 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervision-by-Hallucination-and-Transfer: A Weakly-Supervised Approach for Robust and Precise Facial Landmark Detection
Jan 19, 2026High-precision facial landmark detection (FLD) relies on high-resolution deep feature representations. However, low-resolution face images or the compression (via pooling or strided convolution) of originally high-resolution images hinder the learning of such features, thereby reducing FLD accuracy. Moreover, insufficient training data and imprecise annotations further degrade performance. To address these challenges, we propose a weakly-supervised framework called Supervision-by-Hallucination-and-Transfer (SHT) for more robust and precise FLD. SHT contains two novel mutually enhanced modules: Dual Hallucination Learning Network (DHLN) and Facial Pose Transfer Network (FPTN). By incorporating FLD and face hallucination tasks, DHLN is able to learn high-resolution representations with low-resolution inputs for recovering both facial structures and local details and generating more effective landmark heatmaps. Then, by transforming faces from one pose to another, FPTN can further improve landmark heatmaps and faces hallucinated by DHLN for detecting more accurate landmarks. To the best of our knowledge, this is the first study to explore weakly-supervised FLD by integrating face hallucination and facial pose transfer tasks. Experimental results of both face hallucination and FLD demonstrate that our method surpasses state-of-the-art techniques.
FGTBT: Frequency-Guided Task-Balancing Transformer for Unified Facial Landmark Detection
Jan 19, 2026Recently, deep learning based facial landmark detection (FLD) methods have achieved considerable success. However, in challenging scenarios such as large pose variations, illumination changes, and facial expression variations, they still struggle to accurately capture the geometric structure of the face, resulting in performance degradation. Moreover, the limited size and diversity of existing FLD datasets hinder robust model training, leading to reduced detection accuracy. To address these challenges, we propose a Frequency-Guided Task-Balancing Transformer (FGTBT), which enhances facial structure perception through frequency-domain modeling and multi-dataset unified training. Specifically, we propose a novel Fine-Grained Multi-Task Balancing loss (FMB-loss), which moves beyond coarse task-level balancing by assigning weights to individual landmarks based on their occurrence across datasets. This enables more effective unified training and mitigates the issue of inconsistent gradient magnitudes. Additionally, a Frequency-Guided Structure-Aware (FGSA) model is designed to utilize frequency-guided structure injection and regularization to help learn facial structure constraints. Extensive experimental results on popular benchmark datasets demonstrate that the integration of the proposed FMB-loss and FGSA model into our FGTBT framework achieves performance comparable to state-of-the-art methods. The code is available at https://github.com/Xi0ngxinyu/FGTBT.
FaNe: Towards Fine-Grained Cross-Modal Contrast with False-Negative Reduction and Text-Conditioned Sparse Attention
Nov 15, 2025Medical vision-language pre-training (VLP) offers significant potential for advancing medical image understanding by leveraging paired image-report data. However, existing methods are limited by Fa}lse Negatives (FaNe) induced by semantically similar texts and insufficient fine-grained cross-modal alignment. To address these limitations, we propose FaNe, a semantic-enhanced VLP framework. To mitigate false negatives, we introduce a semantic-aware positive pair mining strategy based on text-text similarity with adaptive normalization. Furthermore, we design a text-conditioned sparse attention pooling module to enable fine-grained image-text alignment through localized visual representations guided by textual cues. To strengthen intra-modal discrimination, we develop a hard-negative aware contrastive loss that adaptively reweights semantically similar negatives. Extensive experiments on five downstream medical imaging benchmarks demonstrate that FaNe achieves state-of-the-art performance across image classification, object detection, and semantic segmentation, validating the effectiveness of our framework.
Joker: Joint Optimization Framework for Lightweight Kernel Machines
May 23, 2025



Kernel methods are powerful tools for nonlinear learning with well-established theory. The scalability issue has been their long-standing challenge. Despite the existing success, there are two limitations in large-scale kernel methods: (i) The memory overhead is too high for users to afford; (ii) existing efforts mainly focus on kernel ridge regression (KRR), while other models lack study. In this paper, we propose Joker, a joint optimization framework for diverse kernel models, including KRR, logistic regression, and support vector machines. We design a dual block coordinate descent method with trust region (DBCD-TR) and adopt kernel approximation with randomized features, leading to low memory costs and high efficiency in large-scale learning. Experiments show that Joker saves up to 90\% memory but achieves comparable training time and performance (or even better) than the state-of-the-art methods.
