 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Thought Re-ranking for Image Retrieval Tasks
Sep 18, 2025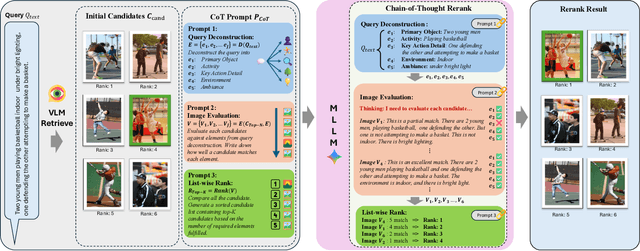
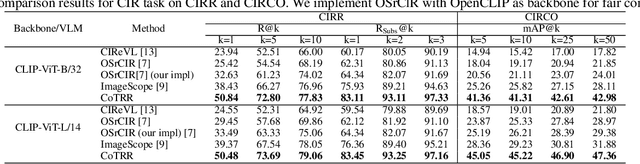
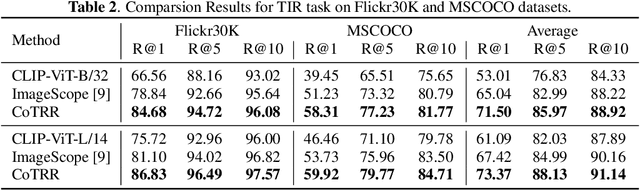
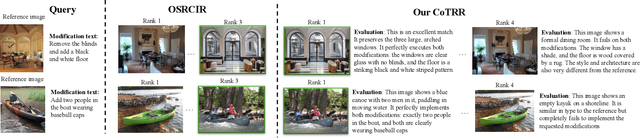
Image retrieval remains a fundamental yet challenging problem in computer vision. While recent advances in Multimodal Large Language Models (MLLMs) have demonstrated strong reasoning capabilities, existing methods typically employ them only for evaluation, without involving them directly in the ranking process. As a result, their rich multimodal reasoning abilities remain underutilized, leading to suboptimal performance. In this paper, we propose a novel Chain-of-Thought Re-Ranking (CoTRR) method to address this issue. Specifically, we design a listwise ranking prompt that enables MLLM to directly participate in re-ranking candidate images. This ranking process is grounded in an image evaluation prompt, which assesses how well each candidate aligns with users query. By allowing MLLM to perform listwise reasoning, our method supports global comparison, consistent reasoning, and interpretable decision-making - all of which are essential for accurate image retrieval. To enable structured and fine-grained analysis, we further introduce a query deconstruction prompt, which breaks down the original query into multiple semantic components. Extensive experiments on five datasets demonstrate the effectiveness of our CoTRR method, which achieves state-of-the-art performance across three image retrieval tasks, including text-to-image retrieval (TIR), composed image retrieval (CIR) and chat-based image retrieval (Chat-IR). Our code is available at https://github.com/freshfish15/CoTRR .
Consistency Regularization for Complementary Clothing Recommendations
Nov 19, 2024



This paper reports on the development of a Consistency Regularized model for Bayesian Personalized Ranking (CR-BPR), addressing to the drawbacks in existing complementary clothing recommendation methods, namely limited consistency and biased learning caused by diverse feature scale of multi-modal data. Compared to other product types, fashion preferences are inherently subjective and more personal, and fashion are often presented, not by individual clothing product, but with other complementary product(s) in a well coordinated fashion outfit. Current complementary-product recommendation studies primarily focus on user preference and product matching, this study further emphasizes the consistency observed in user-product interactions as well as product-product interactions, in the specific context of clothing matching. Most traditional approaches often underplayed the impact of existing wardrobe items on future matching choices, resulting in less effective preference prediction models. Moreover, many multi-modal information based models overlook the limitations arising from various feature scales being involved. To address these gaps, the CR-BPR model integrates collaborative filtering techniques to incorporate both user preference and product matching modeling, with a unique focus on consistency regularization for each aspect. Additionally, the incorporation of a feature scaling process further addresses the imbalances caused by different feature scales, ensuring that the model can effectively handle multi-modal data without being skewed by any particular type of feature. The effectiveness of the CR-BPR model was validated through detailed analysis involving two benchmark datasets. The results confirmed that the proposed approach significantly outperforms existing models.
