasoning processes are typically linear and often logically inconsistent. In contrast, real-world reasoning requires integrating multiple premises and solving subproblems in parallel. Existing methods, such as Chain-of-Thought (CoT), express reasoning in a linear textual form, which may appear coherent but frequently leads to inconsistent conclusions. Recent approaches rely on externally provided graphs and do not explore how LLMs can construct and use their own graph-structured reasoning, particularly in open-domain QA. To fill this gap, we novelly explore graph-structured reasoning of LLMs in general-domain question answering. We propose Self-Graph Reasoning (SGR), a framework that enables LLMs to explicitly represent their reasoning process as a structured graph before producing the final answer. We further construct a graph-structured reasoning dataset that merges multiple candidate reasoning graphs into refined graph structures for model training. Experiments on five QA benchmarks across both general and specialized domains show that SGR consistently improves reasoning consistency and yields a 17.74% gain over the base model. The LLaMA-3.3-70B model fine-tuned with SGR performs comparably to GPT-4o and surpasses Claude-3.5-Haiku, demonstrating the effectiveness of graph-structured reasoning.
MDSEval: A Meta-Evaluation Benchmark for Multimodal Dialogue Summarization
Oct 02, 2025Multimodal Dialogue Summarization (MDS) is a critical task with wide-ranging applications. To support the development of effective MDS models, robust automatic evaluation methods are essential for reducing both cost and human effort. However, such methods require a strong meta-evaluation benchmark grounded in human annotations. In this work, we introduce MDSEval, the first meta-evaluation benchmark for MDS, consisting image-sharing dialogues, corresponding summaries, and human judgments across eight well-defined quality aspects. To ensure data quality and richfulness, we propose a novel filtering framework leveraging Mutually Exclusive Key Information (MEKI) across modalities. Our work is the first to identify and formalize key evaluation dimensions specific to MDS. We benchmark state-of-the-art modal evaluation methods, revealing their limitations in distinguishing summaries from advanced MLLMs and their susceptibility to various bias.
When Personalization Meets Reality: A Multi-Faceted Analysis of Personalized Preference Learning
Feb 26, 2025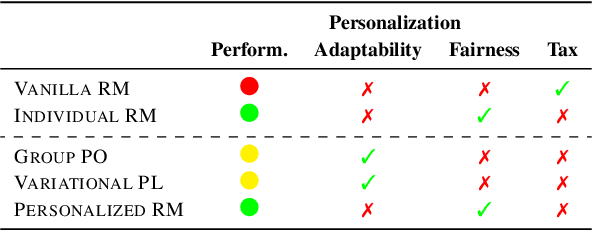
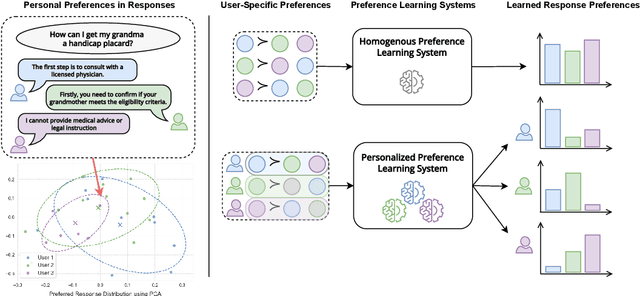

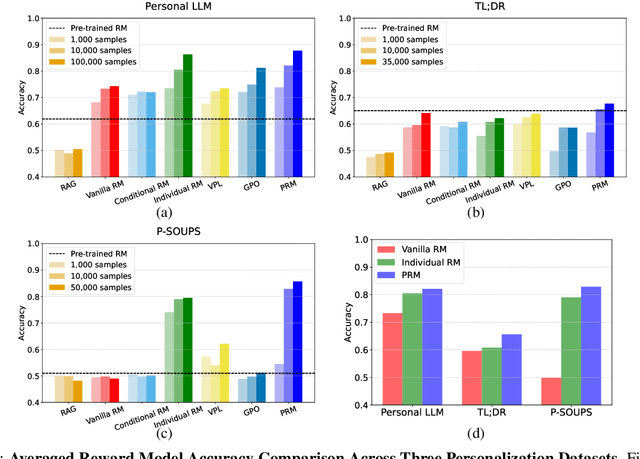
While Reinforcement Learning from Human Feedback (RLHF) is widely used to align Large Language Models (LLMs) with human preferences, it typically assumes homogeneous preferences across users, overlooking diverse human values and minority viewpoints. Although personalized preference learning addresses this by tailoring separate preferences for individual users, the field lacks standardized methods to assess its effectiveness. We present a multi-faceted evaluation framework that measures not only performance but also fairness, unintended effects, and adaptability across varying levels of preference divergence. Through extensive experiments comparing eight personalization methods across three preference datasets, we demonstrate that performance differences between methods could reach 36% when users strongly disagree, and personalization can introduce up to 20% safety misalignment. These findings highlight the critical need for holistic evaluation approaches to advance the development of more effective and inclusive preference learning systems.
