 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics Reasoner: Knowledge-Augmented Reasoning for Solving Physics Problems with Large Language Models
Dec 18, 2024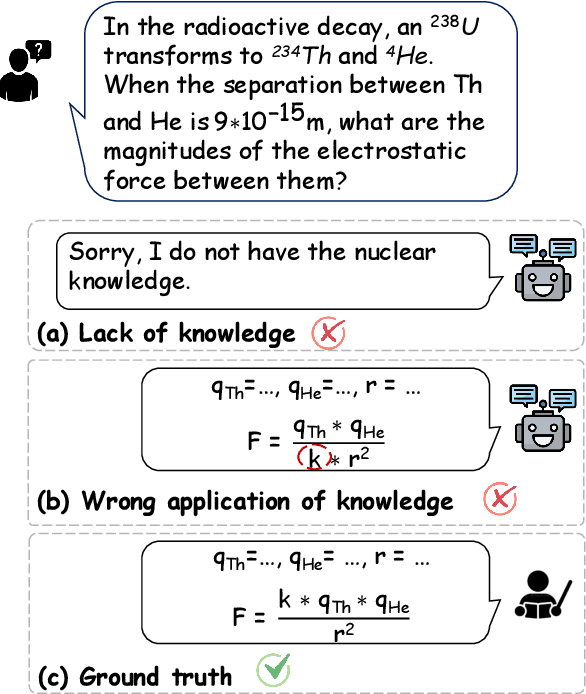
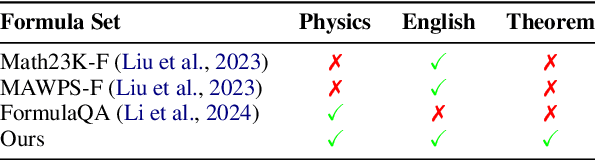
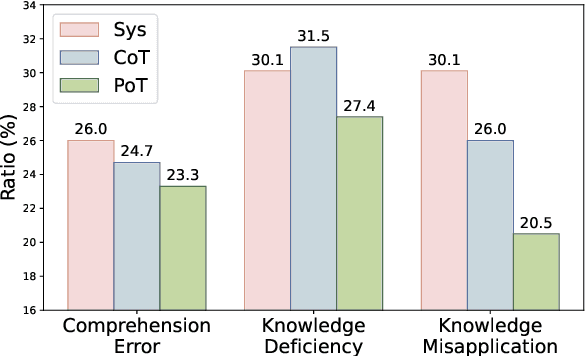

Physics problems constitute a significant aspect of reasoning, necessitating complicated reasoning ability and abundant physics knowledge. However, existing large language models (LLMs) frequently fail due to a lack of knowledge or incorrect knowledge application. To mitigate these issues, we propose Physics Reasoner, a knowledge-augmented framework to solve physics problems with LLMs. Specifically, the proposed framework constructs a comprehensive formula set to provide explicit physics knowledge and utilizes checklists containing detailed instructions to guide effective knowledge application. Namely, given a physics problem, Physics Reasoner solves it through three stages: problem analysis, formula retrieval, and guided reasoning. During the process, checklists are employed to enhance LLMs' self-improvement in the analysis and reasoning stages. Empirically, Physics Reasoner mitigates the issues of insufficient knowledge and incorrect application, achieving state-of-the-art performance on SciBench with an average accuracy improvement of 5.8%.
