 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee-through: Single-image Layer Decomposition for Anime Characters
Feb 03, 2026We introduce a framework that automates the transformation of static anime illustrations into manipulatable 2.5D models. Current professional workflows require tedious manual segmentation and the artistic ``hallucination'' of occluded regions to enable motion. Our approach overcomes this by decomposing a single image into fully inpainted, semantically distinct layers with inferred drawing orders. To address the scarcity of training data, we introduce a scalable engine that bootstraps high-quality supervision from commercial Live2D models, capturing pixel-perfect semantics and hidden geometry. Our methodology couples a diffusion-based Body Part Consistency Module, which enforces global geometric coherence, with a pixel-level pseudo-depth inference mechanism. This combination resolves the intricate stratification of anime characters, e.g., interleaving hair strands, allowing for dynamic layer reconstruction. We demonstrate that our approach yields high-fidelity, manipulatable models suitable for professional, real-time animation applications.
Hyperstroke: A Novel High-quality Stroke Representation for Assistive Artistic Drawing
Aug 18, 2024Assistive drawing aims to facilitate the creative process by providing intelligent guidance to artists. Existing solutions often fail to effectively model intricate stroke details or adequately address the temporal aspects of drawing. We introduce hyperstroke, a novel stroke representation designed to capture precise fine stroke details, including RGB appearance and alpha-channel opacity. Using a Vector Quantization approach, hyperstroke learns compact tokenized representations of strokes from real-life drawing videos of artistic drawing. With hyperstroke, we propose to model assistive drawing via a transformer-based architecture, to enable intuitive and user-friendly drawing applications, which are experimented in our exploratory evaluation.
ToonCrafter: Generative Cartoon Interpolation
May 28, 2024



We introduce ToonCrafter, a novel approach that transcends traditional correspondence-based cartoon video interpolation, paving the way for generative interpolation. Traditional methods, that implicitly assume linear motion and the absence of complicated phenomena like dis-occlusion, often struggle with the exaggerated non-linear and large motions with occlusion commonly found in cartoons, resulting in implausible or even failed interpolation results. To overcome these limitations, we explore the potential of adapting live-action video priors to better suit cartoon interpolation within a generative framework. ToonCrafter effectively addresses the challenges faced when applying live-action video motion priors to generative cartoon interpolation. First, we design a toon rectification learning strategy that seamlessly adapts live-action video priors to the cartoon domain, resolving the domain gap and content leakage issues. Next, we introduce a dual-reference-based 3D decoder to compensate for lost details due to the highly compressed latent prior spaces, ensuring the preservation of fine details in interpolation results. Finally, we design a flexible sketch encoder that empowers users with interactive control over the interpolation results. Experimental results demonstrate that our proposed method not only produces visually convincing and more natural dynamics, but also effectively handles dis-occlusion. The comparative evaluation demonstrates the notable superiority of our approach over existing competitors.
Highly Detailed and Temporal Consistent Video Stylization via Synchronized Multi-Frame Diffusion
Nov 24, 2023



Text-guided video-to-video stylization transforms the visual appearance of a source video to a different appearance guided on textual prompts. Existing text-guided image diffusion models can be extended for stylized video synthesis. However, they struggle to generate videos with both highly detailed appearance and temporal consistency. In this paper, we propose a synchronized multi-frame diffusion framework to maintain both the visual details and the temporal consistency. Frames are denoised in a synchronous fashion, and more importantly, information of different frames is shared since the beginning of the denoising process. Such information sharing ensures that a consensus, in terms of the overall structure and color distribution, among frames can be reached in the early stage of the denoising process before it is too late. The optical flow from the original video serves as the connection, and hence the venue for information sharing, among frames. We demonstrate the effectiveness of our method in generating high-quality and diverse results in extensive experiments. Our method shows superior qualitative and quantitative results compared to state-of-the-art video editing methods.
Text-Guided Texturing by Synchronized Multi-View Diffusion
Nov 21, 2023