GraphCheck: Breaking Long-Term Text Barriers with Extracted Knowledge Graph-Powered Fact-Checking
Feb 23, 2025Large language models (LLMs) are widely used, but they often generate subtle factual errors, especially in long-form text. These errors are fatal in some specialized domains such as medicine. Existing fact-checking with grounding documents methods face two main challenges: (1) they struggle to understand complex multihop relations in long documents, often overlooking subtle factual errors; (2) most specialized methods rely on pairwise comparisons, requiring multiple model calls, leading to high resource and computational costs. To address these challenges, we propose \textbf{\textit{GraphCheck}}, a fact-checking framework that uses extracted knowledge graphs to enhance text representation. Graph Neural Networks further process these graphs as a soft prompt, enabling LLMs to incorporate structured knowledge more effectively. Enhanced with graph-based reasoning, GraphCheck captures multihop reasoning chains which are often overlooked by existing methods, enabling precise and efficient fact-checking in a single inference call. Experimental results on seven benchmarks spanning both general and medical domains demonstrate a 6.1\% overall improvement over baseline models. Notably, GraphCheck outperforms existing specialized fact-checkers and achieves comparable performance with state-of-the-art LLMs, such as DeepSeek-V3 and OpenAI-o1, with significantly fewer parameters.
STAR: Spatial-Temporal Augmentation with Text-to-Video Models for Real-World Video Super-Resolution
Jan 06, 2025Image diffusion models have been adapted for real-world video super-resolution to tackle over-smoothing issues in GAN-based methods. However, these models struggle to maintain temporal consistency, as they are trained on static images, limiting their ability to capture temporal dynamics effectively. Integrating text-to-video (T2V) models into video super-resolution for improved temporal modeling is straightforward. However, two key challenges remain: artifacts introduced by complex degradations in real-world scenarios, and compromised fidelity due to the strong generative capacity of powerful T2V models (\textit{e.g.}, CogVideoX-5B). To enhance the spatio-temporal quality of restored videos, we introduce\textbf{~\name} (\textbf{S}patial-\textbf{T}emporal \textbf{A}ugmentation with T2V models for \textbf{R}eal-world video super-resolution), a novel approach that leverages T2V models for real-world video super-resolution, achieving realistic spatial details and robust temporal consistency. Specifically, we introduce a Local Information Enhancement Module (LIEM) before the global attention block to enrich local details and mitigate degradation artifacts. Moreover, we propose a Dynamic Frequency (DF) Loss to reinforce fidelity, guiding the model to focus on different frequency components across diffusion steps. Extensive experiments demonstrate\textbf{~\name}~outperforms state-of-the-art methods on both synthetic and real-world datasets.
