 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Lure: A Synthetic Narrative-Driven Approach to Compromise Large Language Models
May 23, 2025In the era of rapid generative AI development, interactions between humans and large language models face significant misusing risks. Previous research has primarily focused on black-box scenarios using human-guided prompts and white-box scenarios leveraging gradient-based LLM generation methods, neglecting the possibility that LLMs can act not only as victim models, but also as attacker models to harm other models. We proposes a novel jailbreaking method inspired by the Chain-of-Thought mechanism, where the attacker model uses mission transfer to conceal harmful user intent in dialogue and generates chained narrative lures to stimulate the reasoning capabilities of victim models, leading to successful jailbreaking. To enhance the attack success rate, we introduce a helper model that performs random narrative optimization on the narrative lures during multi-turn dialogues while ensuring alignment with the original intent, enabling the optimized lures to bypass the safety barriers of victim models effectively. Our experiments reveal that models with weaker safety mechanisms exhibit stronger attack capabilities, demonstrating that models can not only be exploited, but also help harm others. By incorporating toxicity scores, we employ third-party models to evaluate the harmfulness of victim models' responses to jailbreaking attempts. The study shows that using refusal keywords as an evaluation metric for attack success rates is significantly flawed because it does not assess whether the responses guide harmful questions, while toxicity scores measure the harm of generated content with more precision and its alignment with harmful questions. Our approach demonstrates outstanding performance, uncovering latent vulnerabilities in LLMs and providing data-driven feedback to optimize LLM safety mechanisms. We also discuss two defensive strategies to offer guidance on improving defense mechanisms.
$β$-GNN: A Robust Ensemble Approach Against Graph Structure Perturbation
Mar 26, 2025
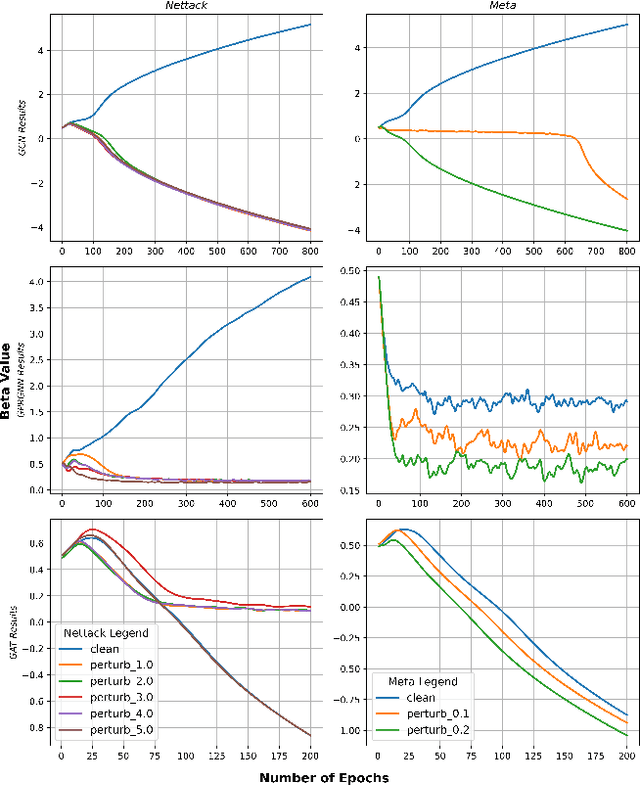
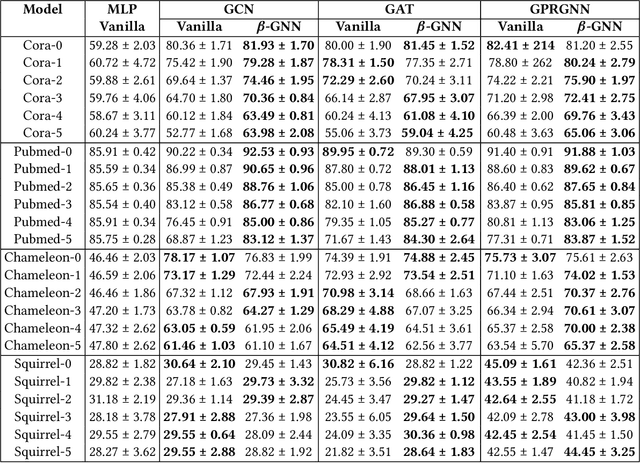
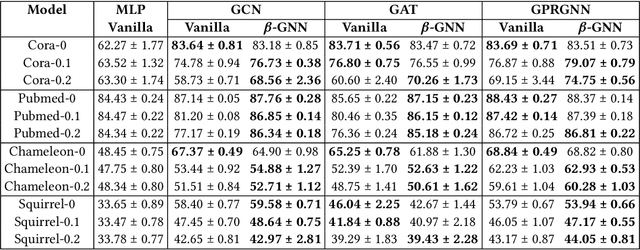
Graph Neural Networks (GNNs) are playing an increasingly important role in the efficient operation and security of computing systems, with applications in workload scheduling, anomaly detection, and resource management. However, their vulnerability to network perturbations poses a significant challenge. We propose $\beta$-GNN, a model enhancing GNN robustness without sacrificing clean data performance. $\beta$-GNN uses a weighted ensemble, combining any GNN with a multi-layer perceptron. A learned dynamic weight, $\beta$, modulates the GNN's contribution. This $\beta$ not only weights GNN influence but also indicates data perturbation levels, enabling proactive mitigation. Experimental results on diverse datasets show $\beta$-GNN's superior adversarial accuracy and attack severity quantification. Crucially, $\beta$-GNN avoids perturbation assumptions, preserving clean data structure and performance.
