 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning Black Box into White Box: Dataset Distillation Leaks
Mar 01, 2026Dataset distillation compresses a large real dataset into a small synthetic one, enabling models trained on the synthetic data to achieve performance comparable to those trained on the real data. Although synthetic datasets are assumed to be privacy-preserving, we show that existing distillation methods can cause severe privacy leakage because synthetic datasets implicitly encode the weight trajectories of the distilled model, they become over-informative and exploitable by adversaries. To expose this risk, we introduce the Information Revelation Attack (IRA) against state-of-the-art distillation techniques. Experiments show that IRA accurately predicts both the distillation algorithm and model architecture, and can successfully infer membership and recover sensitive samples from the real dataset.
Forgetting Similar Samples: Can Machine Unlearning Do it Better?
Jan 11, 2026Machine unlearning, a process enabling pre-trained models to remove the influence of specific training samples, has attracted significant attention in recent years. Although extensive research has focused on developing efficient machine unlearning strategies, we argue that these methods mainly aim at removing samples rather than removing samples' influence on the model, thus overlooking the fundamental definition of machine unlearning. In this paper, we first conduct a comprehensive study to evaluate the effectiveness of existing unlearning schemes when the training dataset includes many samples similar to those targeted for unlearning. Specifically, we evaluate: Do existing unlearning methods truly adhere to the original definition of machine unlearning and effectively eliminate all influence of target samples when similar samples are present in the training dataset? Our extensive experiments, conducted on four carefully constructed datasets with thorough analysis, reveal a notable gap between the expected and actual performance of most existing unlearning methods for image and language models, even for the retraining-from-scratch baseline. Additionally, we also explore potential solutions to enhance current unlearning approaches.
VIPER Strike: Defeating Visual Reasoning CAPTCHAs via Structured Vision-Language Inference
Jan 10, 2026Visual Reasoning CAPTCHAs (VRCs) combine visual scenes with natural-language queries that demand compositional inference over objects, attributes, and spatial relations. They are increasingly deployed as a primary defense against automated bots. Existing solvers fall into two paradigms: vision-centric, which rely on template-specific detectors but fail on novel layouts, and reasoning-centric, which leverage LLMs but struggle with fine-grained visual perception. Both lack the generality needed to handle heterogeneous VRC deployments. We present ViPer, a unified attack framework that integrates structured multi-object visual perception with adaptive LLM-based reasoning. ViPer parses visual layouts, grounds attributes to question semantics, and infers target coordinates within a modular pipeline. Evaluated on six major VRC providers (VTT, Geetest, NetEase, Dingxiang, Shumei, Xiaodun), ViPer achieves up to 93.2% success, approaching human-level performance across multiple benchmarks. Compared to prior solvers, GraphNet (83.2%), Oedipus (65.8%), and the Holistic approach (89.5%), ViPer consistently outperforms all baselines. The framework further maintains robustness across alternative LLM backbones (GPT, Grok, DeepSeek, Kimi), sustaining accuracy above 90%. To anticipate defense, we further introduce Template-Space Randomization (TSR), a lightweight strategy that perturbs linguistic templates without altering task semantics. TSR measurably reduces solver (i.e., attacker) performance. Our proposed design suggests directions for human-solvable but machine-resistant CAPTCHAs.
Vertical Federated Unlearning via Backdoor Certification
Dec 16, 2024Vertical Federated Learning (VFL) offers a novel paradigm in machine learning, enabling distinct entities to train models cooperatively while maintaining data privacy. This method is particularly pertinent when entities possess datasets with identical sample identifiers but diverse attributes. Recent privacy regulations emphasize an individual's \emph{right to be forgotten}, which necessitates the ability for models to unlearn specific training data. The primary challenge is to develop a mechanism to eliminate the influence of a specific client from a model without erasing all relevant data from other clients. Our research investigates the removal of a single client's contribution within the VFL framework. We introduce an innovative modification to traditional VFL by employing a mechanism that inverts the typical learning trajectory with the objective of extracting specific data contributions. This approach seeks to optimize model performance using gradient ascent, guided by a pre-defined constrained model. We also introduce a backdoor mechanism to verify the effectiveness of the unlearning procedure. Our method avoids fully accessing the initial training data and avoids storing parameter updates. Empirical evidence shows that the results align closely with those achieved by retraining from scratch. Utilizing gradient ascent, our unlearning approach addresses key challenges in VFL, laying the groundwork for future advancements in this domain. All the code and implementations related to this paper are publicly available at https://github.com/mengde-han/VFL-unlearn.
Game-Theoretic Machine Unlearning: Mitigating Extra Privacy Leakage
Nov 06, 2024With the extensive use of machine learning technologies, data providers encounter increasing privacy risks. Recent legislation, such as GDPR, obligates organizations to remove requested data and its influence from a trained model. Machine unlearning is an emerging technique designed to enable machine learning models to erase users' private information. Although several efficient machine unlearning schemes have been proposed, these methods still have limitations. First, removing the contributions of partial data may lead to model performance degradation. Second, discrepancies between the original and generated unlearned models can be exploited by attackers to obtain target sample's information, resulting in additional privacy leakage risks. To address above challenges, we proposed a game-theoretic machine unlearning algorithm that simulates the competitive relationship between unlearning performance and privacy protection. This algorithm comprises unlearning and privacy modules. The unlearning module possesses a loss function composed of model distance and classification error, which is used to derive the optimal strategy. The privacy module aims to make it difficult for an attacker to infer membership information from the unlearned data, thereby reducing the privacy leakage risk during the unlearning process. Additionally, the experimental results on real-world datasets demonstrate that this game-theoretic unlearning algorithm's effectiveness and its ability to generate an unlearned model with a performance similar to that of the retrained one while mitigating extra privacy leakage risks.
QUEEN: Query Unlearning against Model Extraction
Jul 01, 2024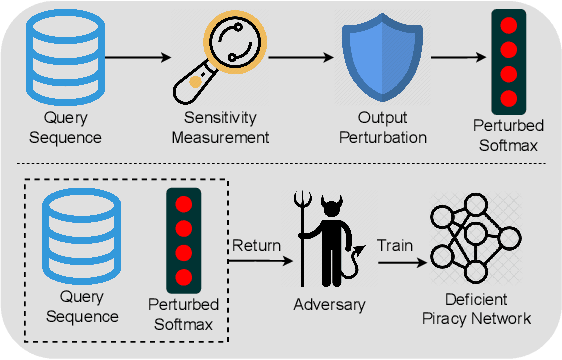
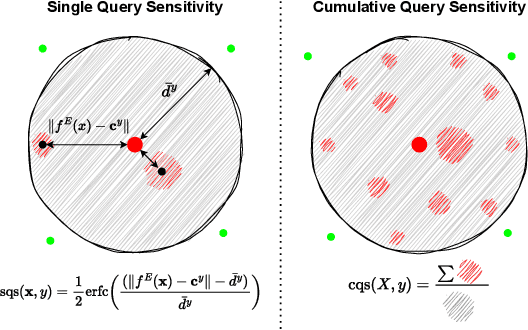
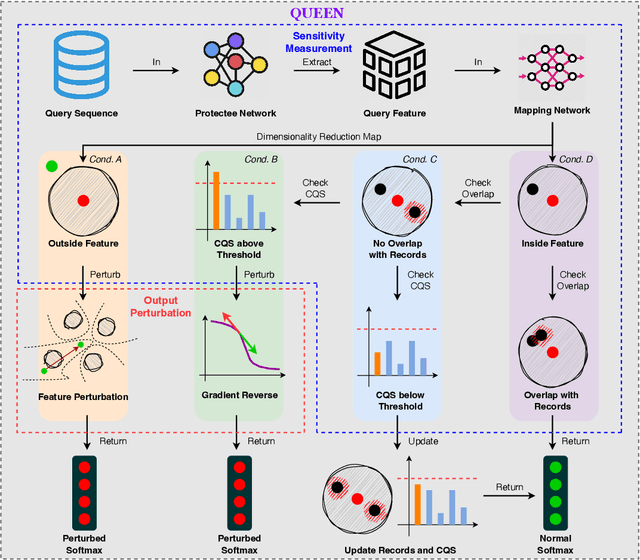

