 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic World Modeling: Foundations, Capabilities, Laws, and Beyond
Apr 24, 2026As AI systems move from generating text to accomplishing goals through sustained interaction, the ability to model environment dynamics becomes a central bottleneck. Agents that manipulate objects, navigate software, coordinate with others, or design experiments require predictive environment models, yet the term world model carries different meanings across research communities. We introduce a "levels x laws" taxonomy organized along two axes. The first defines three capability levels: L1 Predictor, which learns one-step local transition operators; L2 Simulator, which composes them into multi-step, action-conditioned rollouts that respect domain laws; and L3 Evolver, which autonomously revises its own model when predictions fail against new evidence. The second identifies four governing-law regimes: physical, digital, social, and scientific. These regimes determine what constraints a world model must satisfy and where it is most likely to fail. Using this framework, we synthesize over 400 works and summarize more than 100 representative systems spanning model-based reinforcement learning, video generation, web and GUI agents, multi-agent social simulation, and AI-driven scientific discovery. We analyze methods, failure modes, and evaluation practices across level-regime pairs, propose decision-centric evaluation principles and a minimal reproducible evaluation package, and outline architectural guidance, open problems, and governance challenges. The resulting roadmap connects previously isolated communities and charts a path from passive next-step prediction toward world models that can simulate, and ultimately reshape, the environments in which agents operate.
SearchGym: Bootstrapping Real-World Search Agents via Cost-Effective and High-Fidelity Environment Simulation
Jan 21, 2026Search agents have emerged as a pivotal paradigm for solving open-ended, knowledge-intensive reasoning tasks. However, training these agents via Reinforcement Learning (RL) faces a critical dilemma: interacting with live commercial Web APIs is prohibitively expensive, while relying on static data snapshots often introduces noise due to data misalignment. This misalignment generates corrupted reward signals that destabilize training by penalizing correct reasoning or rewarding hallucination. To address this, we propose SearchGym, a simulation environment designed to bootstrap robust search agents. SearchGym employs a rigorous generative pipeline to construct a verifiable knowledge graph and an aligned document corpus, ensuring that every reasoning task is factually grounded and strictly solvable. Building on this controllable environment, we introduce SearchGym-RL, a curriculum learning methodology that progressively optimizes agent policies through purified feedback, evolving from basic interactions to complex, long-horizon planning. Extensive experiments across the Llama and Qwen families demonstrate strong Sim-to-Real generalization. Notably, our Qwen2.5-7B-Base model trained within SearchGym surpasses the web-enhanced ASearcher baseline across nine diverse benchmarks by an average relative margin of 10.6%. Our results validate that high-fidelity simulation serves as a scalable and highly cost-effective methodology for developing capable search agents.
VisionDirector: Vision-Language Guided Closed-Loop Refinement for Generative Image Synthesis
Dec 22, 2025Generative models can now produce photorealistic imagery, yet they still struggle with the long, multi-goal prompts that professional designers issue. To expose this gap and better evaluate models' performance in real-world settings, we introduce Long Goal Bench (LGBench), a 2,000-task suite (1,000 T2I and 1,000 I2I) whose average instruction contains 18 to 22 tightly coupled goals spanning global layout, local object placement, typography, and logo fidelity. We find that even state-of-the-art models satisfy fewer than 72 percent of the goals and routinely miss localized edits, confirming the brittleness of current pipelines. To address this, we present VisionDirector, a training-free vision-language supervisor that (i) extracts structured goals from long instructions, (ii) dynamically decides between one-shot generation and staged edits, (iii) runs micro-grid sampling with semantic verification and rollback after every edit, and (iv) logs goal-level rewards. We further fine-tune the planner with Group Relative Policy Optimization, yielding shorter edit trajectories (3.1 versus 4.2 steps) and stronger alignment. VisionDirector achieves new state of the art on GenEval (plus 7 percent overall) and ImgEdit (plus 0.07 absolute) while producing consistent qualitative improvements on typography, multi-object scenes, and pose editing.