Towards Unified and Effective Domain Generalization
Oct 16, 2023


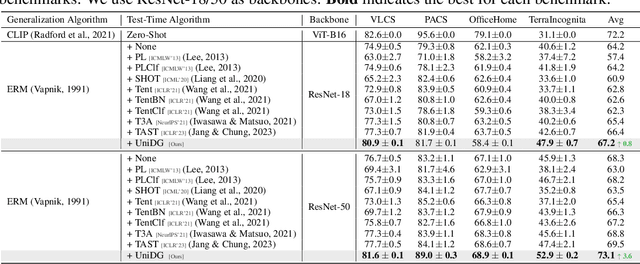
We propose $\textbf{UniDG}$, a novel and $\textbf{Uni}$fied framework for $\textbf{D}$omain $\textbf{G}$eneralization that is capable of significantly enhancing the out-of-distribution generalization performance of foundation models regardless of their architectures. The core idea of UniDG is to finetune models during the inference stage, which saves the cost of iterative training. Specifically, we encourage models to learn the distribution of test data in an unsupervised manner and impose a penalty regarding the updating step of model parameters. The penalty term can effectively reduce the catastrophic forgetting issue as we would like to maximally preserve the valuable knowledge in the original model. Empirically, across 12 visual backbones, including CNN-, MLP-, and Transformer-based models, ranging from 1.89M to 303M parameters, UniDG shows an average accuracy improvement of +5.4% on DomainBed. These performance results demonstrate the superiority and versatility of UniDG. The code is publicly available at https://github.com/invictus717/UniDG
Improving Generalization with Domain Convex Game
Mar 23, 2023Domain generalization (DG) tends to alleviate the poor generalization capability of deep neural networks by learning model with multiple source domains. A classical solution to DG is domain augmentation, the common belief of which is that diversifying source domains will be conducive to the out-of-distribution generalization. However, these claims are understood intuitively, rather than mathematically. Our explorations empirically reveal that the correlation between model generalization and the diversity of domains may be not strictly positive, which limits the effectiveness of domain augmentation. This work therefore aim to guarantee and further enhance the validity of this strand. To this end, we propose a new perspective on DG that recasts it as a convex game between domains. We first encourage each diversified domain to enhance model generalization by elaborately designing a regularization term based on supermodularity. Meanwhile, a sample filter is constructed to eliminate low-quality samples, thereby avoiding the impact of potentially harmful information. Our framework presents a new avenue for the formal analysis of DG, heuristic analysis and extensive experiments demonstrate the rationality and effectiveness.