Game-Theoretic Machine Unlearning: Mitigating Extra Privacy Leakage
Nov 06, 2024With the extensive use of machine learning technologies, data providers encounter increasing privacy risks. Recent legislation, such as GDPR, obligates organizations to remove requested data and its influence from a trained model. Machine unlearning is an emerging technique designed to enable machine learning models to erase users' private information. Although several efficient machine unlearning schemes have been proposed, these methods still have limitations. First, removing the contributions of partial data may lead to model performance degradation. Second, discrepancies between the original and generated unlearned models can be exploited by attackers to obtain target sample's information, resulting in additional privacy leakage risks. To address above challenges, we proposed a game-theoretic machine unlearning algorithm that simulates the competitive relationship between unlearning performance and privacy protection. This algorithm comprises unlearning and privacy modules. The unlearning module possesses a loss function composed of model distance and classification error, which is used to derive the optimal strategy. The privacy module aims to make it difficult for an attacker to infer membership information from the unlearned data, thereby reducing the privacy leakage risk during the unlearning process. Additionally, the experimental results on real-world datasets demonstrate that this game-theoretic unlearning algorithm's effectiveness and its ability to generate an unlearned model with a performance similar to that of the retrained one while mitigating extra privacy leakage risks.
Towards Symbolic XAI -- Explanation Through Human Understandable Logical Relationships Between Features
Aug 30, 2024Explainable Artificial Intelligence (XAI) plays a crucial role in fostering transparency and trust in AI systems, where traditional XAI approaches typically offer one level of abstraction for explanations, often in the form of heatmaps highlighting single or multiple input features. However, we ask whether abstract reasoning or problem-solving strategies of a model may also be relevant, as these align more closely with how humans approach solutions to problems. We propose a framework, called Symbolic XAI, that attributes relevance to symbolic queries expressing logical relationships between input features, thereby capturing the abstract reasoning behind a model's predictions. The methodology is built upon a simple yet general multi-order decomposition of model predictions. This decomposition can be specified using higher-order propagation-based relevance methods, such as GNN-LRP, or perturbation-based explanation methods commonly used in XAI. The effectiveness of our framework is demonstrated in the domains of natural language processing (NLP), vision, and quantum chemistry (QC), where abstract symbolic domain knowledge is abundant and of significant interest to users. The Symbolic XAI framework provides an understanding of the model's decision-making process that is both flexible for customization by the user and human-readable through logical formulas.