Scaf-GRPO: Scaffolded Group Relative Policy Optimization for Enhancing LLM Reasoning
Oct 22, 2025Reinforcement learning from verifiable rewards has emerged as a powerful technique for enhancing the complex reasoning abilities of Large Language Models (LLMs). However, these methods are fundamentally constrained by the ''learning cliff'' phenomenon: when faced with problems far beyond their current capabilities, models consistently fail, yielding a persistent zero-reward signal. In policy optimization algorithms like GRPO, this collapses the advantage calculation to zero, rendering these difficult problems invisible to the learning gradient and stalling progress. To overcome this, we introduce Scaf-GRPO (Scaffolded Group Relative Policy Optimization), a progressive training framework that strategically provides minimal guidance only when a model's independent learning has plateaued. The framework first diagnoses learning stagnation and then intervenes by injecting tiered in-prompt hints, ranging from abstract concepts to concrete steps, enabling the model to construct a valid solution by itself. Extensive experiments on challenging mathematics benchmarks demonstrate Scaf-GRPO's effectiveness, boosting the pass@1 score of the Qwen2.5-Math-7B model on the AIME24 benchmark by a relative 44.3% over a vanilla GRPO baseline. This result demonstrates our framework provides a robust and effective methodology for unlocking a model's ability to solve problems previously beyond its reach, a critical step towards extending the frontier of autonomous reasoning in LLM.
TraveLLaMA: Facilitating Multi-modal Large Language Models to Understand Urban Scenes and Provide Travel Assistance
Apr 23, 2025Tourism and travel planning increasingly rely on digital assistance, yet existing multimodal AI systems often lack specialized knowledge and contextual understanding of urban environments. We present TraveLLaMA, a specialized multimodal language model designed for urban scene understanding and travel assistance. Our work addresses the fundamental challenge of developing practical AI travel assistants through a novel large-scale dataset of 220k question-answer pairs. This comprehensive dataset uniquely combines 130k text QA pairs meticulously curated from authentic travel forums with GPT-enhanced responses, alongside 90k vision-language QA pairs specifically focused on map understanding and scene comprehension. Through extensive fine-tuning experiments on state-of-the-art vision-language models (LLaVA, Qwen-VL, Shikra), we demonstrate significant performance improvements ranging from 6.5\%-9.4\% in both pure text travel understanding and visual question answering tasks. Our model exhibits exceptional capabilities in providing contextual travel recommendations, interpreting map locations, and understanding place-specific imagery while offering practical information such as operating hours and visitor reviews. Comparative evaluations show TraveLLaMA significantly outperforms general-purpose models in travel-specific tasks, establishing a new benchmark for multi-modal travel assistance systems.
Lyra: An Efficient and Speech-Centric Framework for Omni-Cognition
Dec 12, 2024



As Multi-modal Large Language Models (MLLMs) evolve, expanding beyond single-domain capabilities is essential to meet the demands for more versatile and efficient AI. However, previous omni-models have insufficiently explored speech, neglecting its integration with multi-modality. We introduce Lyra, an efficient MLLM that enhances multimodal abilities, including advanced long-speech comprehension, sound understanding, cross-modality efficiency, and seamless speech interaction. To achieve efficiency and speech-centric capabilities, Lyra employs three strategies: (1) leveraging existing open-source large models and a proposed multi-modality LoRA to reduce training costs and data requirements; (2) using a latent multi-modality regularizer and extractor to strengthen the relationship between speech and other modalities, thereby enhancing model performance; and (3) constructing a high-quality, extensive dataset that includes 1.5M multi-modal (language, vision, audio) data samples and 12K long speech samples, enabling Lyra to handle complex long speech inputs and achieve more robust omni-cognition. Compared to other omni-methods, Lyra achieves state-of-the-art performance on various vision-language, vision-speech, and speech-language benchmarks, while also using fewer computational resources and less training data.