Causality Inspired Representation Learning for Domain Generalization
Mar 27, 2022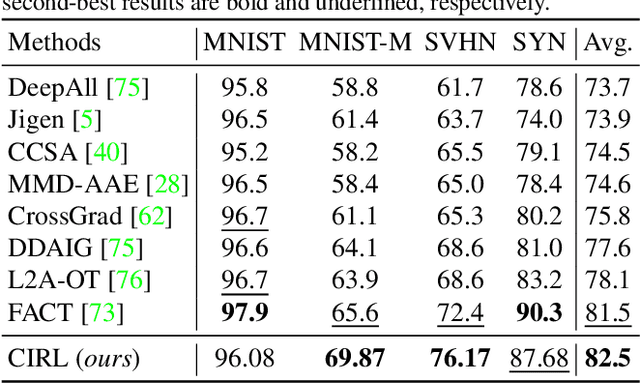
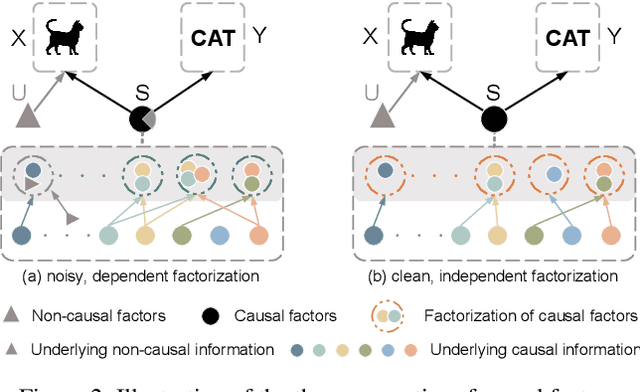
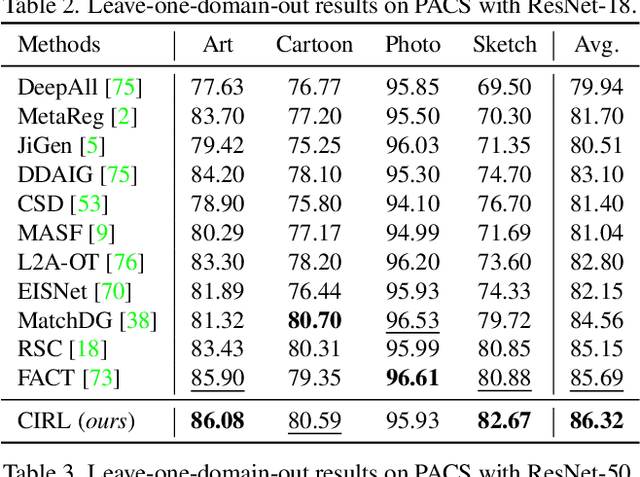
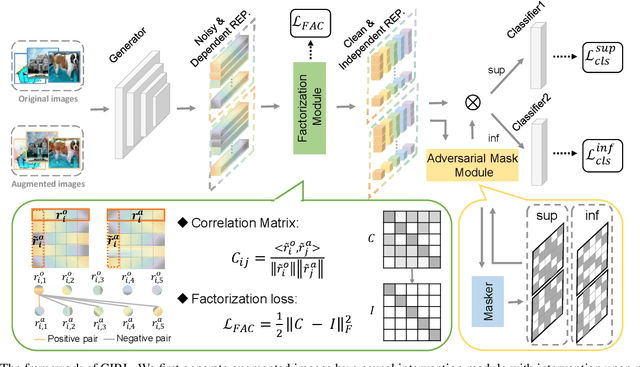
Domain generalization (DG) is essentially an out-of-distribution problem, aiming to generalize the knowledge learned from multiple source domains to an unseen target domain. The mainstream is to leverage statistical models to model the dependence between data and labels, intending to learn representations independent of domain. Nevertheless, the statistical models are superficial descriptions of reality since they are only required to model dependence instead of the intrinsic causal mechanism. When the dependence changes with the target distribution, the statistic models may fail to generalize. In this regard, we introduce a general structural causal model to formalize the DG problem. Specifically, we assume that each input is constructed from a mix of causal factors (whose relationship with the label is invariant across domains) and non-causal factors (category-independent), and only the former cause the classification judgments. Our goal is to extract the causal factors from inputs and then reconstruct the invariant causal mechanisms. However, the theoretical idea is far from practical of DG since the required causal/non-causal factors are unobserved. We highlight that ideal causal factors should meet three basic properties: separated from the non-causal ones, jointly independent, and causally sufficient for the classification. Based on that, we propose a Causality Inspired Representation Learning (CIRL) algorithm that enforces the representations to satisfy the above properties and then uses them to simulate the causal factors, which yields improved generalization ability. Extensive experimental results on several widely used datasets verify the effectiveness of our approach.