Prompt Compression for Large Language Models: A Survey
Oct 17, 2024Leveraging large language models (LLMs) for complex natural language tasks typically requires long-form prompts to convey detailed requirements and information, which results in increased memory usage and inference costs. To mitigate these challenges, multiple efficient methods have been proposed, with prompt compression gaining significant research interest. This survey provides an overview of prompt compression techniques, categorized into hard prompt methods and soft prompt methods. First, the technical approaches of these methods are compared, followed by an exploration of various ways to understand their mechanisms, including the perspectives of attention optimization, Parameter-Efficient Fine-Tuning (PEFT), modality integration, and new synthetic language. We also examine the downstream adaptations of various prompt compression techniques. Finally, the limitations of current prompt compression methods are analyzed, and several future directions are outlined, such as optimizing the compression encoder, combining hard and soft prompts methods, and leveraging insights from multimodality.
Aligning with Logic: Measuring, Evaluating and Improving Logical Consistency in Large Language Models
Oct 05, 2024



Recent research in Large Language Models (LLMs) has shown promising progress related to LLM alignment with human preferences. LLM-empowered decision-making systems are expected to be predictable, reliable and trustworthy, which implies being free from paradoxes or contradictions that could undermine their credibility and validity. However, LLMs still exhibit inconsistent and biased behaviour when making decisions or judgements. In this work, we focus on studying logical consistency of LLMs as a prerequisite for more reliable and trustworthy systems. Logical consistency ensures that decisions are based on a stable and coherent understanding of the problem, reducing the risk of erratic or contradictory outputs. We first propose a universal framework to quantify the logical consistency via three fundamental proxies: transitivity, commutativity and negation invariance. We then evaluate logical consistency, using the defined measures, of a wide range of LLMs, demonstrating that it can serve as a strong proxy for overall robustness. Additionally, we introduce a data refinement and augmentation technique that enhances the logical consistency of LLMs without sacrificing alignment to human preferences. It augments noisy and sparse pairwise-comparison annotations by estimating a partially or totally ordered preference rankings using rank aggregation methods. Finally, we show that logical consistency impacts the performance of LLM-based logic-dependent algorithms, where LLMs serve as logical operators.
Measuring, Evaluating and Improving Logical Consistency in Large Language Models
Oct 03, 2024Recent research in Large Language Models (LLMs) has shown promising progress related to LLM alignment with human preferences. LLM-empowered decision-making systems are expected to be predictable, reliable and trustworthy, which implies being free from paradoxes or contradictions that could undermine their credibility and validity. However, LLMs still exhibit inconsistent and biased behaviour when making decisions or judgements. In this work, we focus on studying logical consistency of LLMs as a prerequisite for more reliable and trustworthy systems. Logical consistency ensures that decisions are based on a stable and coherent understanding of the problem, reducing the risk of erratic or contradictory outputs. We first propose a universal framework to quantify the logical consistency via three fundamental proxies: transitivity, commutativity and negation invariance. We then evaluate logical consistency, using the defined measures, of a wide range of LLMs, demonstrating that it can serve as a strong proxy for overall robustness. Additionally, we introduce a data refinement and augmentation technique that enhances the logical consistency of LLMs without sacrificing alignment to human preferences. It augments noisy and sparse pairwise-comparison annotations by estimating a partially or totally ordered preference rankings using rank aggregation methods. Finally, we show that logical consistency impacts the performance of LLM-based logic-dependent algorithms, where LLMs serve as logical operators.
Full-Duplex ISAC-Enabled D2D Underlaid Cellular Networks: Joint Transceiver Beamforming and Power Allocation
Aug 22, 2024



Integrating device-to-device (D2D) communication into cellular networks can significantly reduce the transmission burden on base stations (BSs). Besides, integrated sensing and communication (ISAC) is envisioned as a key feature in future wireless networks. In this work, we consider a full-duplex ISAC- based D2D underlaid system, and propose a joint beamforming and power allocation scheme to improve the performance of the coexisting ISAC and D2D networks. To enhance spectral efficiency, a sum rate maximization problem is formulated for the full-duplex ISAC-based D2D underlaid system, which is non-convex. To solve the non-convex optimization problem, we propose a successive convex approximation (SCA)-based iterative algorithm and prove its convergence. Numerical results are provided to validate the effectiveness of the proposed scheme with the iterative algorithm, demonstrating that the proposed scheme outperforms state-of-the-art ones in both communication and sensing performance.