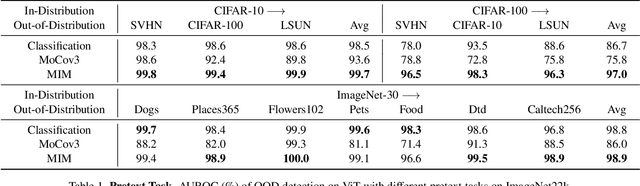
MOODv2: Masked Image Modeling for Out-of-Distribution Detection
Jan 05, 2024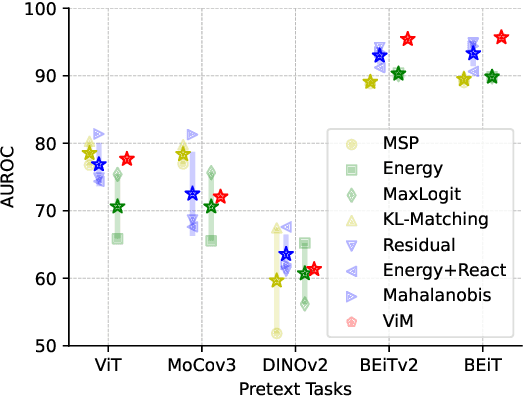

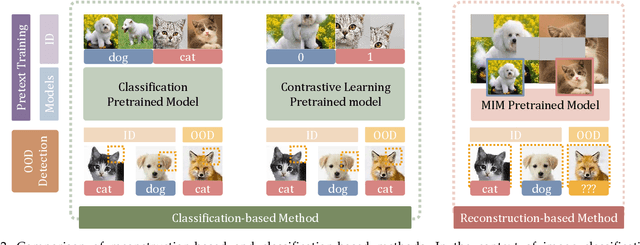
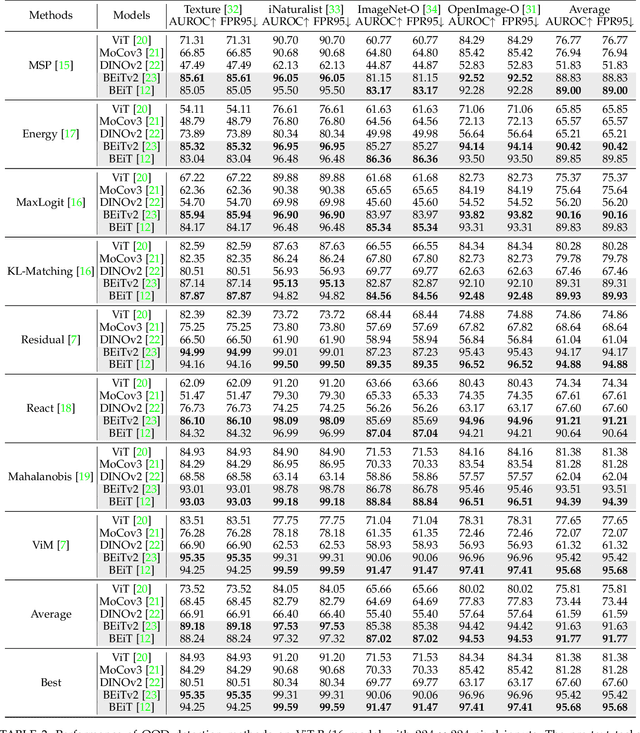
The crux of effective out-of-distribution (OOD) detection lies in acquiring a robust in-distribution (ID) representation, distinct from OOD samples. While previous methods predominantly leaned on recognition-based techniques for this purpose, they often resulted in shortcut learning, lacking comprehensive representations. In our study, we conducted a comprehensive analysis, exploring distinct pretraining tasks and employing various OOD score functions. The results highlight that the feature representations pre-trained through reconstruction yield a notable enhancement and narrow the performance gap among various score functions. This suggests that even simple score functions can rival complex ones when leveraging reconstruction-based pretext tasks. Reconstruction-based pretext tasks adapt well to various score functions. As such, it holds promising potential for further expansion. Our OOD detection framework, MOODv2, employs the masked image modeling pretext task. Without bells and whistles, MOODv2 impressively enhances 14.30% AUROC to 95.68% on ImageNet and achieves 99.98% on CIFAR-10.