Model extraction attacks currently pose a non-negligible threat to the security and privacy of deep learning models. By querying the model with a small dataset and usingthe query results as the ground-truth labels, an adversary can steal a piracy model with performance comparable to the original model. Two key issues that cause the threat are, on the one hand, accurate and unlimited queries can be obtained by the adversary; on the other hand, the adversary can aggregate the query results to train the model step by step. The existing defenses usually employ model watermarking or fingerprinting to protect the ownership. However, these methods cannot proactively prevent the violation from happening. To mitigate the threat, we propose QUEEN (QUEry unlEarNing) that proactively launches counterattacks on potential model extraction attacks from the very beginning. To limit the potential threat, QUEEN has sensitivity measurement and outputs perturbation that prevents the adversary from training a piracy model with high performance. In sensitivity measurement, QUEEN measures the single query sensitivity by its distance from the center of its cluster in the feature space. To reduce the learning accuracy of attacks, for the highly sensitive query batch, QUEEN applies query unlearning, which is implemented by gradient reverse to perturb the softmax output such that the piracy model will generate reverse gradients to worsen its performance unconsciously. Experiments show that QUEEN outperforms the state-of-the-art defenses against various model extraction attacks with a relatively low cost to the model accuracy. The artifact is publicly available at https://anonymous.4open.science/r/queen implementation-5408/.
Update Selective Parameters: Federated Machine Unlearning Based on Model Explanation
Jun 18, 2024