Computer-aided Colorization State-of-the-science: A Survey
Oct 03, 2024This paper reviews published research in the field of computer-aided colorization technology. We argue that the colorization task originates from computer graphics, prospers by introducing computer vision, and tends to the fusion of vision and graphics, so we put forward our taxonomy and organize the whole paper chronologically. We extend the existing reconstruction-based colorization evaluation techniques, considering that aesthetic assessment of colored images should be introduced to ensure that colorization satisfies human visual-related requirements and emotions more closely. We perform the colorization aesthetic assessment on seven representative unconditional colorization models and discuss the difference between our assessment and the existing reconstruction-based metrics. Finally, this paper identifies unresolved issues and proposes fruitful areas for future research and development. Access to the project associated with this survey can be obtained at https://github.com/DanielCho-HK/Colorization.
KTPFormer: Kinematics and Trajectory Prior Knowledge-Enhanced Transformer for 3D Human Pose Estimation
Apr 02, 2024This paper presents a novel Kinematics and Trajectory Prior Knowledge-Enhanced Transformer (KTPFormer), which overcomes the weakness in existing transformer-based methods for 3D human pose estimation that the derivation of Q, K, V vectors in their self-attention mechanisms are all based on simple linear mapping. We propose two prior attention modules, namely Kinematics Prior Attention (KPA) and Trajectory Prior Attention (TPA) to take advantage of the known anatomical structure of the human body and motion trajectory information, to facilitate effective learning of global dependencies and features in the multi-head self-attention. KPA models kinematic relationships in the human body by constructing a topology of kinematics, while TPA builds a trajectory topology to learn the information of joint motion trajectory across frames. Yielding Q, K, V vectors with prior knowledge, the two modules enable KTPFormer to model both spatial and temporal correlations simultaneously. Extensive experiments on three benchmarks (Human3.6M, MPI-INF-3DHP and HumanEva) show that KTPFormer achieves superior performance in comparison to state-of-the-art methods. More importantly, our KPA and TPA modules have lightweight plug-and-play designs and can be integrated into various transformer-based networks (i.e., diffusion-based) to improve the performance with only a very small increase in the computational overhead. The code is available at: https://github.com/JihuaPeng/KTPFormer.
SGDiff: A Style Guided Diffusion Model for Fashion Synthesis
Aug 15, 2023



This paper reports on the development of \textbf{a novel style guided diffusion model (SGDiff)} which overcomes certain weaknesses inherent in existing models for image synthesis. The proposed SGDiff combines image modality with a pretrained text-to-image diffusion model to facilitate creative fashion image synthesis. It addresses the limitations of text-to-image diffusion models by incorporating supplementary style guidance, substantially reducing training costs, and overcoming the difficulties of controlling synthesized styles with text-only inputs. This paper also introduces a new dataset -- SG-Fashion, specifically designed for fashion image synthesis applications, offering high-resolution images and an extensive range of garment categories. By means of comprehensive ablation study, we examine the application of classifier-free guidance to a variety of conditions and validate the effectiveness of the proposed model for generating fashion images of the desired categories, product attributes, and styles. The contributions of this paper include a novel classifier-free guidance method for multi-modal feature fusion, a comprehensive dataset for fashion image synthesis application, a thorough investigation on conditioned text-to-image synthesis, and valuable insights for future research in the text-to-image synthesis domain. The code and dataset are available at: \url{https://github.com/taited/SGDiff}.
