 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReaLM: Reflection-Enhanced Autonomous Reasoning with Small Language Models
Aug 17, 2025Small Language Models (SLMs) are a cost-effective alternative to Large Language Models (LLMs), but often struggle with complex reasoning due to their limited capacity and a tendency to produce mistakes or inconsistent answers during multi-step reasoning. Existing efforts have improved SLM performance, but typically at the cost of one or more of three key aspects: (1) reasoning capability, due to biased supervision that filters out negative reasoning paths and limits learning from errors; (2) autonomy, due to over-reliance on externally generated reasoning signals; and (3) generalization, which suffers when models overfit to teacher-specific patterns. In this paper, we introduce ReaLM, a reinforcement learning framework for robust and self-sufficient reasoning in vertical domains. To enhance reasoning capability, we propose Multi-Route Process Verification (MRPV), which contrasts both positive and negative reasoning paths to extract decisive patterns. To reduce reliance on external guidance and improve autonomy, we introduce Enabling Autonomy via Asymptotic Induction (EAAI), a training strategy that gradually fades external signals. To improve generalization, we apply guided chain-of-thought distillation to encode domain-specific rules and expert knowledge into SLM parameters, making them part of what the model has learned. Extensive experiments on both vertical and general reasoning tasks demonstrate that ReaLM significantly improves SLM performance across aspects (1)-(3) above.
Incentive Compatible Pareto Alignment for Multi-Source Large Graphs
Dec 06, 2021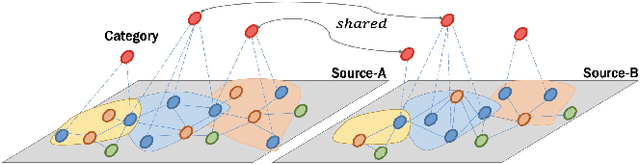
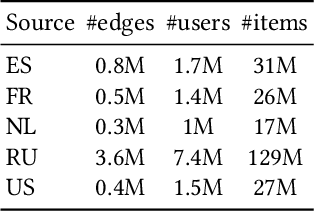
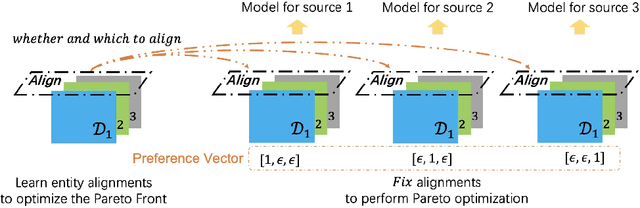
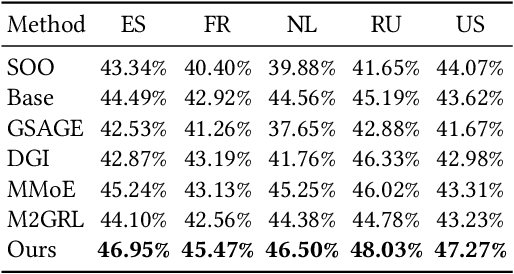
In this paper, we focus on learning effective entity matching models over multi-source large-scale data. For real applications, we relax typical assumptions that data distributions/spaces, or entity identities are shared between sources, and propose a Relaxed Multi-source Large-scale Entity-matching (RMLE) problem. Challenges of the problem include 1) how to align large-scale entities between sources to share information and 2) how to mitigate negative transfer from joint learning multi-source data. What's worse, one practical issue is the entanglement between both challenges. Specifically, incorrect alignments may increase negative transfer; while mitigating negative transfer for one source may result in poorly learned representations for other sources and then decrease alignment accuracy. To handle the entangled challenges, we point out that the key is to optimize information sharing first based on Pareto front optimization, by showing that information sharing significantly influences the Pareto front which depicts lower bounds of negative transfer. Consequently, we proposed an Incentive Compatible Pareto Alignment (ICPA) method to first optimize cross-source alignments based on Pareto front optimization, then mitigate negative transfer constrained on the optimized alignments. This mechanism renders each source can learn based on its true preference without worrying about deteriorating representations of other sources. Specifically, the Pareto front optimization encourages minimizing lower bounds of negative transfer, which optimizes whether and which to align. Comprehensive empirical evaluation results on four large-scale datasets are provided to demonstrate the effectiveness and superiority of ICPA. Online A/B test results at a search advertising platform also demonstrate the effectiveness of ICPA in production environments.