Precise Facial Landmark Detection by Reference Heatmap Transformer
Mar 14, 2023
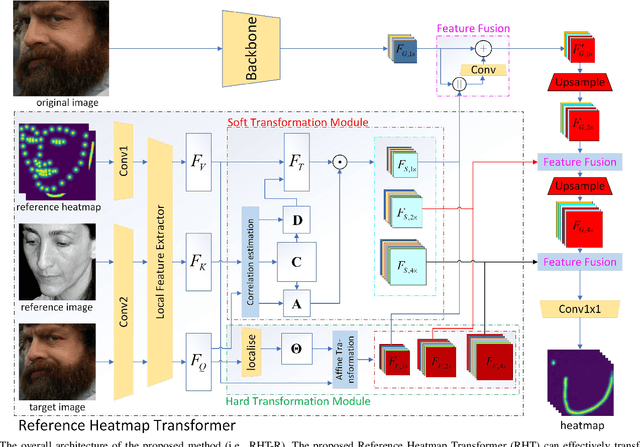
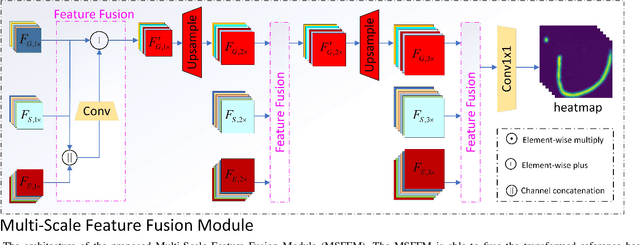

Most facial landmark detection methods predict landmarks by mapping the input facial appearance features to landmark heatmaps and have achieved promising results. However, when the face image is suffering from large poses, heavy occlusions and complicated illuminations, they cannot learn discriminative feature representations and effective facial shape constraints, nor can they accurately predict the value of each element in the landmark heatmap, limiting their detection accuracy. To address this problem, we propose a novel Reference Heatmap Transformer (RHT) by introducing reference heatmap information for more precise facial landmark detection. The proposed RHT consists of a Soft Transformation Module (STM) and a Hard Transformation Module (HTM), which can cooperate with each other to encourage the accurate transformation of the reference heatmap information and facial shape constraints. Then, a Multi-Scale Feature Fusion Module (MSFFM) is proposed to fuse the transformed heatmap features and the semantic features learned from the original face images to enhance feature representations for producing more accurate target heatmaps. To the best of our knowledge, this is the first study to explore how to enhance facial landmark detection by transforming the reference heatmap information. The experimental results from challenging benchmark datasets demonstrate that our proposed method outperforms the state-of-the-art methods in the literature.
Correlated Differential Privacy: Feature Selection in Machine Learning
Oct 07, 2020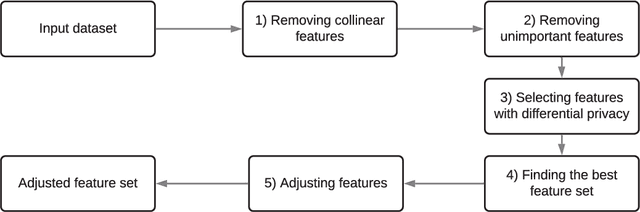
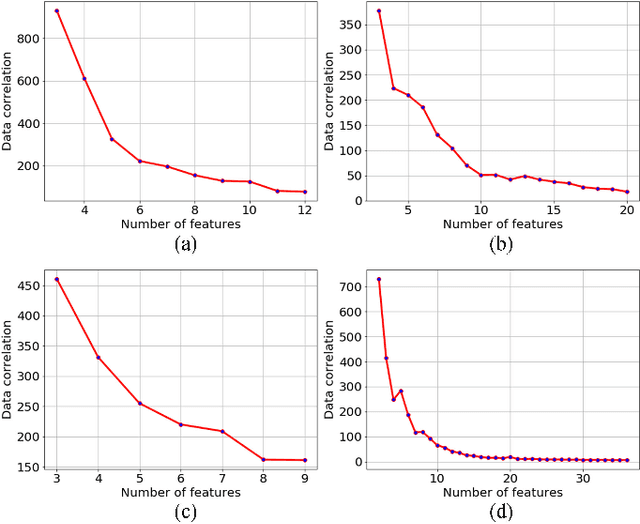
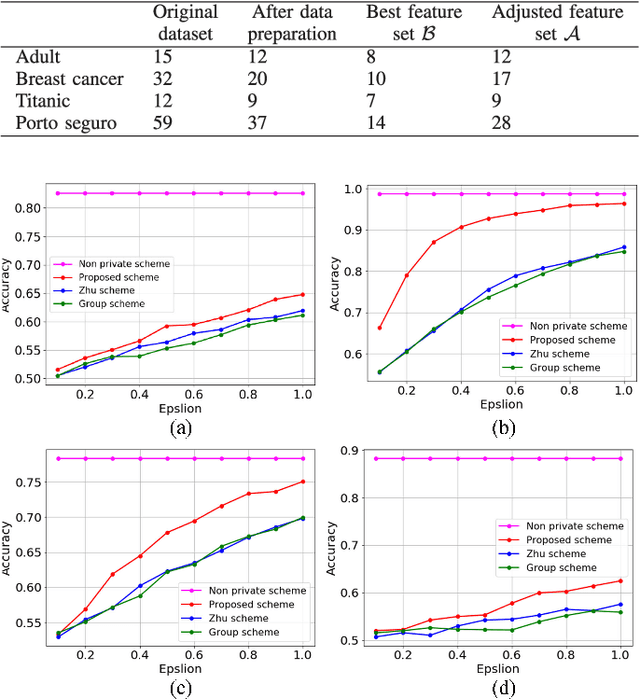
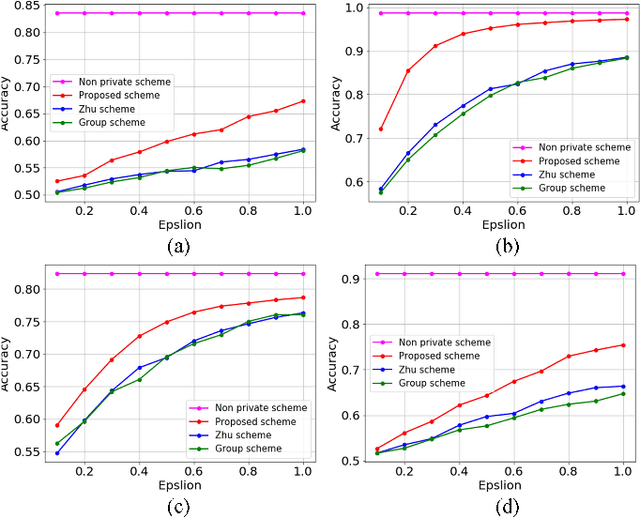
