 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnityVideo: Unified Multi-Modal Multi-Task Learning for Enhancing World-Aware Video Generation
Dec 08, 2025Recent video generation models demonstrate impressive synthesis capabilities but remain limited by single-modality conditioning, constraining their holistic world understanding. This stems from insufficient cross-modal interaction and limited modal diversity for comprehensive world knowledge representation. To address these limitations, we introduce UnityVideo, a unified framework for world-aware video generation that jointly learns across multiple modalities (segmentation masks, human skeletons, DensePose, optical flow, and depth maps) and training paradigms. Our approach features two core components: (1) dynamic noising to unify heterogeneous training paradigms, and (2) a modality switcher with an in-context learner that enables unified processing via modular parameters and contextual learning. We contribute a large-scale unified dataset with 1.3M samples. Through joint optimization, UnityVideo accelerates convergence and significantly enhances zero-shot generalization to unseen data. We demonstrate that UnityVideo achieves superior video quality, consistency, and improved alignment with physical world constraints. Code and data can be found at: https://github.com/dvlab-research/UnityVideo
UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist
Nov 11, 2025While specialized AI models excel at isolated video tasks like generation or understanding, real-world applications demand complex, iterative workflows that combine these capabilities. To bridge this gap, we introduce UniVA, an open-source, omni-capable multi-agent framework for next-generation video generalists that unifies video understanding, segmentation, editing, and generation into cohesive workflows. UniVA employs a Plan-and-Act dual-agent architecture that drives a highly automated and proactive workflow: a planner agent interprets user intentions and decomposes them into structured video-processing steps, while executor agents execute these through modular, MCP-based tool servers (for analysis, generation, editing, tracking, etc.). Through a hierarchical multi-level memory (global knowledge, task context, and user-specific preferences), UniVA sustains long-horizon reasoning, contextual continuity, and inter-agent communication, enabling interactive and self-reflective video creation with full traceability. This design enables iterative and any-conditioned video workflows (e.g., text/image/video-conditioned generation $\rightarrow$ multi-round editing $\rightarrow$ object segmentation $\rightarrow$ compositional synthesis) that were previously cumbersome to achieve with single-purpose models or monolithic video-language models. We also introduce UniVA-Bench, a benchmark suite of multi-step video tasks spanning understanding, editing, segmentation, and generation, to rigorously evaluate such agentic video systems. Both UniVA and UniVA-Bench are fully open-sourced, aiming to catalyze research on interactive, agentic, and general-purpose video intelligence for the next generation of multimodal AI systems. (https://univa.online/)
DreamVE: Unified Instruction-based Image and Video Editing
Aug 08, 2025Instruction-based editing holds vast potential due to its simple and efficient interactive editing format. However, instruction-based editing, particularly for video, has been constrained by limited training data, hindering its practical application. To this end, we introduce DreamVE, a unified model for instruction-based image and video editing. Specifically, We propose a two-stage training strategy: first image editing, then video editing. This offers two main benefits: (1) Image data scales more easily, and models are more efficient to train, providing useful priors for faster and better video editing training. (2) Unifying image and video generation is natural and aligns with current trends. Moreover, we present comprehensive training data synthesis pipelines, including collage-based and generative model-based data synthesis. The collage-based data synthesis combines foreground objects and backgrounds to generate diverse editing data, such as object manipulation, background changes, and text modifications. It can easily generate billions of accurate, consistent, realistic, and diverse editing pairs. We pretrain DreamVE on extensive collage-based data to achieve strong performance in key editing types and enhance generalization and transfer capabilities. However, collage-based data lacks some attribute editing cases, leading to a relative drop in performance. In contrast, the generative model-based pipeline, despite being hard to scale up, offers flexibility in handling attribute editing cases. Therefore, we use generative model-based data to further fine-tune DreamVE. Besides, we design an efficient and powerful editing framework for DreamVE. We build on the SOTA T2V model and use a token concatenation with early drop approach to inject source image guidance, ensuring strong consistency and editability. The codes and models will be released.
Training-Free Efficient Video Generation via Dynamic Token Carving
May 22, 2025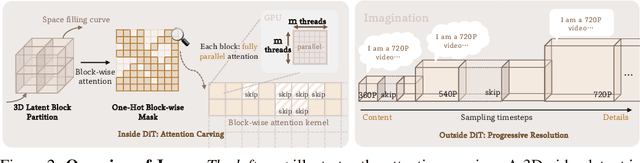
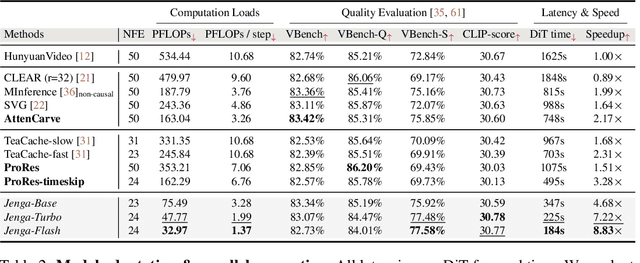
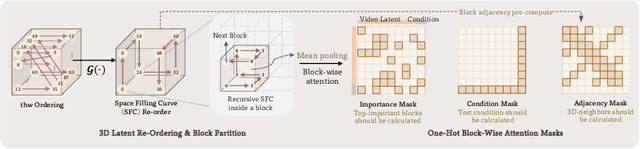
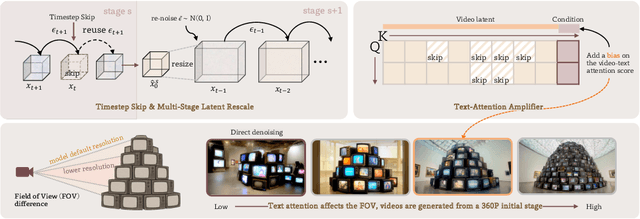
Despite the remarkable generation quality of video Diffusion Transformer (DiT) models, their practical deployment is severely hindered by extensive computational requirements. This inefficiency stems from two key challenges: the quadratic complexity of self-attention with respect to token length and the multi-step nature of diffusion models. To address these limitations, we present Jenga, a novel inference pipeline that combines dynamic attention carving with progressive resolution generation. Our approach leverages two key insights: (1) early denoising steps do not require high-resolution latents, and (2) later steps do not require dense attention. Jenga introduces a block-wise attention mechanism that dynamically selects relevant token interactions using 3D space-filling curves, alongside a progressive resolution strategy that gradually increases latent resolution during generation. Experimental results demonstrate that Jenga achieves substantial speedups across multiple state-of-the-art video diffusion models while maintaining comparable generation quality (8.83$\times$ speedup with 0.01\% performance drop on VBench). As a plug-and-play solution, Jenga enables practical, high-quality video generation on modern hardware by reducing inference time from minutes to seconds -- without requiring model retraining. Code: https://github.com/dvlab-research/Jenga
Magic Mirror: ID-Preserved Video Generation in Video Diffusion Transformers
Jan 07, 2025

