 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee-through: Single-image Layer Decomposition for Anime Characters
Feb 03, 2026We introduce a framework that automates the transformation of static anime illustrations into manipulatable 2.5D models. Current professional workflows require tedious manual segmentation and the artistic ``hallucination'' of occluded regions to enable motion. Our approach overcomes this by decomposing a single image into fully inpainted, semantically distinct layers with inferred drawing orders. To address the scarcity of training data, we introduce a scalable engine that bootstraps high-quality supervision from commercial Live2D models, capturing pixel-perfect semantics and hidden geometry. Our methodology couples a diffusion-based Body Part Consistency Module, which enforces global geometric coherence, with a pixel-level pseudo-depth inference mechanism. This combination resolves the intricate stratification of anime characters, e.g., interleaving hair strands, allowing for dynamic layer reconstruction. We demonstrate that our approach yields high-fidelity, manipulatable models suitable for professional, real-time animation applications.
Hyperstroke: A Novel High-quality Stroke Representation for Assistive Artistic Drawing
Aug 18, 2024Assistive drawing aims to facilitate the creative process by providing intelligent guidance to artists. Existing solutions often fail to effectively model intricate stroke details or adequately address the temporal aspects of drawing. We introduce hyperstroke, a novel stroke representation designed to capture precise fine stroke details, including RGB appearance and alpha-channel opacity. Using a Vector Quantization approach, hyperstroke learns compact tokenized representations of strokes from real-life drawing videos of artistic drawing. With hyperstroke, we propose to model assistive drawing via a transformer-based architecture, to enable intuitive and user-friendly drawing applications, which are experimented in our exploratory evaluation.
Sketch2Manga: Shaded Manga Screening from Sketch with Diffusion Models
Mar 13, 2024While manga is a popular entertainment form, creating manga is tedious, especially adding screentones to the created sketch, namely manga screening. Unfortunately, there is no existing method that tailors for automatic manga screening, probably due to the difficulty of generating high-quality shaded high-frequency screentones. The classic manga screening approaches generally require user input to provide screentone exemplars or a reference manga image. The recent deep learning models enables the automatic generation by learning from a large-scale dataset. However, the state-of-the-art models still fail to generate high-quality shaded screentones due to the lack of a tailored model and high-quality manga training data. In this paper, we propose a novel sketch-to-manga framework that first generates a color illustration from the sketch and then generates a screentoned manga based on the intensity guidance. Our method significantly outperforms existing methods in generating high-quality manga with shaded high-frequency screentones.
Instance-guided Cartoon Editing with a Large-scale Dataset
Dec 04, 2023Cartoon editing, appreciated by both professional illustrators and hobbyists, allows extensive creative freedom and the development of original narratives within the cartoon domain. However, the existing literature on cartoon editing is complex and leans heavily on manual operations, owing to the challenge of automatic identification of individual character instances. Therefore, an automated segmentation of these elements becomes imperative to facilitate a variety of cartoon editing applications such as visual style editing, motion decomposition and transfer, and the computation of stereoscopic depths for an enriched visual experience. Unfortunately, most current segmentation methods are designed for natural photographs, failing to recognize from the intricate aesthetics of cartoon subjects, thus lowering segmentation quality. The major challenge stems from two key shortcomings: the rarity of high-quality cartoon dedicated datasets and the absence of competent models for high-resolution instance extraction on cartoons. To address this, we introduce a high-quality dataset of over 100k paired high-resolution cartoon images and their instance labeling masks. We also present an instance-aware image segmentation model that can generate accurate, high-resolution segmentation masks for characters in cartoon images. We present that the proposed approach enables a range of segmentation-dependent cartoon editing applications like 3D Ken Burns parallax effects, text-guided cartoon style editing, and puppet animation from illustrations and manga.
AnimeDiffusion: Anime Face Line Drawing Colorization via Diffusion Models
Mar 20, 2023It is a time-consuming and tedious work for manually colorizing anime line drawing images, which is an essential stage in cartoon animation creation pipeline. Reference-based line drawing colorization is a challenging task that relies on the precise cross-domain long-range dependency modelling between the line drawing and reference image. Existing learning methods still utilize generative adversarial networks (GANs) as one key module of their model architecture. In this paper, we propose a novel method called AnimeDiffusion using diffusion models that performs anime face line drawing colorization automatically. To the best of our knowledge, this is the first diffusion model tailored for anime content creation. In order to solve the huge training consumption problem of diffusion models, we design a hybrid training strategy, first pre-training a diffusion model with classifier-free guidance and then fine-tuning it with image reconstruction guidance. We find that with a few iterations of fine-tuning, the model shows wonderful colorization performance, as illustrated in Fig. 1. For training AnimeDiffusion, we conduct an anime face line drawing colorization benchmark dataset, which contains 31696 training data and 579 testing data. We hope this dataset can fill the gap of no available high resolution anime face dataset for colorization method evaluation. Through multiple quantitative metrics evaluated on our dataset and a user study, we demonstrate AnimeDiffusion outperforms state-of-the-art GANs-based models for anime face line drawing colorization. We also collaborate with professional artists to test and apply our AnimeDiffusion for their creation work. We release our code on https://github.com/xq-meng/AnimeDiffusion.