Privacy preserving in machine learning is a crucial issue in industry informatics since data used for training in industries usually contain sensitive information. Existing differentially private machine learning algorithms have not considered the impact of data correlation, which may lead to more privacy leakage than expected in industrial applications. For example, data collected for traffic monitoring may contain some correlated records due to temporal correlation or user correlation. To fill this gap, we propose a correlation reduction scheme with differentially private feature selection considering the issue of privacy loss when data have correlation in machine learning tasks. %The key to the proposed scheme is to describe the data correlation and select features which leads to less data correlation across the whole dataset. The proposed scheme involves five steps with the goal of managing the extent of data correlation, preserving the privacy, and supporting accuracy in the prediction results. In this way, the impact of data correlation is relieved with the proposed feature selection scheme, and moreover, the privacy issue of data correlation in learning is guaranteed. The proposed method can be widely used in machine learning algorithms which provide services in industrial areas. Experiments show that the proposed scheme can produce better prediction results with machine learning tasks and fewer mean square errors for data queries compared to existing schemes.
* This paper has been published in IEEE Transactions on Industrial Informatics
An exploration of algorithmic discrimination in data and classification
Nov 06, 2018
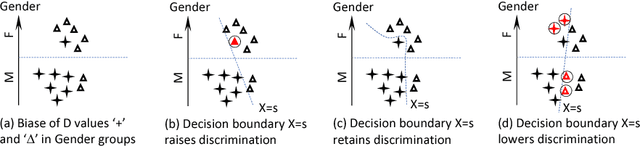

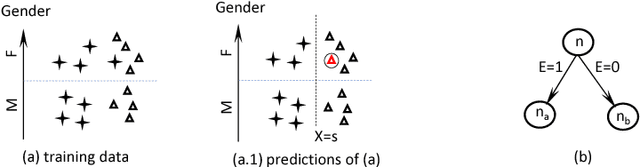
Algorithmic discrimination is an important aspect when data is used for predictive purposes. This paper analyzes the relationships between discrimination and classification, data set partitioning, and decision models, as well as correlation. The paper uses real world data sets to demonstrate the existence of discrimination and the independence between the discrimination of data sets and the discrimination of classification models.