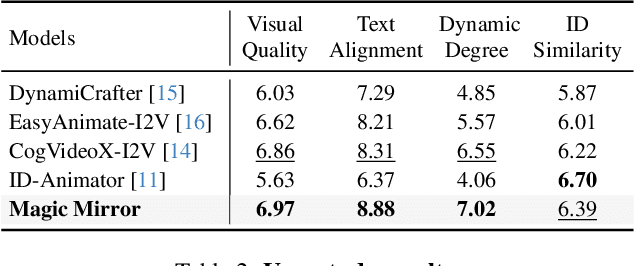
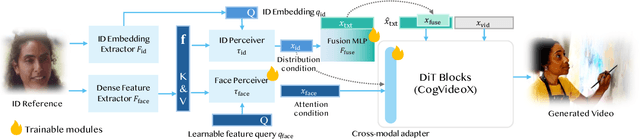
We present Magic Mirror, a framework for generating identity-preserved videos with cinematic-level quality and dynamic motion. While recent advances in video diffusion models have shown impressive capabilities in text-to-video generation, maintaining consistent identity while producing natural motion remains challenging. Previous methods either require person-specific fine-tuning or struggle to balance identity preservation with motion diversity. Built upon Video Diffusion Transformers, our method introduces three key components: (1) a dual-branch facial feature extractor that captures both identity and structural features, (2) a lightweight cross-modal adapter with Conditioned Adaptive Normalization for efficient identity integration, and (3) a two-stage training strategy combining synthetic identity pairs with video data. Extensive experiments demonstrate that Magic Mirror effectively balances identity consistency with natural motion, outperforming existing methods across multiple metrics while requiring minimal parameters added. The code and model will be made publicly available at: https://github.com/dvlab-research/MagicMirror/
DreamOmni: Unified Image Generation and Editing
Dec 22, 2024Currently, the success of large language models (LLMs) illustrates that a unified multitasking approach can significantly enhance model usability, streamline deployment, and foster synergistic benefits across different tasks. However, in computer vision, while text-to-image (T2I) models have significantly improved generation quality through scaling up, their framework design did not initially consider how to unify with downstream tasks, such as various types of editing. To address this, we introduce DreamOmni, a unified model for image generation and editing. We begin by analyzing existing frameworks and the requirements of downstream tasks, proposing a unified framework that integrates both T2I models and various editing tasks. Furthermore, another key challenge is the efficient creation of high-quality editing data, particularly for instruction-based and drag-based editing. To this end, we develop a synthetic data pipeline using sticker-like elements to synthesize accurate, high-quality datasets efficiently, which enables editing data scaling up for unified model training. For training, DreamOmni jointly trains T2I generation and downstream tasks. T2I training enhances the model's understanding of specific concepts and improves generation quality, while editing training helps the model grasp the nuances of the editing task. This collaboration significantly boosts editing performance. Extensive experiments confirm the effectiveness of DreamOmni. The code and model will be released.
Lyra: An Efficient and Speech-Centric Framework for Omni-Cognition
Dec 12, 2024