A Multi-Task Incremental Learning Framework with Category Name Embedding for Aspect-Category Sentiment Analysis
Oct 06, 2020


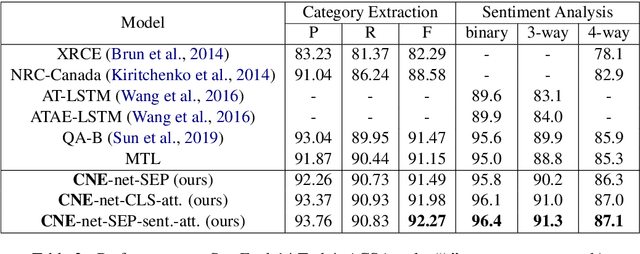
(T)ACSA tasks, including aspect-category sentiment analysis (ACSA) and targeted aspect-category sentiment analysis (TACSA), aims at identifying sentiment polarity on predefined categories. Incremental learning on new categories is necessary for (T)ACSA real applications. Though current multi-task learning models achieve good performance in (T)ACSA tasks, they suffer from catastrophic forgetting problems in (T)ACSA incremental learning tasks. In this paper, to make multi-task learning feasible for incremental learning, we proposed Category Name Embedding network (CNE-net). We set both encoder and decoder shared among all categories to weaken the catastrophic forgetting problem. Besides the origin input sentence, we applied another input feature, i.e., category name, for task discrimination. Our model achieved state-of-the-art on two (T)ACSA benchmark datasets. Furthermore, we proposed a dataset for (T)ACSA incremental learning and achieved the best performance compared with other strong baselines.
Charge-Based Prison Term Prediction with Deep Gating Network
Aug 30, 2019
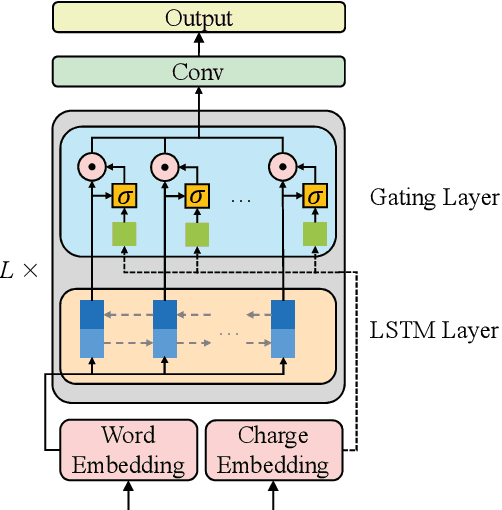
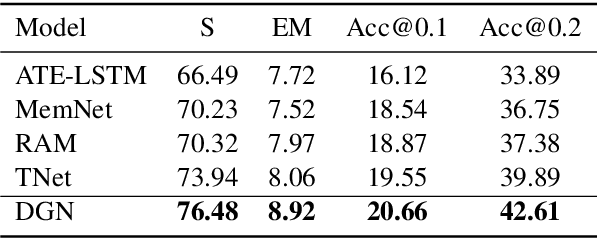
Judgment prediction for legal cases has attracted much research efforts for its practice use, of which the ultimate goal is prison term prediction. While existing work merely predicts the total prison term, in reality a defendant is often charged with multiple crimes. In this paper, we argue that charge-based prison term prediction (CPTP) not only better fits realistic needs, but also makes the total prison term prediction more accurate and interpretable. We collect the first large-scale structured data for CPTP and evaluate several competitive baselines. Based on the observation that fine-grained feature selection is the key to achieving good performance, we propose the Deep Gating Network (DGN) for charge-specific feature selection and aggregation. Experiments show that DGN achieves the state-of-the-art performance.