BAL: Balancing Diversity and Novelty for Active Learning
Dec 26, 2023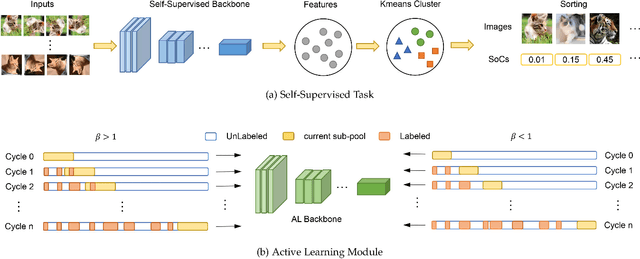

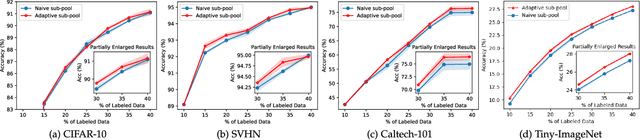
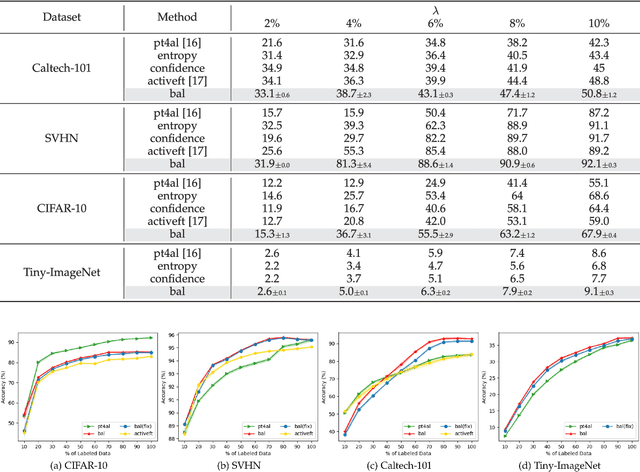
The objective of Active Learning is to strategically label a subset of the dataset to maximize performance within a predetermined labeling budget. In this study, we harness features acquired through self-supervised learning. We introduce a straightforward yet potent metric, Cluster Distance Difference, to identify diverse data. Subsequently, we introduce a novel framework, Balancing Active Learning (BAL), which constructs adaptive sub-pools to balance diverse and uncertain data. Our approach outperforms all established active learning methods on widely recognized benchmarks by 1.20%. Moreover, we assess the efficacy of our proposed framework under extended settings, encompassing both larger and smaller labeling budgets. Experimental results demonstrate that, when labeling 80% of the samples, the performance of the current SOTA method declines by 0.74%, whereas our proposed BAL achieves performance comparable to the full dataset. Codes are available at https://github.com/JulietLJY/BAL.
