 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINO-Detect: A Simple yet Effective Framework for Blur-Robust AI-Generated Image Detection
Nov 18, 2025With growing concerns over image authenticity and digital safety, the field of AI-generated image (AIGI) detection has progressed rapidly. Yet, most AIGI detectors still struggle under real-world degradations, particularly motion blur, which frequently occurs in handheld photography, fast motion, and compressed video. Such blur distorts fine textures and suppresses high-frequency artifacts, causing severe performance drops in real-world settings. We address this limitation with a blur-robust AIGI detection framework based on teacher-student knowledge distillation. A high-capacity teacher (DINOv3), trained on clean (i.e., sharp) images, provides stable and semantically rich representations that serve as a reference for learning. By freezing the teacher to maintain its generalization ability, we distill its feature and logit responses from sharp images to a student trained on blurred counterparts, enabling the student to produce consistent representations under motion degradation. Extensive experiments benchmarks show that our method achieves state-of-the-art performance under both motion-blurred and clean conditions, demonstrating improved generalization and real-world applicability. Source codes will be released at: https://github.com/JiaLiangShen/Dino-Detect-for-blur-robust-AIGC-Detection.
QUEEN: Query Unlearning against Model Extraction
Jul 01, 2024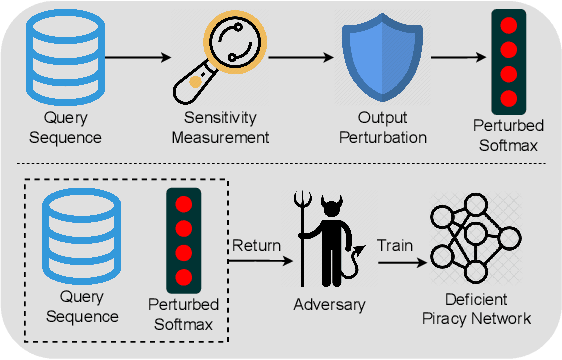
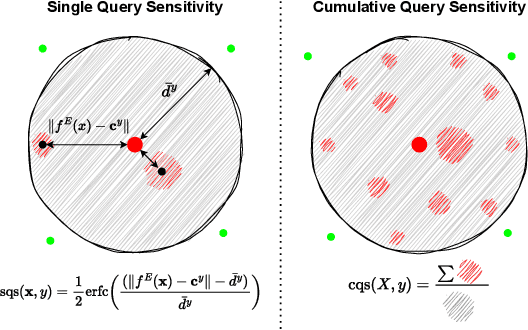
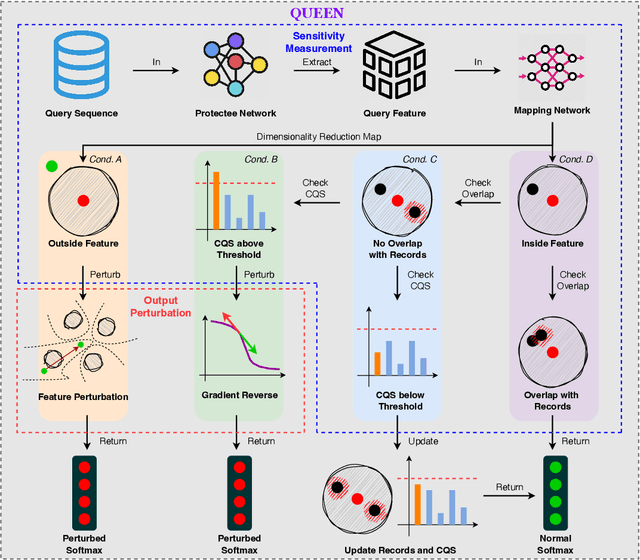