Screentone-Preserved Manga Retargeting
Mar 07, 2022


As a popular comic style, manga offers a unique impression by utilizing a rich set of bitonal patterns, or screentones, for illustration. However, screentones can easily be contaminated with visual-unpleasant aliasing and/or blurriness after resampling, which harms its visualization on displays of diverse resolutions. To address this problem, we propose the first manga retargeting method that synthesizes a rescaled manga image while retaining the screentone in each screened region. This is a non-trivial task as accurate region-wise segmentation remains challenging. Fortunately, the rescaled manga shares the same region-wise screentone correspondences with the original manga, which enables us to simplify the screentone synthesis problem as an anchor-based proposals selection and rearrangement problem. Specifically, we design a novel manga sampling strategy to generate aliasing-free screentone proposals, based on hierarchical grid-based anchors that connect the correspondences between the original and the target rescaled manga. Furthermore, a Recurrent Proposal Selection Module (RPSM) is proposed to adaptively integrate these proposals for target screentone synthesis. Besides, to deal with the translation insensitivity nature of screentones, we propose a translation-invariant screentone loss to facilitate the training convergence. Extensive qualitative and quantitative experiments are conducted to verify the effectiveness of our method, and notably compelling results are achieved compared to existing alternative techniques.
Invertible Tone Mapping with Selectable Styles
Oct 09, 2021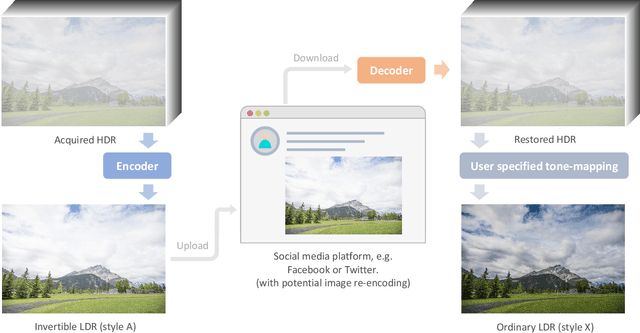

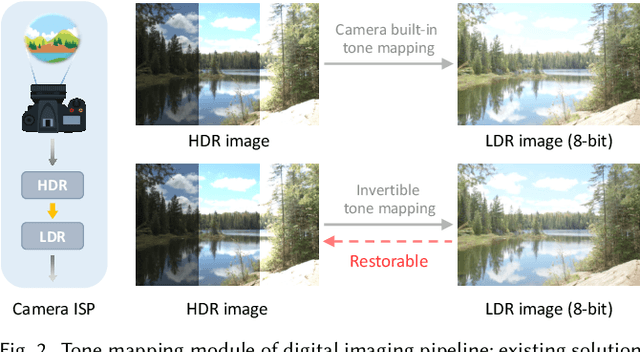
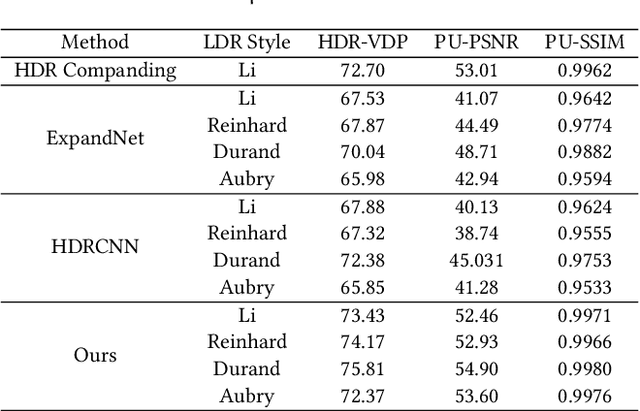
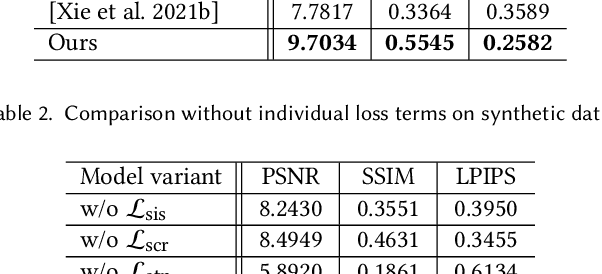
Although digital cameras can acquire high-dynamic range (HDR) images, the captured HDR information are mostly quantized to low-dynamic range (LDR) images for display compatibility and compact storage. In this paper, we propose an invertible tone mapping method that converts the multi-exposure HDR to a true LDR (8-bit per color channel) and reserves the capability to accurately restore the original HDR from this {\em invertible LDR}. Our invertible LDR can mimic the appearance of a user-selected tone mapping style. It can be shared over any existing social network platforms that may re-encode or format-convert the uploaded images, without much hurting the accuracy of the restored HDR counterpart. To achieve this, we regard the tone mapping and the restoration as coupled processes, and formulate them as an encoding-and-decoding problem through convolutional neural networks. Particularly, our model supports pluggable style modulators, each of which bakes a specific tone mapping style, and thus favors the application flexibility. Our method is evaluated with a rich variety of HDR images and multiple tone mapping operators, which shows the superiority over relevant state-of-the-art methods. Also, we conduct ablation study to justify our design and discuss the robustness and generality toward real applications.