Prototype Contrastive Consistency Learning for Semi-Supervised Medical Image Segmentation
Feb 10, 2025Medical image segmentation is a crucial task in medical image analysis, but it can be very challenging especially when there are less labeled data but with large unlabeled data. Contrastive learning has proven to be effective for medical image segmentation in semi-supervised learning by constructing contrastive samples from partial pixels. However, although previous contrastive learning methods can mine semantic information from partial pixels within images, they ignore the whole context information of unlabeled images, which is very important to precise segmentation. In order to solve this problem, we propose a novel prototype contrastive learning method called Prototype Contrastive Consistency Segmentation (PCCS) for semi-supervised medical image segmentation. The core idea is to enforce the prototypes of the same semantic class to be closer and push the prototypes in different semantic classes far away from each other. Specifically, we construct a signed distance map and an uncertainty map from unlabeled images. The signed distance map is used to construct prototypes for contrastive learning, and then we estimate the prototype uncertainty from the uncertainty map as trade-off among prototypes. In order to obtain better prototypes, based on the student-teacher architecture, a new mechanism named prototype updating prototype is designed to assist in updating the prototypes for contrastive learning. In addition, we propose an uncertainty-consistency loss to mine more reliable information from unlabeled data. Extensive experiments on medical image segmentation demonstrate that PCCS achieves better segmentation performance than the state-of-the-art methods. The code is available at https://github.com/comphsh/PCCS.
Precise Facial Landmark Detection by Dynamic Semantic Aggregation Transformer
Dec 01, 2024



At present, deep neural network methods have played a dominant role in face alignment field. However, they generally use predefined network structures to predict landmarks, which tends to learn general features and leads to mediocre performance, e.g., they perform well on neutral samples but struggle with faces exhibiting large poses or occlusions. Moreover, they cannot effectively deal with semantic gaps and ambiguities among features at different scales, which may hinder them from learning efficient features. To address the above issues, in this paper, we propose a Dynamic Semantic-Aggregation Transformer (DSAT) for more discriminative and representative feature (i.e., specialized feature) learning. Specifically, a Dynamic Semantic-Aware (DSA) model is first proposed to partition samples into subsets and activate the specific pathways for them by estimating the semantic correlations of feature channels, making it possible to learn specialized features from each subset. Then, a novel Dynamic Semantic Specialization (DSS) model is designed to mine the homogeneous information from features at different scales for eliminating the semantic gap and ambiguities and enhancing the representation ability. Finally, by integrating the DSA model and DSS model into our proposed DSAT in both dynamic architecture and dynamic parameter manners, more specialized features can be learned for achieving more precise face alignment. It is interesting to show that harder samples can be handled by activating more feature channels. Extensive experiments on popular face alignment datasets demonstrate that our proposed DSAT outperforms state-of-the-art models in the literature.Our code is available at https://github.com/GERMINO-LiuHe/DSAT.
Low-Light Enhancement Effect on Classification and Detection: An Empirical Study
Sep 22, 2024Low-light images are commonly encountered in real-world scenarios, and numerous low-light image enhancement (LLIE) methods have been proposed to improve the visibility of these images. The primary goal of LLIE is to generate clearer images that are more visually pleasing to humans. However, the impact of LLIE methods in high-level vision tasks, such as image classification and object detection, which rely on high-quality image datasets, is not well {explored}. To explore the impact, we comprehensively evaluate LLIE methods on these high-level vision tasks by utilizing an empirical investigation comprising image classification and object detection experiments. The evaluation reveals a dichotomy: {\textit{While Low-Light Image Enhancement (LLIE) methods enhance human visual interpretation, their effect on computer vision tasks is inconsistent and can sometimes be harmful. }} Our findings suggest a disconnect between image enhancement for human visual perception and for machine analysis, indicating a need for LLIE methods tailored to support high-level vision tasks effectively. This insight is crucial for the development of LLIE techniques that align with the needs of both human and machine vision.