As Multi-modal Large Language Models (MLLMs) evolve, expanding beyond single-domain capabilities is essential to meet the demands for more versatile and efficient AI. However, previous omni-models have insufficiently explored speech, neglecting its integration with multi-modality. We introduce Lyra, an efficient MLLM that enhances multimodal abilities, including advanced long-speech comprehension, sound understanding, cross-modality efficiency, and seamless speech interaction. To achieve efficiency and speech-centric capabilities, Lyra employs three strategies: (1) leveraging existing open-source large models and a proposed multi-modality LoRA to reduce training costs and data requirements; (2) using a latent multi-modality regularizer and extractor to strengthen the relationship between speech and other modalities, thereby enhancing model performance; and (3) constructing a high-quality, extensive dataset that includes 1.5M multi-modal (language, vision, audio) data samples and 12K long speech samples, enabling Lyra to handle complex long speech inputs and achieve more robust omni-cognition. Compared to other omni-methods, Lyra achieves state-of-the-art performance on various vision-language, vision-speech, and speech-language benchmarks, while also using fewer computational resources and less training data.
ControlNeXt: Powerful and Efficient Control for Image and Video Generation
Aug 15, 2024



Diffusion models have demonstrated remarkable and robust abilities in both image and video generation. To achieve greater control over generated results, researchers introduce additional architectures, such as ControlNet, Adapters and ReferenceNet, to integrate conditioning controls. However, current controllable generation methods often require substantial additional computational resources, especially for video generation, and face challenges in training or exhibit weak control. In this paper, we propose ControlNeXt: a powerful and efficient method for controllable image and video generation. We first design a more straightforward and efficient architecture, replacing heavy additional branches with minimal additional cost compared to the base model. Such a concise structure also allows our method to seamlessly integrate with other LoRA weights, enabling style alteration without the need for additional training. As for training, we reduce up to 90% of learnable parameters compared to the alternatives. Furthermore, we propose another method called Cross Normalization (CN) as a replacement for Zero-Convolution' to achieve fast and stable training convergence. We have conducted various experiments with different base models across images and videos, demonstrating the robustness of our method.
ResMaster: Mastering High-Resolution Image Generation via Structural and Fine-Grained Guidance
Jun 24, 2024



Diffusion models excel at producing high-quality images; however, scaling to higher resolutions, such as 4K, often results in over-smoothed content, structural distortions, and repetitive patterns. To this end, we introduce ResMaster, a novel, training-free method that empowers resolution-limited diffusion models to generate high-quality images beyond resolution restrictions. Specifically, ResMaster leverages a low-resolution reference image created by a pre-trained diffusion model to provide structural and fine-grained guidance for crafting high-resolution images on a patch-by-patch basis. To ensure a coherent global structure, ResMaster meticulously aligns the low-frequency components of high-resolution patches with the low-resolution reference at each denoising step. For fine-grained guidance, tailored image prompts based on the low-resolution reference and enriched textual prompts produced by a vision-language model are incorporated. This approach could significantly mitigate local pattern distortions and improve detail refinement. Extensive experiments validate that ResMaster sets a new benchmark for high-resolution image generation and demonstrates promising efficiency. The project page is https://shuweis.github.io/ResMaster .
Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models
Mar 27, 2024



In this work, we introduce Mini-Gemini, a simple and effective framework enhancing multi-modality Vision Language Models (VLMs). Despite the advancements in VLMs facilitating basic visual dialog and reasoning, a performance gap persists compared to advanced models like GPT-4 and Gemini. We try to narrow the gap by mining the potential of VLMs for better performance and any-to-any workflow from three aspects, i.e., high-resolution visual tokens, high-quality data, and VLM-guided generation. To enhance visual tokens, we propose to utilize an additional visual encoder for high-resolution refinement without increasing the visual token count. We further construct a high-quality dataset that promotes precise image comprehension and reasoning-based generation, expanding the operational scope of current VLMs. In general, Mini-Gemini further mines the potential of VLMs and empowers current frameworks with image understanding, reasoning, and generation simultaneously. Mini-Gemini supports a series of dense and MoE Large Language Models (LLMs) from 2B to 34B. It is demonstrated to achieve leading performance in several zero-shot benchmarks and even surpasses the developed private models. Code and models are available at https://github.com/dvlab-research/MiniGemini.