 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTMamba: Enhancing Multi-Task Dense Scene Understanding by Mamba-Based Decoders
Jul 02, 2024Multi-task dense scene understanding, which learns a model for multiple dense prediction tasks, has a wide range of application scenarios. Modeling long-range dependency and enhancing cross-task interactions are crucial to multi-task dense prediction. In this paper, we propose MTMamba, a novel Mamba-based architecture for multi-task scene understanding. It contains two types of core blocks: self-task Mamba (STM) block and cross-task Mamba (CTM) block. STM handles long-range dependency by leveraging Mamba, while CTM explicitly models task interactions to facilitate information exchange across tasks. Experiments on NYUDv2 and PASCAL-Context datasets demonstrate the superior performance of MTMamba over Transformer-based and CNN-based methods. Notably, on the PASCAL-Context dataset, MTMamba achieves improvements of +2.08, +5.01, and +4.90 over the previous best method in the tasks of semantic segmentation, human parsing, and object boundary detection, respectively. The code is available at \url{https://github.com/EnVision-Research/MTMamba}.
MR-BEN: A Comprehensive Meta-Reasoning Benchmark for Large Language Models
Jun 20, 2024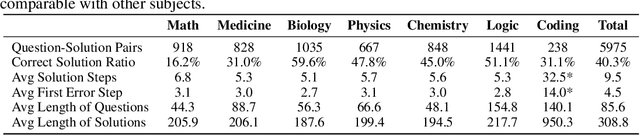
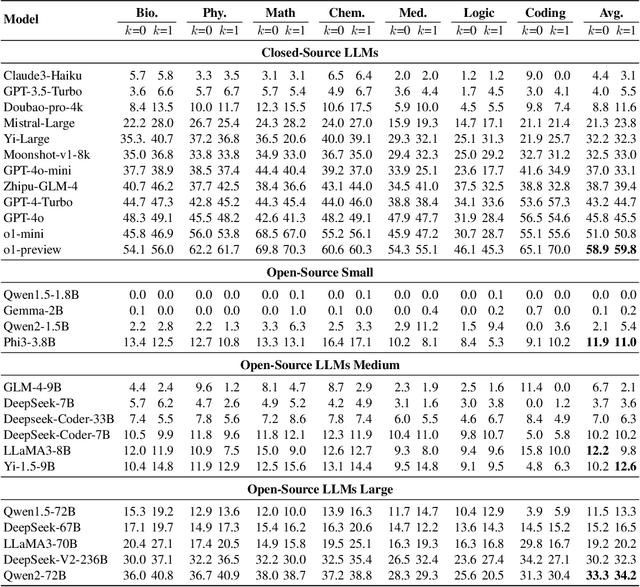
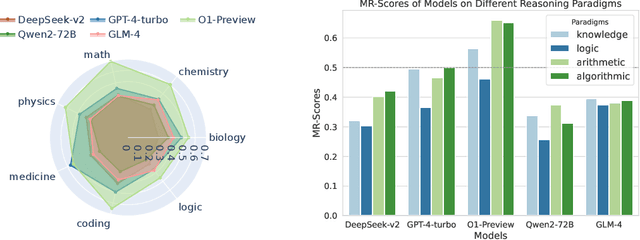
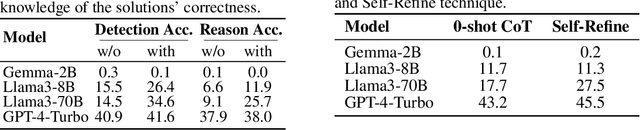
Large language models (LLMs) have shown increasing capability in problem-solving and decision-making, largely based on the step-by-step chain-of-thought reasoning processes. However, it has been increasingly challenging to evaluate the reasoning capability of LLMs. Concretely, existing outcome-based benchmarks begin to saturate and become less sufficient to monitor the progress. To this end, we present a process-based benchmark MR-BEN that demands a meta reasoning skill, where LMs are asked to locate and analyse potential errors in automatically generated reasoning steps. MR-BEN is a comprehensive benchmark comprising 5,975 questions collected from human experts, covering various subjects such as physics, chemistry, logic, coding, and more. Through our designed metrics for assessing meta-reasoning on this benchmark, we identify interesting limitations and weaknesses of current LLMs (open-source and closed-source models). For example, open-source models are seemingly comparable to GPT-4 on outcome-based benchmarks, but they lag far behind on our benchmark, revealing the underlying reasoning capability gap between them. Our dataset and codes are available on https://randolph-zeng.github.io/Mr-Ben.github.io/.