Binocular Tone Mapping with Improved Overall Contrast and Local Details
Sep 17, 2018
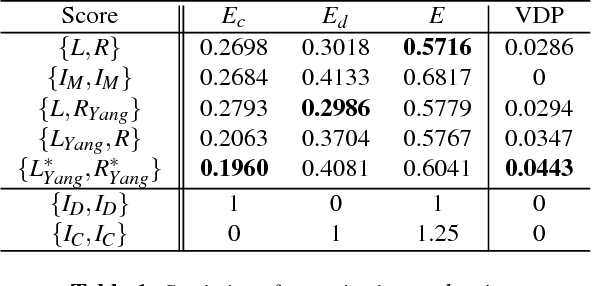
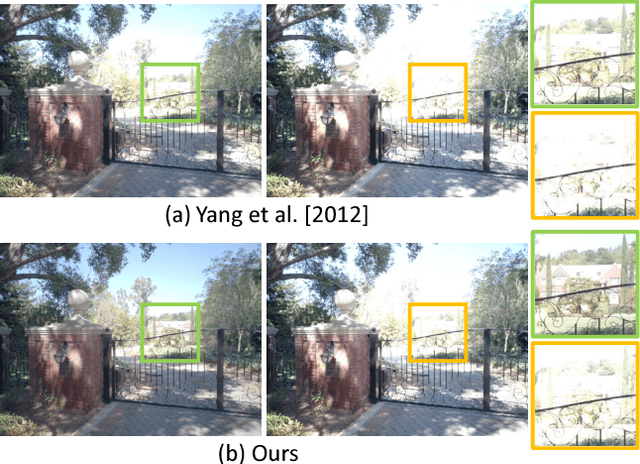
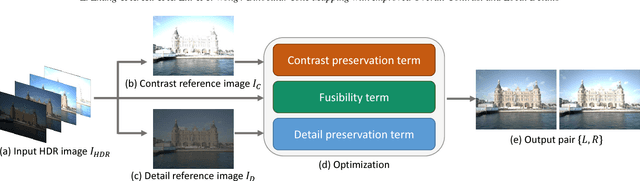
Tone mapping is a commonly used technique that maps the set of colors in high-dynamic-range (HDR) images to another set of colors in low-dynamic-range (LDR) images, to fit the need for print-outs, LCD monitors and projectors. Unfortunately, during the compression of dynamic range, the overall contrast and local details generally cannot be preserved simultaneously. Recently, with the increased use of stereoscopic devices, the notion of binocular tone mapping has been proposed in the existing research study. However, the existing research lacks the binocular perception study and is unable to generate the optimal binocular pair that presents the most visual content. In this paper, we propose a novel perception-based binocular tone mapping method, that can generate an optimal binocular image pair (generating left and right images simultaneously) from an HDR image that presents the most visual content by designing a binocular perception metric. Our method outperforms the existing method in terms of both visual and time performance.
* Accepted by Pacific Graphics 2018
Real-time Deep Video Deinterlacing
Aug 01, 2017
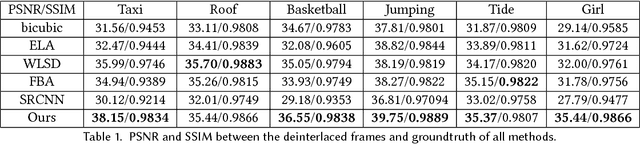


Interlacing is a widely used technique, for television broadcast and video recording, to double the perceived frame rate without increasing the bandwidth. But it presents annoying visual artifacts, such as flickering and silhouette "serration," during the playback. Existing state-of-the-art deinterlacing methods either ignore the temporal information to provide real-time performance but lower visual quality, or estimate the motion for better deinterlacing but with a trade-off of higher computational cost. In this paper, we present the first and novel deep convolutional neural networks (DCNNs) based method to deinterlace with high visual quality and real-time performance. Unlike existing models for super-resolution problems which relies on the translation-invariant assumption, our proposed DCNN model utilizes the temporal information from both the odd and even half frames to reconstruct only the missing scanlines, and retains the given odd and even scanlines for producing the full deinterlaced frames. By further introducing a layer-sharable architecture, our system can achieve real-time performance on a single GPU. Experiments shows that our method outperforms all existing methods, in terms of reconstruction accuracy and computational performance.