CodeEnhance: A Codebook-Driven Approach for Low-Light Image Enhancement
Apr 08, 2024Low-light image enhancement (LLIE) aims to improve low-illumination images. However, existing methods face two challenges: (1) uncertainty in restoration from diverse brightness degradations; (2) loss of texture and color information caused by noise suppression and light enhancement. In this paper, we propose a novel enhancement approach, CodeEnhance, by leveraging quantized priors and image refinement to address these challenges. In particular, we reframe LLIE as learning an image-to-code mapping from low-light images to discrete codebook, which has been learned from high-quality images. To enhance this process, a Semantic Embedding Module (SEM) is introduced to integrate semantic information with low-level features, and a Codebook Shift (CS) mechanism, designed to adapt the pre-learned codebook to better suit the distinct characteristics of our low-light dataset. Additionally, we present an Interactive Feature Transformation (IFT) module to refine texture and color information during image reconstruction, allowing for interactive enhancement based on user preferences. Extensive experiments on both real-world and synthetic benchmarks demonstrate that the incorporation of prior knowledge and controllable information transfer significantly enhances LLIE performance in terms of quality and fidelity. The proposed CodeEnhance exhibits superior robustness to various degradations, including uneven illumination, noise, and color distortion.
NPSVC++: Nonparallel Classifiers Encounter Representation Learning
Feb 08, 2024



This paper focuses on a specific family of classifiers called nonparallel support vector classifiers (NPSVCs). Different from typical classifiers, the training of an NPSVC involves the minimization of multiple objectives, resulting in the potential concerns of feature suboptimality and class dependency. Consequently, no effective learning scheme has been established to improve NPSVCs' performance through representation learning, especially deep learning. To break this bottleneck, we develop NPSVC++ based on multi-objective optimization, enabling the end-to-end learning of NPSVC and its features. By pursuing Pareto optimality, NPSVC++ theoretically ensures feature optimality across classes, hence effectively overcoming the two issues above. A general learning procedure via duality optimization is proposed, based on which we provide two applicable instances, K-NPSVC++ and D-NPSVC++. The experiments show their superiority over the existing methods and verify the efficacy of NPSVC++.
Computational Technologies for Fashion Recommendation: A Survey
Jun 06, 2023


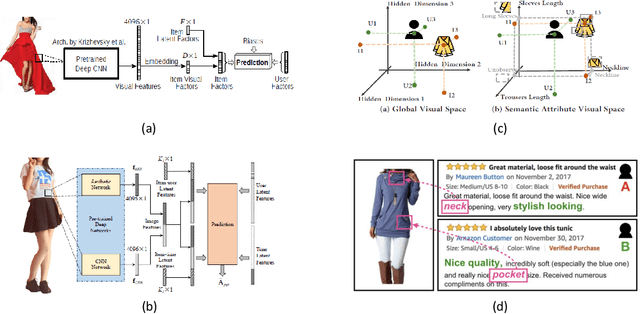
Fashion recommendation is a key research field in computational fashion research and has attracted considerable interest in the computer vision, multimedia, and information retrieval communities in recent years. Due to the great demand for applications, various fashion recommendation tasks, such as personalized fashion product recommendation, complementary (mix-and-match) recommendation, and outfit recommendation, have been posed and explored in the literature. The continuing research attention and advances impel us to look back and in-depth into the field for a better understanding. In this paper, we comprehensively review recent research efforts on fashion recommendation from a technological perspective. We first introduce fashion recommendation at a macro level and analyse its characteristics and differences with general recommendation tasks. We then clearly categorize different fashion recommendation efforts into several sub-tasks and focus on each sub-task in terms of its problem formulation, research focus, state-of-the-art methods, and limitations. We also summarize the datasets proposed in the literature for use in fashion recommendation studies to give readers a brief illustration. Finally, we discuss several promising directions for future research in this field. Overall, this survey systematically reviews the development of fashion recommendation research. It also discusses the current limitations and gaps between academic research and the real needs of the fashion industry. In the process, we offer a deep insight into how the fashion industry could benefit from fashion recommendation technologies. the computational technologies of fashion recommendation.