 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecise Facial Landmark Detection by Reference Heatmap Transformer
Mar 14, 2023
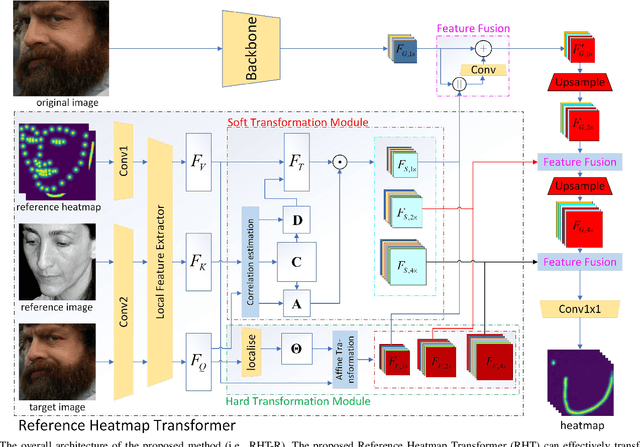
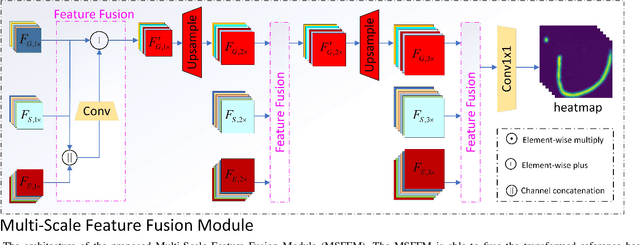

Most facial landmark detection methods predict landmarks by mapping the input facial appearance features to landmark heatmaps and have achieved promising results. However, when the face image is suffering from large poses, heavy occlusions and complicated illuminations, they cannot learn discriminative feature representations and effective facial shape constraints, nor can they accurately predict the value of each element in the landmark heatmap, limiting their detection accuracy. To address this problem, we propose a novel Reference Heatmap Transformer (RHT) by introducing reference heatmap information for more precise facial landmark detection. The proposed RHT consists of a Soft Transformation Module (STM) and a Hard Transformation Module (HTM), which can cooperate with each other to encourage the accurate transformation of the reference heatmap information and facial shape constraints. Then, a Multi-Scale Feature Fusion Module (MSFFM) is proposed to fuse the transformed heatmap features and the semantic features learned from the original face images to enhance feature representations for producing more accurate target heatmaps. To the best of our knowledge, this is the first study to explore how to enhance facial landmark detection by transforming the reference heatmap information. The experimental results from challenging benchmark datasets demonstrate that our proposed method outperforms the state-of-the-art methods in the literature.
Robust and Precise Facial Landmark Detection by Self-Calibrated Pose Attention Network
Dec 23, 2021
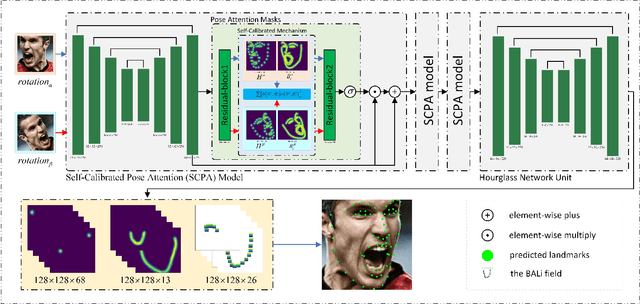


Current fully-supervised facial landmark detection methods have progressed rapidly and achieved remarkable performance. However, they still suffer when coping with faces under large poses and heavy occlusions for inaccurate facial shape constraints and insufficient labeled training samples. In this paper, we propose a semi-supervised framework, i.e., a Self-Calibrated Pose Attention Network (SCPAN) to achieve more robust and precise facial landmark detection in challenging scenarios. To be specific, a Boundary-Aware Landmark Intensity (BALI) field is proposed to model more effective facial shape constraints by fusing boundary and landmark intensity field information. Moreover, a Self-Calibrated Pose Attention (SCPA) model is designed to provide a self-learned objective function that enforces intermediate supervision without label information by introducing a self-calibrated mechanism and a pose attention mask. We show that by integrating the BALI fields and SCPA model into a novel self-calibrated pose attention network, more facial prior knowledge can be learned and the detection accuracy and robustness of our method for faces with large poses and heavy occlusions have been improved. The experimental results obtained for challenging benchmark datasets demonstrate that our approach outperforms state-of-the-art methods in the literature.