OOD-CV-v2: An extended Benchmark for Robustness to Out-of-Distribution Shifts of Individual Nuisances in Natural Images
Apr 17, 2023



Enhancing the robustness of vision algorithms in real-world scenarios is challenging. One reason is that existing robustness benchmarks are limited, as they either rely on synthetic data or ignore the effects of individual nuisance factors. We introduce OOD-CV-v2, a benchmark dataset that includes out-of-distribution examples of 10 object categories in terms of pose, shape, texture, context and the weather conditions, and enables benchmarking of models for image classification, object detection, and 3D pose estimation. In addition to this novel dataset, we contribute extensive experiments using popular baseline methods, which reveal that: 1) Some nuisance factors have a much stronger negative effect on the performance compared to others, also depending on the vision task. 2) Current approaches to enhance robustness have only marginal effects, and can even reduce robustness. 3) We do not observe significant differences between convolutional and transformer architectures. We believe our dataset provides a rich test bed to study robustness and will help push forward research in this area. Our dataset can be accessed from http://www.ood-cv.org/challenge.html
Rethinking Out-of-distribution (OOD) Detection: Masked Image Modeling is All You Need
Feb 06, 2023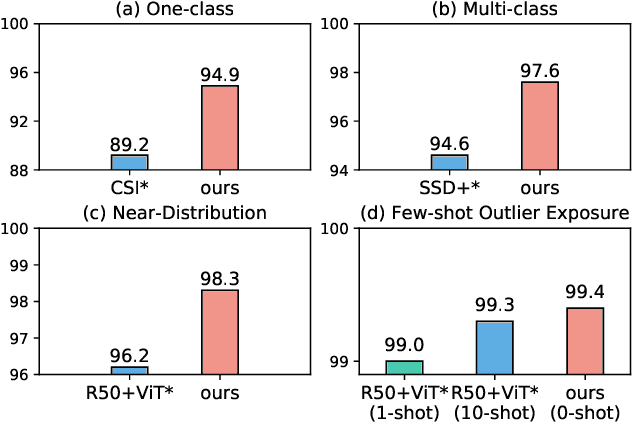
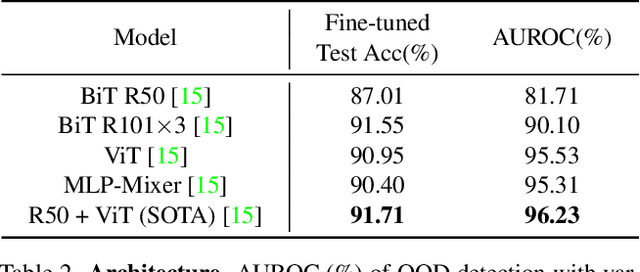
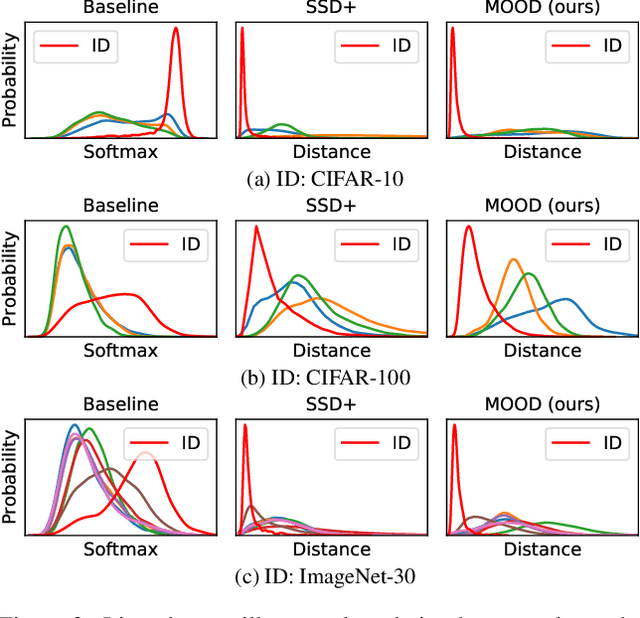
The core of out-of-distribution (OOD) detection is to learn the in-distribution (ID) representation, which is distinguishable from OOD samples. Previous work applied recognition-based methods to learn the ID features, which tend to learn shortcuts instead of comprehensive representations. In this work, we find surprisingly that simply using reconstruction-based methods could boost the performance of OOD detection significantly. We deeply explore the main contributors of OOD detection and find that reconstruction-based pretext tasks have the potential to provide a generally applicable and efficacious prior, which benefits the model in learning intrinsic data distributions of the ID dataset. Specifically, we take Masked Image Modeling as a pretext task for our OOD detection framework (MOOD). Without bells and whistles, MOOD outperforms previous SOTA of one-class OOD detection by 5.7%, multi-class OOD detection by 3.0%, and near-distribution OOD detection by 2.1%. It even defeats the 10-shot-per-class outlier exposure OOD detection, although we do not include any OOD samples for our detection