Model extraction attacks currently pose a non-negligible threat to the security and privacy of deep learning models. By querying the model with a small dataset and usingthe query results as the ground-truth labels, an adversary can steal a piracy model with performance comparable to the original model. Two key issues that cause the threat are, on the one hand, accurate and unlimited queries can be obtained by the adversary; on the other hand, the adversary can aggregate the query results to train the model step by step. The existing defenses usually employ model watermarking or fingerprinting to protect the ownership. However, these methods cannot proactively prevent the violation from happening. To mitigate the threat, we propose QUEEN (QUEry unlEarNing) that proactively launches counterattacks on potential model extraction attacks from the very beginning. To limit the potential threat, QUEEN has sensitivity measurement and outputs perturbation that prevents the adversary from training a piracy model with high performance. In sensitivity measurement, QUEEN measures the single query sensitivity by its distance from the center of its cluster in the feature space. To reduce the learning accuracy of attacks, for the highly sensitive query batch, QUEEN applies query unlearning, which is implemented by gradient reverse to perturb the softmax output such that the piracy model will generate reverse gradients to worsen its performance unconsciously. Experiments show that QUEEN outperforms the state-of-the-art defenses against various model extraction attacks with a relatively low cost to the model accuracy. The artifact is publicly available at https://anonymous.4open.science/r/queen implementation-5408/.
Equivariant Matrix Function Neural Networks
Oct 16, 2023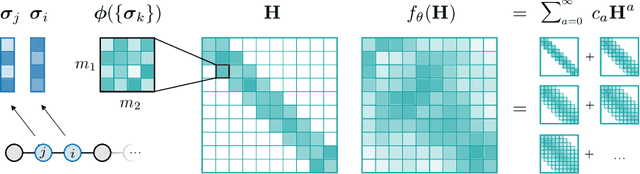

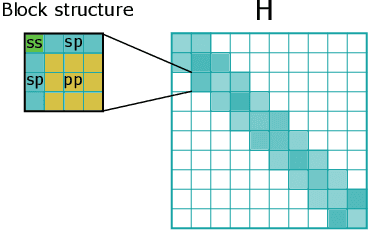

Graph Neural Networks (GNNs), especially message-passing neural networks (MPNNs), have emerged as powerful architectures for learning on graphs in diverse applications. However, MPNNs face challenges when modeling non-local interactions in systems such as large conjugated molecules, metals, or amorphous materials. Although Spectral GNNs and traditional neural networks such as recurrent neural networks and transformers mitigate these challenges, they often lack extensivity, adaptability, generalizability, computational efficiency, or fail to capture detailed structural relationships or symmetries in the data. To address these concerns, we introduce Matrix Function Neural Networks (MFNs), a novel architecture that parameterizes non-local interactions through analytic matrix equivariant functions. Employing resolvent expansions offers a straightforward implementation and the potential for linear scaling with system size. The MFN architecture achieves state-of-the-art performance in standard graph benchmarks, such as the ZINC and TU datasets, and is able to capture intricate non-local interactions in quantum systems, paving the way to new state-of-the-art force fields.
Low-frequency Image Deep Steganography: Manipulate the Frequency Distribution to Hide Secrets with Tenacious Robustness
Mar 23, 2023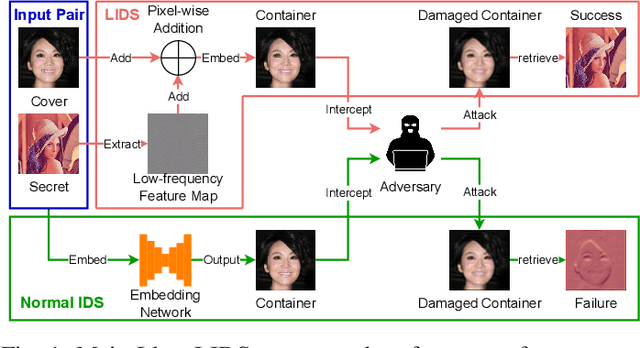