Pareto Domain Adaptation
Dec 09, 2021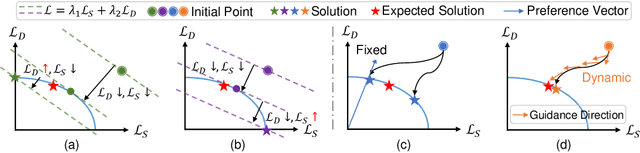
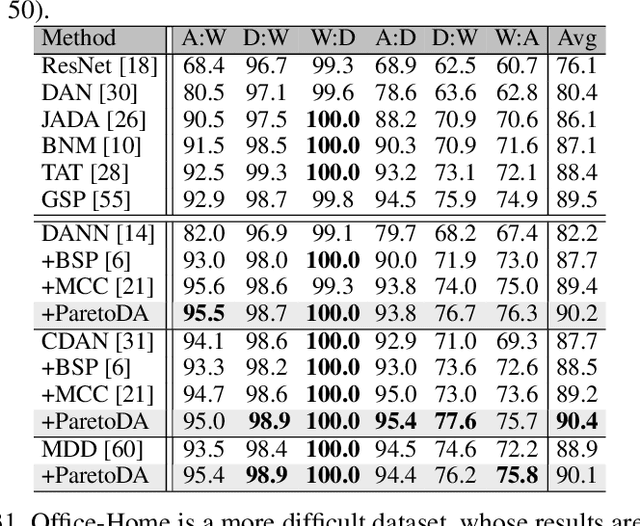
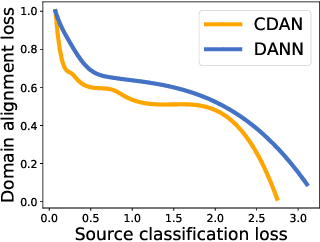
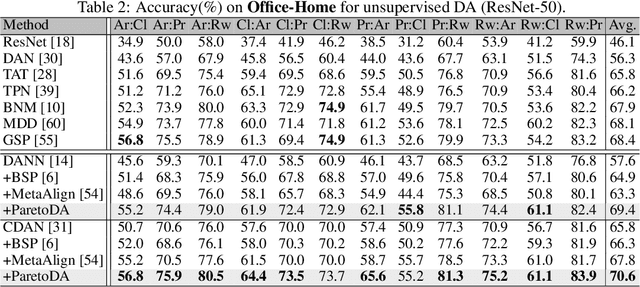
Domain adaptation (DA) attempts to transfer the knowledge from a labeled source domain to an unlabeled target domain that follows different distribution from the source. To achieve this, DA methods include a source classification objective to extract the source knowledge and a domain alignment objective to diminish the domain shift, ensuring knowledge transfer. Typically, former DA methods adopt some weight hyper-parameters to linearly combine the training objectives to form an overall objective. However, the gradient directions of these objectives may conflict with each other due to domain shift. Under such circumstances, the linear optimization scheme might decrease the overall objective value at the expense of damaging one of the training objectives, leading to restricted solutions. In this paper, we rethink the optimization scheme for DA from a gradient-based perspective. We propose a Pareto Domain Adaptation (ParetoDA) approach to control the overall optimization direction, aiming to cooperatively optimize all training objectives. Specifically, to reach a desirable solution on the target domain, we design a surrogate loss mimicking target classification. To improve target-prediction accuracy to support the mimicking, we propose a target-prediction refining mechanism which exploits domain labels via Bayes' theorem. On the other hand, since prior knowledge of weighting schemes for objectives is often unavailable to guide optimization to approach the optimal solution on the target domain, we propose a dynamic preference mechanism to dynamically guide our cooperative optimization by the gradient of the surrogate loss on a held-out unlabeled target dataset. Extensive experiments on image classification and semantic segmentation benchmarks demonstrate the effectiveness of ParetoDA
Incentive Compatible Pareto Alignment for Multi-Source Large Graphs
Dec 06, 2021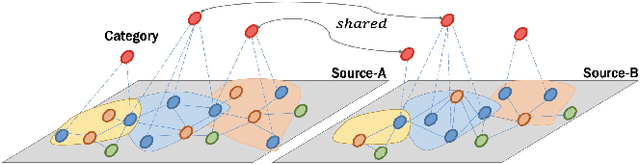