MR-BEN: A Comprehensive Meta-Reasoning Benchmark for Large Language Models
Jun 20, 2024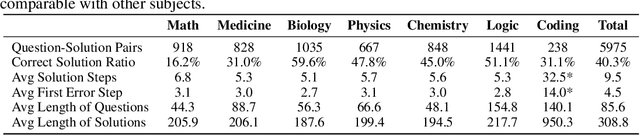
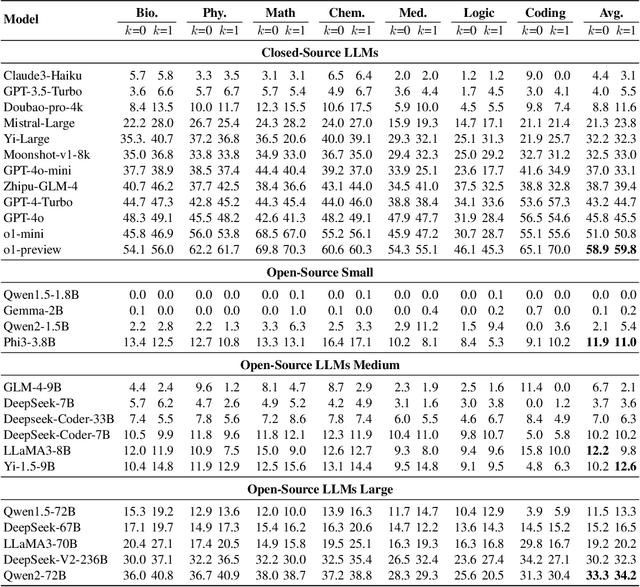
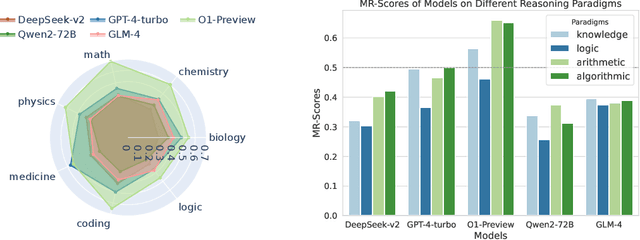
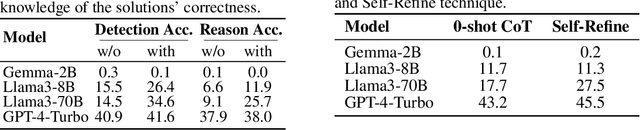
Large language models (LLMs) have shown increasing capability in problem-solving and decision-making, largely based on the step-by-step chain-of-thought reasoning processes. However, it has been increasingly challenging to evaluate the reasoning capability of LLMs. Concretely, existing outcome-based benchmarks begin to saturate and become less sufficient to monitor the progress. To this end, we present a process-based benchmark MR-BEN that demands a meta reasoning skill, where LMs are asked to locate and analyse potential errors in automatically generated reasoning steps. MR-BEN is a comprehensive benchmark comprising 5,975 questions collected from human experts, covering various subjects such as physics, chemistry, logic, coding, and more. Through our designed metrics for assessing meta-reasoning on this benchmark, we identify interesting limitations and weaknesses of current LLMs (open-source and closed-source models). For example, open-source models are seemingly comparable to GPT-4 on outcome-based benchmarks, but they lag far behind on our benchmark, revealing the underlying reasoning capability gap between them. Our dataset and codes are available on https://randolph-zeng.github.io/Mr-Ben.github.io/.