RoboCoder: Robotic Learning from Basic Skills to General Tasks with Large Language Models
Jun 06, 2024



The emergence of Large Language Models (LLMs) has improved the prospects for robotic tasks. However, existing benchmarks are still limited to single tasks with limited generalization capabilities. In this work, we introduce a comprehensive benchmark and an autonomous learning framework, RoboCoder aimed at enhancing the generalization capabilities of robots in complex environments. Unlike traditional methods that focus on single-task learning, our research emphasizes the development of a general-purpose robotic coding algorithm that enables robots to leverage basic skills to tackle increasingly complex tasks. The newly proposed benchmark consists of 80 manually designed tasks across 7 distinct entities, testing the models' ability to learn from minimal initial mastery. Initial testing revealed that even advanced models like GPT-4 could only achieve a 47% pass rate in three-shot scenarios with humanoid entities. To address these limitations, the RoboCoder framework integrates Large Language Models (LLMs) with a dynamic learning system that uses real-time environmental feedback to continuously update and refine action codes. This adaptive method showed a remarkable improvement, achieving a 36% relative improvement. Our codes will be released.
VLPose: Bridging the Domain Gap in Pose Estimation with Language-Vision Tuning
Feb 22, 2024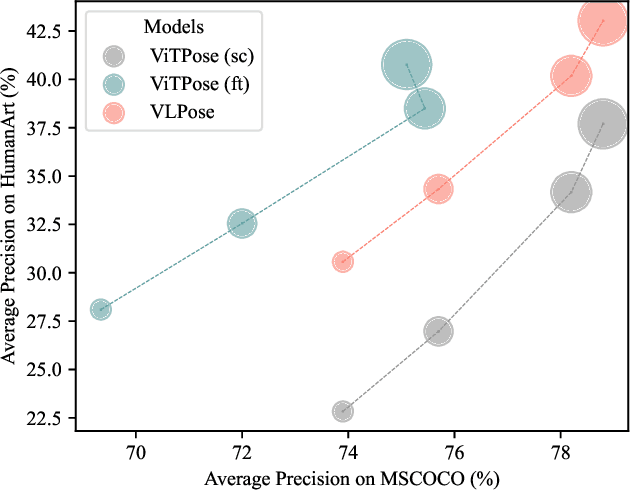



Thanks to advances in deep learning techniques, Human Pose Estimation (HPE) has achieved significant progress in natural scenarios. However, these models perform poorly in artificial scenarios such as painting and sculpture due to the domain gap, constraining the development of virtual reality and augmented reality. With the growth of model size, retraining the whole model on both natural and artificial data is computationally expensive and inefficient. Our research aims to bridge the domain gap between natural and artificial scenarios with efficient tuning strategies. Leveraging the potential of language models, we enhance the adaptability of traditional pose estimation models across diverse scenarios with a novel framework called VLPose. VLPose leverages the synergy between language and vision to extend the generalization and robustness of pose estimation models beyond the traditional domains. Our approach has demonstrated improvements of 2.26% and 3.74% on HumanArt and MSCOCO, respectively, compared to state-of-the-art tuning strategies.
MOODv2: Masked Image Modeling for Out-of-Distribution Detection
Jan 05, 2024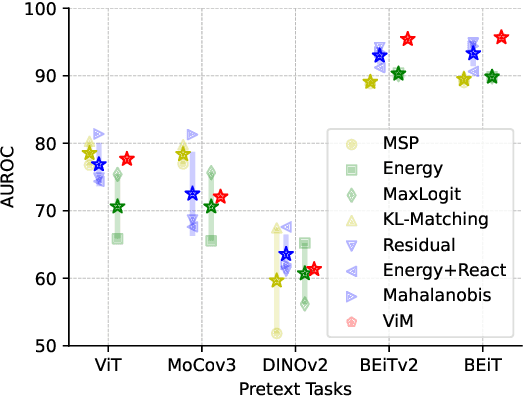

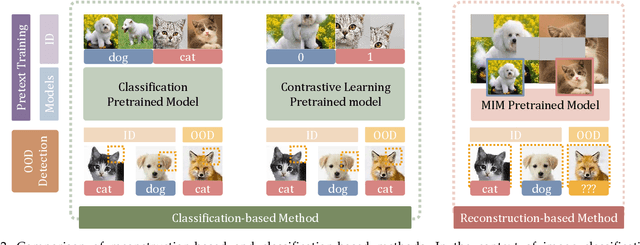
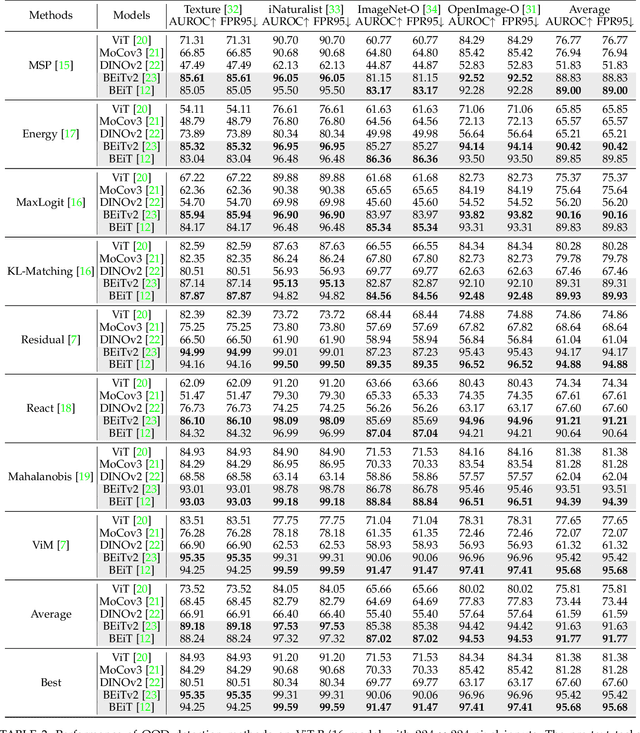