Federated learning is a promising privacy-preserving paradigm for distributed machine learning. In this context, there is sometimes a need for a specialized process called machine unlearning, which is required when the effect of some specific training samples needs to be removed from a learning model due to privacy, security, usability, and/or legislative factors. However, problems arise when current centralized unlearning methods are applied to existing federated learning, in which the server aims to remove all information about a class from the global model. Centralized unlearning usually focuses on simple models or is premised on the ability to access all training data at a central node. However, training data cannot be accessed on the server under the federated learning paradigm, conflicting with the requirements of the centralized unlearning process. Additionally, there are high computation and communication costs associated with accessing clients' data, especially in scenarios involving numerous clients or complex global models. To address these concerns, we propose a more effective and efficient federated unlearning scheme based on the concept of model explanation. Model explanation involves understanding deep networks and individual channel importance, so that this understanding can be used to determine which model channels are critical for classes that need to be unlearned. We select the most influential channels within an already-trained model for the data that need to be unlearned and fine-tune only influential channels to remove the contribution made by those data. In this way, we can simultaneously avoid huge consumption costs and ensure that the unlearned model maintains good performance. Experiments with different training models on various datasets demonstrate the effectiveness of the proposed approach.
Towards Efficient Target-Level Machine Unlearning Based on Essential Graph
Jun 16, 2024



Machine unlearning is an emerging technology that has come to attract widespread attention. A number of factors, including regulations and laws, privacy, and usability concerns, have resulted in this need to allow a trained model to forget some of its training data. Existing studies of machine unlearning mainly focus on unlearning requests that forget a cluster of instances or all instances from one class. While these approaches are effective in removing instances, they do not scale to scenarios where partial targets within an instance need to be forgotten. For example, one would like to only unlearn a person from all instances that simultaneously contain the person and other targets. Directly migrating instance-level unlearning to target-level unlearning will reduce the performance of the model after the unlearning process, or fail to erase information completely. To address these concerns, we have proposed a more effective and efficient unlearning scheme that focuses on removing partial targets from the model, which we name "target unlearning". Specifically, we first construct an essential graph data structure to describe the relationships between all important parameters that are selected based on the model explanation method. After that, we simultaneously filter parameters that are also important for the remaining targets and use the pruning-based unlearning method, which is a simple but effective solution to remove information about the target that needs to be forgotten. Experiments with different training models on various datasets demonstrate the effectiveness of the proposed approach.
Federated Learning with Blockchain-Enhanced Machine Unlearning: A Trustworthy Approach
May 27, 2024



With the growing need to comply with privacy regulations and respond to user data deletion requests, integrating machine unlearning into IoT-based federated learning has become imperative. Traditional unlearning methods, however, often lack verifiable mechanisms, leading to challenges in establishing trust. This paper delves into the innovative integration of blockchain technology with federated learning to surmount these obstacles. Blockchain fortifies the unlearning process through its inherent qualities of immutability, transparency, and robust security. It facilitates verifiable certification, harmonizes security with privacy, and sustains system efficiency. We introduce a framework that melds blockchain with federated learning, thereby ensuring an immutable record of unlearning requests and actions. This strategy not only bolsters the trustworthiness and integrity of the federated learning model but also adeptly addresses efficiency and security challenges typical in IoT environments. Our key contributions encompass a certification mechanism for the unlearning process, the enhancement of data security and privacy, and the optimization of data management to ensure system responsiveness in IoT scenarios.
Machine Unlearning: A Survey
Jun 06, 2023



Machine learning has attracted widespread attention and evolved into an enabling technology for a wide range of highly successful applications, such as intelligent computer vision, speech recognition, medical diagnosis, and more. Yet a special need has arisen where, due to privacy, usability, and/or the right to be forgotten, information about some specific samples needs to be removed from a model, called machine unlearning. This emerging technology has drawn significant interest from both academics and industry due to its innovation and practicality. At the same time, this ambitious problem has led to numerous research efforts aimed at confronting its challenges. To the best of our knowledge, no study has analyzed this complex topic or compared the feasibility of existing unlearning solutions in different kinds of scenarios. Accordingly, with this survey, we aim to capture the key concepts of unlearning techniques. The existing solutions are classified and summarized based on their characteristics within an up-to-date and comprehensive review of each category's advantages and limitations. The survey concludes by highlighting some of the outstanding issues with unlearning techniques, along with some feasible directions for new research opportunities.