This paper introduces a novel approach to synthesize texture to dress up a given 3D object, given a text prompt. Based on the pretrained text-to-image (T2I) diffusion model, existing methods usually employ a project-and-inpaint approach, in which a view of the given object is first generated and warped to another view for inpainting. But it tends to generate inconsistent texture due to the asynchronous diffusion of multiple views. We believe such asynchronous diffusion and insufficient information sharing among views are the root causes of the inconsistent artifact. In this paper, we propose a synchronized multi-view diffusion approach that allows the diffusion processes from different views to reach a consensus of the generated content early in the process, and hence ensures the texture consistency. To synchronize the diffusion, we share the denoised content among different views in each denoising step, specifically blending the latent content in the texture domain from views with overlap. Our method demonstrates superior performance in generating consistent, seamless, highly detailed textures, comparing to state-of-the-art methods.
Redistributing the Precision and Content in 3D-LUT-based Inverse Tone-mapping for HDR/WCG Display
Oct 15, 2023ITM(inverse tone-mapping) converts SDR (standard dynamic range) footage to HDR/WCG (high dynamic range /wide color gamut) for media production. It happens not only when remastering legacy SDR footage in front-end content provider, but also adapting on-theair SDR service on user-end HDR display. The latter requires more efficiency, thus the pre-calculated LUT (look-up table) has become a popular solution. Yet, conventional fixed LUT lacks adaptability, so we learn from research community and combine it with AI. Meanwhile, higher-bit-depth HDR/WCG requires larger LUT than SDR, so we consult traditional ITM for an efficiency-performance trade-off: We use 3 smaller LUTs, each has a non-uniform packing (precision) respectively denser in dark, middle and bright luma range. In this case, their results will have less error only in their own range, so we use a contribution map to combine their best parts to final result. With the guidance of this map, the elements (content) of 3 LUTs will also be redistributed during training. We conduct ablation studies to verify method's effectiveness, and subjective and objective experiments to show its practicability. Code is available at: https://github.com/AndreGuo/ITMLUT.
Video Colorization with Pre-trained Text-to-Image Diffusion Models
Jun 02, 2023
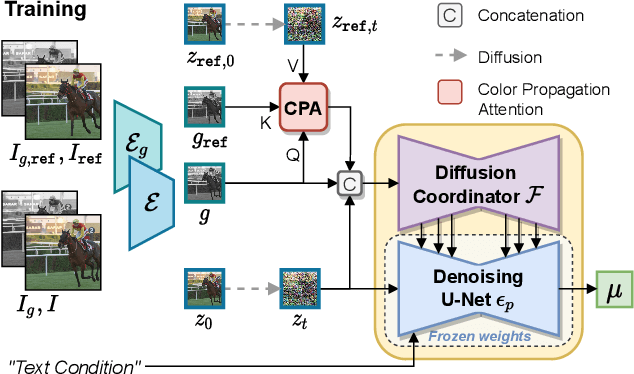