The crux of effective out-of-distribution (OOD) detection lies in acquiring a robust in-distribution (ID) representation, distinct from OOD samples. While previous methods predominantly leaned on recognition-based techniques for this purpose, they often resulted in shortcut learning, lacking comprehensive representations. In our study, we conducted a comprehensive analysis, exploring distinct pretraining tasks and employing various OOD score functions. The results highlight that the feature representations pre-trained through reconstruction yield a notable enhancement and narrow the performance gap among various score functions. This suggests that even simple score functions can rival complex ones when leveraging reconstruction-based pretext tasks. Reconstruction-based pretext tasks adapt well to various score functions. As such, it holds promising potential for further expansion. Our OOD detection framework, MOODv2, employs the masked image modeling pretext task. Without bells and whistles, MOODv2 impressively enhances 14.30% AUROC to 95.68% on ImageNet and achieves 99.98% on CIFAR-10.
MoTCoder: Elevating Large Language Models with Modular of Thought for Challenging Programming Tasks
Jan 05, 2024Large Language Models (LLMs) have showcased impressive capabilities in handling straightforward programming tasks. However, their performance tends to falter when confronted with more challenging programming problems. We observe that conventional models often generate solutions as monolithic code blocks, restricting their effectiveness in tackling intricate questions. To overcome this limitation, we present Modular-of-Thought Coder (MoTCoder). We introduce a pioneering framework for MoT instruction tuning, designed to promote the decomposition of tasks into logical sub-tasks and sub-modules. Our investigations reveal that, through the cultivation and utilization of sub-modules, MoTCoder significantly improves both the modularity and correctness of the generated solutions, leading to substantial relative pass@1 improvements of 12.9% on APPS and 9.43% on CodeContests. Our codes are available at https://github.com/dvlab-research/MoTCoder.
Challenge LLMs to Reason About Reasoning: A Benchmark to Unveil Cognitive Depth in LLMs
Dec 28, 2023



In this work, we introduce a novel evaluation paradigm for Large Language Models, one that challenges them to engage in meta-reasoning. This approach addresses critical shortcomings in existing math problem-solving benchmarks, traditionally used to evaluate the cognitive capabilities of agents. Our paradigm shifts the focus from result-oriented assessments, which often overlook the reasoning process, to a more holistic evaluation that effectively differentiates the cognitive capabilities among models. For example, in our benchmark, GPT-4 demonstrates a performance ten times more accurate than GPT3-5. The significance of this new paradigm lies in its ability to reveal potential cognitive deficiencies in LLMs that current benchmarks, such as GSM8K, fail to uncover due to their saturation and lack of effective differentiation among varying reasoning abilities. Our comprehensive analysis includes several state-of-the-art math models from both open-source and closed-source communities, uncovering fundamental deficiencies in their training and evaluation approaches. This paper not only advocates for a paradigm shift in the assessment of LLMs but also contributes to the ongoing discourse on the trajectory towards Artificial General Intelligence (AGI). By promoting the adoption of meta-reasoning evaluation methods similar to ours, we aim to facilitate a more accurate assessment of the true cognitive abilities of LLMs.