Computational Technologies for Fashion Recommendation: A Survey
Jun 06, 2023


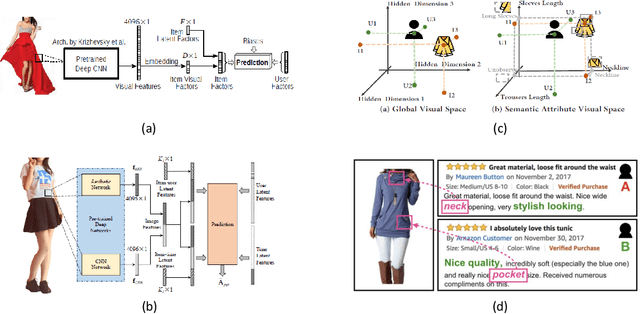
Fashion recommendation is a key research field in computational fashion research and has attracted considerable interest in the computer vision, multimedia, and information retrieval communities in recent years. Due to the great demand for applications, various fashion recommendation tasks, such as personalized fashion product recommendation, complementary (mix-and-match) recommendation, and outfit recommendation, have been posed and explored in the literature. The continuing research attention and advances impel us to look back and in-depth into the field for a better understanding. In this paper, we comprehensively review recent research efforts on fashion recommendation from a technological perspective. We first introduce fashion recommendation at a macro level and analyse its characteristics and differences with general recommendation tasks. We then clearly categorize different fashion recommendation efforts into several sub-tasks and focus on each sub-task in terms of its problem formulation, research focus, state-of-the-art methods, and limitations. We also summarize the datasets proposed in the literature for use in fashion recommendation studies to give readers a brief illustration. Finally, we discuss several promising directions for future research in this field. Overall, this survey systematically reviews the development of fashion recommendation research. It also discusses the current limitations and gaps between academic research and the real needs of the fashion industry. In the process, we offer a deep insight into how the fashion industry could benefit from fashion recommendation technologies. the computational technologies of fashion recommendation.
DETR-based Layered Clothing Segmentation and Fine-Grained Attribute Recognition
Apr 17, 2023

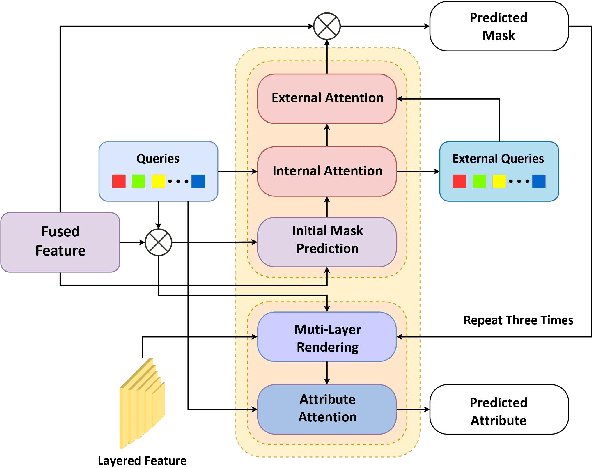

Clothing segmentation and fine-grained attribute recognition are challenging tasks at the crossing of computer vision and fashion, which segment the entire ensemble clothing instances as well as recognize detailed attributes of the clothing products from any input human images. Many new models have been developed for the tasks in recent years, nevertheless the segmentation accuracy is less than satisfactory in case of layered clothing or fashion products in different scales. In this paper, a new DEtection TRansformer (DETR) based method is proposed to segment and recognize fine-grained attributes of ensemble clothing instances with high accuracy. In this model, we propose a \textbf{multi-layered attention module} by aggregating features of different scales, determining the various scale components of a single instance, and merging them together. We train our model on the Fashionpedia dataset and demonstrate our method surpasses SOTA models in tasks of layered clothing segmentation and fine-grained attribute recognition.