Video colorization is a challenging task that involves inferring plausible and temporally consistent colors for grayscale frames. In this paper, we present ColorDiffuser, an adaptation of a pre-trained text-to-image latent diffusion model for video colorization. With the proposed adapter-based approach, we repropose the pre-trained text-to-image model to accept input grayscale video frames, with the optional text description, for video colorization. To enhance the temporal coherence and maintain the vividness of colorization across frames, we propose two novel techniques: the Color Propagation Attention and Alternated Sampling Strategy. Color Propagation Attention enables the model to refine its colorization decision based on a reference latent frame, while Alternated Sampling Strategy captures spatiotemporal dependencies by using the next and previous adjacent latent frames alternatively as reference during the generative diffusion sampling steps. This encourages bidirectional color information propagation between adjacent video frames, leading to improved color consistency across frames. We conduct extensive experiments on benchmark datasets, and the results demonstrate the effectiveness of our proposed framework. The evaluations show that ColorDiffuser achieves state-of-the-art performance in video colorization, surpassing existing methods in terms of color fidelity, temporal consistency, and visual quality.
Make-Your-Video: Customized Video Generation Using Textual and Structural Guidance
Jun 01, 2023
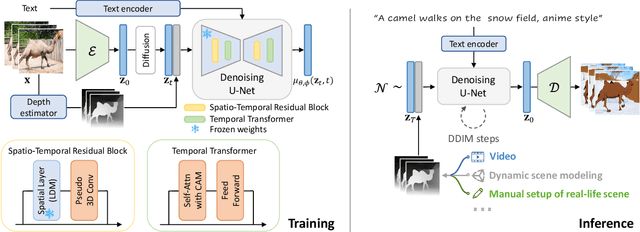
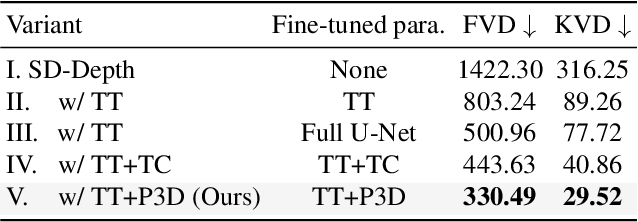
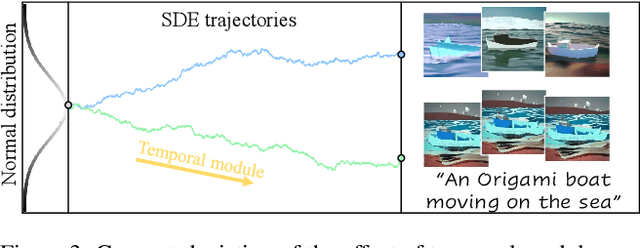
Creating a vivid video from the event or scenario in our imagination is a truly fascinating experience. Recent advancements in text-to-video synthesis have unveiled the potential to achieve this with prompts only. While text is convenient in conveying the overall scene context, it may be insufficient to control precisely. In this paper, we explore customized video generation by utilizing text as context description and motion structure (e.g. frame-wise depth) as concrete guidance. Our method, dubbed Make-Your-Video, involves joint-conditional video generation using a Latent Diffusion Model that is pre-trained for still image synthesis and then promoted for video generation with the introduction of temporal modules. This two-stage learning scheme not only reduces the computing resources required, but also improves the performance by transferring the rich concepts available in image datasets solely into video generation. Moreover, we use a simple yet effective causal attention mask strategy to enable longer video synthesis, which mitigates the potential quality degradation effectively. Experimental results show the superiority of our method over existing baselines, particularly in terms of temporal coherence and fidelity to users' guidance. In addition, our model enables several intriguing applications that demonstrate potential for practical usage.
Improved Diffusion-based Image Colorization via Piggybacked Models
Apr 21, 2023



Image colorization has been attracting the research interests of the community for decades. However, existing methods still struggle to provide satisfactory colorized results given grayscale images due to a lack of human-like global understanding of colors. Recently, large-scale Text-to-Image (T2I) models have been exploited to transfer the semantic information from the text prompts to the image domain, where text provides a global control for semantic objects in the image. In this work, we introduce a colorization model piggybacking on the existing powerful T2I diffusion model. Our key idea is to exploit the color prior knowledge in the pre-trained T2I diffusion model for realistic and diverse colorization. A diffusion guider is designed to incorporate the pre-trained weights of the latent diffusion model to output a latent color prior that conforms to the visual semantics of the grayscale input. A lightness-aware VQVAE will then generate the colorized result with pixel-perfect alignment to the given grayscale image. Our model can also achieve conditional colorization with additional inputs (e.g. user hints and texts). Extensive experiments show that our method achieves state-of-the-art performance in terms of perceptual quality.