BAL: Balancing Diversity and Novelty for Active Learning
Dec 26, 2023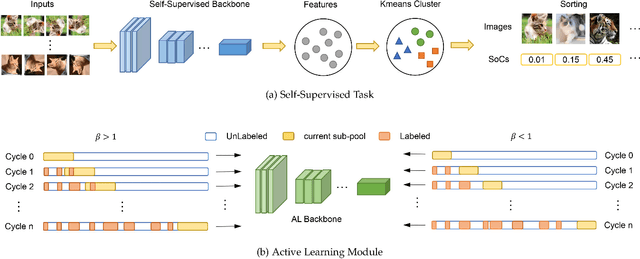

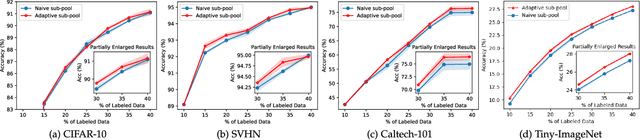
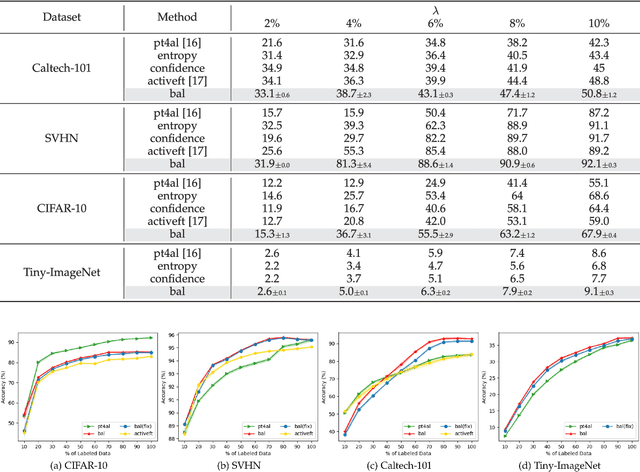
The objective of Active Learning is to strategically label a subset of the dataset to maximize performance within a predetermined labeling budget. In this study, we harness features acquired through self-supervised learning. We introduce a straightforward yet potent metric, Cluster Distance Difference, to identify diverse data. Subsequently, we introduce a novel framework, Balancing Active Learning (BAL), which constructs adaptive sub-pools to balance diverse and uncertain data. Our approach outperforms all established active learning methods on widely recognized benchmarks by 1.20%. Moreover, we assess the efficacy of our proposed framework under extended settings, encompassing both larger and smaller labeling budgets. Experimental results demonstrate that, when labeling 80% of the samples, the performance of the current SOTA method declines by 0.74%, whereas our proposed BAL achieves performance comparable to the full dataset. Codes are available at https://github.com/JulietLJY/BAL.
Defect Spectrum: A Granular Look of Large-Scale Defect Datasets with Rich Semantics
Nov 06, 2023Defect inspection is paramount within the closed-loop manufacturing system. However, existing datasets for defect inspection often lack precision and semantic granularity required for practical applications. In this paper, we introduce the Defect Spectrum, a comprehensive benchmark that offers precise, semantic-abundant, and large-scale annotations for a wide range of industrial defects. Building on four key industrial benchmarks, our dataset refines existing annotations and introduces rich semantic details, distinguishing multiple defect types within a single image. Furthermore, we introduce Defect-Gen, a two-stage diffusion-based generator designed to create high-quality and diverse defective images, even when working with limited datasets. The synthetic images generated by Defect-Gen significantly enhance the efficacy of defect inspection models. Overall, The Defect Spectrum dataset demonstrates its potential in defect inspection research, offering a solid platform for testing and refining advanced models.
A Scale-Invariant Task Balancing Approach for Multi-Task Learning
Aug 23, 2023Multi-task learning (MTL), a learning paradigm to learn multiple related tasks simultaneously, has achieved great success in various fields. However, task-balancing remains a significant challenge in MTL, with the disparity in loss/gradient scales often leading to performance compromises. In this paper, we propose a Scale-Invariant Multi-Task Learning (SI-MTL) method to alleviate the task-balancing problem from both loss and gradient perspectives. Specifically, SI-MTL contains a logarithm transformation which is performed on all task losses to ensure scale-invariant at the loss level, and a gradient balancing method, SI-G, which normalizes all task gradients to the same magnitude as the maximum gradient norm. Extensive experiments conducted on several benchmark datasets consistently demonstrate the effectiveness of SI-G and the state-of-the-art performance of SI-MTL.