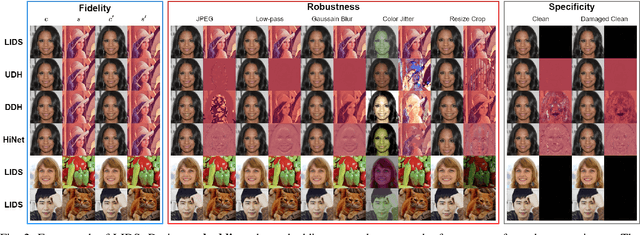
Image deep steganography (IDS) is a technique that utilizes deep learning to embed a secret image invisibly into a cover image to generate a container image. However, the container images generated by convolutional neural networks (CNNs) are vulnerable to attacks that distort their high-frequency components. To address this problem, we propose a novel method called Low-frequency Image Deep Steganography (LIDS) that allows frequency distribution manipulation in the embedding process. LIDS extracts a feature map from the secret image and adds it to the cover image to yield the container image. The container image is not directly output by the CNNs, and thus, it does not contain high-frequency artifacts. The extracted feature map is regulated by a frequency loss to ensure that its frequency distribution mainly concentrates on the low-frequency domain. To further enhance robustness, an attack layer is inserted to damage the container image. The retrieval network then retrieves a recovered secret image from a damaged container image. Our experiments demonstrate that LIDS outperforms state-of-the-art methods in terms of robustness, while maintaining high fidelity and specificity. By avoiding high-frequency artifacts and manipulating the frequency distribution of the embedded feature map, LIDS achieves improved robustness against attacks that distort the high-frequency components of container images.
Provable Convergence of Variational Monte Carlo Methods
Mar 19, 2023
The Variational Monte Carlo (VMC) is a promising approach for computing the ground state energy of many-body quantum problems and attracts more and more interests due to the development of machine learning. The recent paradigms in VMC construct neural networks as trial wave functions, sample quantum configurations using Markov chain Monte Carlo (MCMC) and train neural networks with stochastic gradient descent (SGD) method. However, the theoretical convergence of VMC is still unknown when SGD interacts with MCMC sampling given a well-designed trial wave function. Since MCMC reduces the difficulty of estimating gradients, it has inevitable bias in practice. Moreover, the local energy may be unbounded, which makes it harder to analyze the error of MCMC sampling. Therefore, we assume that the local energy is sub-exponential and use the Bernstein inequality for non-stationary Markov chains to derive error bounds of the MCMC estimator. Consequently, VMC is proven to have a first order convergence rate $O(\log K/\sqrt{n K})$ with $K$ iterations and a sample size $n$. It partially explains how MCMC influences the behavior of SGD. Furthermore, we verify the so-called correlated negative curvature condition and relate it to the zero-variance phenomena in solving eigenvalue functions. It is shown that VMC escapes from saddle points and reaches $(\epsilon,\epsilon^{1/4})$ -approximate second order stationary points or $\epsilon^{1/2}$-variance points in at least $O(\epsilon^{-11/2}\log^{2}(1/\epsilon) )$ steps with high probability. Our analysis enriches the understanding of how VMC converges efficiently and can be applied to general variational methods in physics and statistics.
Making DeepFakes more spurious: evading deep face forgery detection via trace removal attack
Mar 22, 2022

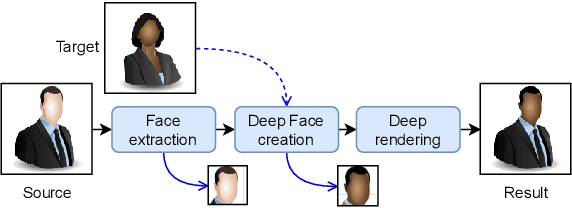

DeepFakes are raising significant social concerns. Although various DeepFake detectors have been developed as forensic countermeasures, these detectors are still vulnerable to attacks. Recently, a few attacks, principally adversarial attacks, have succeeded in cloaking DeepFake images to evade detection. However, these attacks have typical detector-specific designs, which require prior knowledge about the detector, leading to poor transferability. Moreover, these attacks only consider simple security scenarios. Less is known about how effective they are in high-level scenarios where either the detectors or the attacker's knowledge varies. In this paper, we solve the above challenges with presenting a novel detector-agnostic trace removal attack for DeepFake anti-forensics. Instead of investigating the detector side, our attack looks into the original DeepFake creation pipeline, attempting to remove all detectable natural DeepFake traces to render the fake images more "authentic". To implement this attack, first, we perform a DeepFake trace discovery, identifying three discernible traces. Then a trace removal network (TR-Net) is proposed based on an adversarial learning framework involving one generator and multiple discriminators. Each discriminator is responsible for one individual trace representation to avoid cross-trace interference. These discriminators are arranged in parallel, which prompts the generator to remove various traces simultaneously. To evaluate the attack efficacy, we crafted heterogeneous security scenarios where the detectors were embedded with different levels of defense and the attackers' background knowledge of data varies. The experimental results show that the proposed attack can significantly compromise the detection accuracy of six state-of-the-art DeepFake detectors while causing only a negligible loss in visual quality to the original DeepFake samples.
A Multi-Task Incremental Learning Framework with Category Name Embedding for Aspect-Category Sentiment Analysis
Oct 06, 2020