AnimeDiffusion: Anime Face Line Drawing Colorization via Diffusion Models
Mar 20, 2023It is a time-consuming and tedious work for manually colorizing anime line drawing images, which is an essential stage in cartoon animation creation pipeline. Reference-based line drawing colorization is a challenging task that relies on the precise cross-domain long-range dependency modelling between the line drawing and reference image. Existing learning methods still utilize generative adversarial networks (GANs) as one key module of their model architecture. In this paper, we propose a novel method called AnimeDiffusion using diffusion models that performs anime face line drawing colorization automatically. To the best of our knowledge, this is the first diffusion model tailored for anime content creation. In order to solve the huge training consumption problem of diffusion models, we design a hybrid training strategy, first pre-training a diffusion model with classifier-free guidance and then fine-tuning it with image reconstruction guidance. We find that with a few iterations of fine-tuning, the model shows wonderful colorization performance, as illustrated in Fig. 1. For training AnimeDiffusion, we conduct an anime face line drawing colorization benchmark dataset, which contains 31696 training data and 579 testing data. We hope this dataset can fill the gap of no available high resolution anime face dataset for colorization method evaluation. Through multiple quantitative metrics evaluated on our dataset and a user study, we demonstrate AnimeDiffusion outperforms state-of-the-art GANs-based models for anime face line drawing colorization. We also collaborate with professional artists to test and apply our AnimeDiffusion for their creation work. We release our code on https://github.com/xq-meng/AnimeDiffusion.
Attention-Aware Anime Line Drawing Colorization
Jan 05, 2023Automatic colorization of anime line drawing has attracted much attention in recent years since it can substantially benefit the animation industry. User-hint based methods are the mainstream approach for line drawing colorization, while reference-based methods offer a more intuitive approach. Nevertheless, although reference-based methods can improve feature aggregation of the reference image and the line drawing, the colorization results are not compelling in terms of color consistency or semantic correspondence. In this paper, we introduce an attention-based model for anime line drawing colorization, in which a channel-wise and spatial-wise Convolutional Attention module is used to improve the ability of the encoder for feature extraction and key area perception, and a Stop-Gradient Attention module with cross-attention and self-attention is used to tackle the cross-domain long-range dependency problem. Extensive experiments show that our method outperforms other SOTA methods, with more accurate line structure and semantic color information.
Modeling Field-level Factor Interactions for Fashion Recommendation
Apr 08, 2022
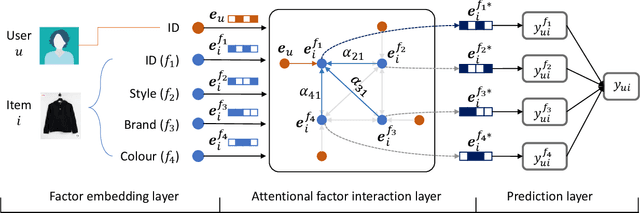
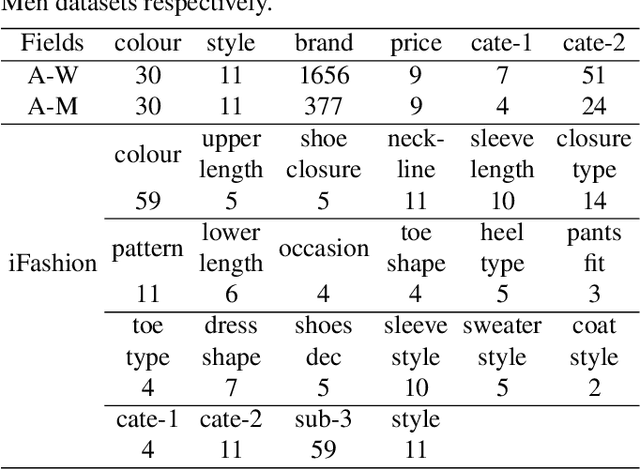
Personalized fashion recommendation aims to explore patterns from historical interactions between users and fashion items and thereby predict the future ones. It is challenging due to the sparsity of the interaction data and the diversity of user preference in fashion. To tackle the challenge, this paper investigates multiple factor fields in fashion domain, such as colour, style, brand, and tries to specify the implicit user-item interaction into field level. Specifically, an attentional factor field interaction graph (AFFIG) approach is proposed which models both the user-factor interactions and cross-field factors interactions for predicting the recommendation probability at specific field. In addition, an attention mechanism is equipped to aggregate the cross-field factor interactions for each field. Extensive experiments have been conducted on three E-Commerce fashion datasets and the results demonstrate the effectiveness of the proposed method for fashion recommendation. The influence of various factor fields on recommendation in fashion domain is also discussed through experiments.