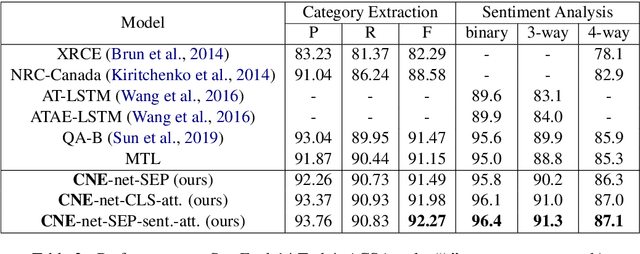
(T)ACSA tasks, including aspect-category sentiment analysis (ACSA) and targeted aspect-category sentiment analysis (TACSA), aims at identifying sentiment polarity on predefined categories. Incremental learning on new categories is necessary for (T)ACSA real applications. Though current multi-task learning models achieve good performance in (T)ACSA tasks, they suffer from catastrophic forgetting problems in (T)ACSA incremental learning tasks. In this paper, to make multi-task learning feasible for incremental learning, we proposed Category Name Embedding network (CNE-net). We set both encoder and decoder shared among all categories to weaken the catastrophic forgetting problem. Besides the origin input sentence, we applied another input feature, i.e., category name, for task discrimination. Our model achieved state-of-the-art on two (T)ACSA benchmark datasets. Furthermore, we proposed a dataset for (T)ACSA incremental learning and achieved the best performance compared with other strong baselines.
Charge-Based Prison Term Prediction with Deep Gating Network
Aug 30, 2019
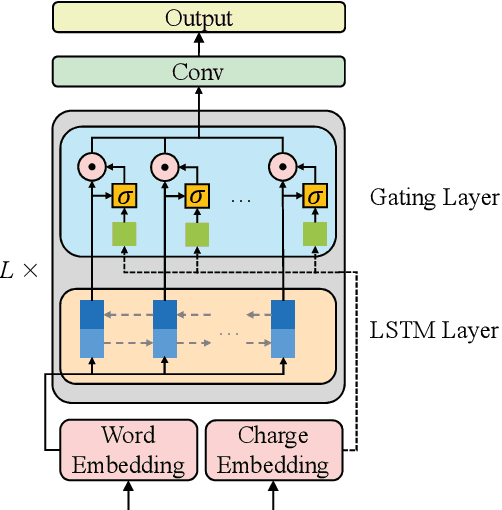
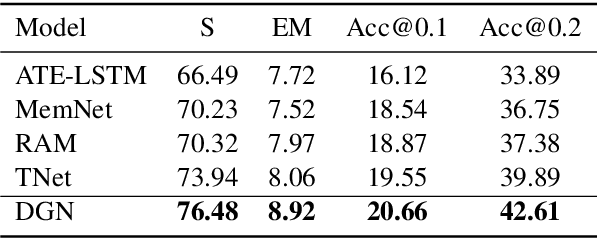
Judgment prediction for legal cases has attracted much research efforts for its practice use, of which the ultimate goal is prison term prediction. While existing work merely predicts the total prison term, in reality a defendant is often charged with multiple crimes. In this paper, we argue that charge-based prison term prediction (CPTP) not only better fits realistic needs, but also makes the total prison term prediction more accurate and interpretable. We collect the first large-scale structured data for CPTP and evaluate several competitive baselines. Based on the observation that fine-grained feature selection is the key to achieving good performance, we propose the Deep Gating Network (DGN) for charge-specific feature selection and aggregation. Experiments show that DGN achieves the state-of-the-art performance.