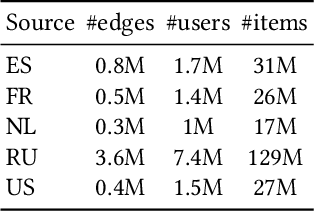
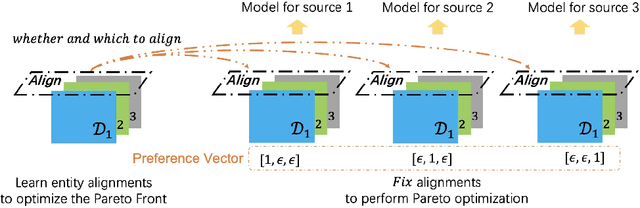
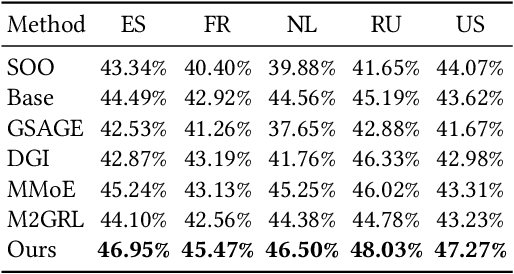
In this paper, we focus on learning effective entity matching models over multi-source large-scale data. For real applications, we relax typical assumptions that data distributions/spaces, or entity identities are shared between sources, and propose a Relaxed Multi-source Large-scale Entity-matching (RMLE) problem. Challenges of the problem include 1) how to align large-scale entities between sources to share information and 2) how to mitigate negative transfer from joint learning multi-source data. What's worse, one practical issue is the entanglement between both challenges. Specifically, incorrect alignments may increase negative transfer; while mitigating negative transfer for one source may result in poorly learned representations for other sources and then decrease alignment accuracy. To handle the entangled challenges, we point out that the key is to optimize information sharing first based on Pareto front optimization, by showing that information sharing significantly influences the Pareto front which depicts lower bounds of negative transfer. Consequently, we proposed an Incentive Compatible Pareto Alignment (ICPA) method to first optimize cross-source alignments based on Pareto front optimization, then mitigate negative transfer constrained on the optimized alignments. This mechanism renders each source can learn based on its true preference without worrying about deteriorating representations of other sources. Specifically, the Pareto front optimization encourages minimizing lower bounds of negative transfer, which optimizes whether and which to align. Comprehensive empirical evaluation results on four large-scale datasets are provided to demonstrate the effectiveness and superiority of ICPA. Online A/B test results at a search advertising platform also demonstrate the effectiveness of ICPA in production environments.
Semantic Concentration for Domain Adaptation
Aug 12, 2021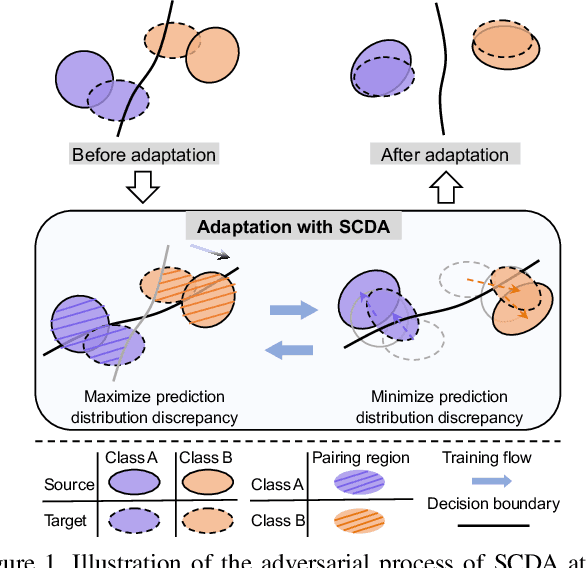
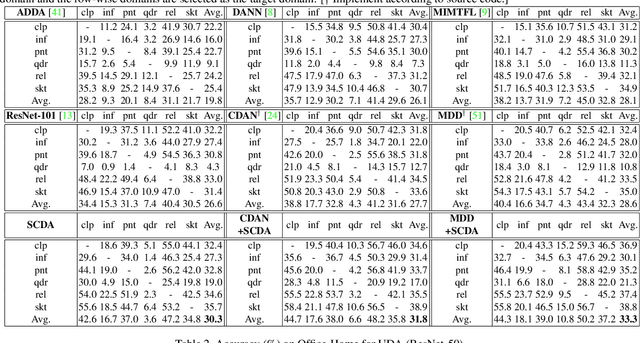


Domain adaptation (DA) paves the way for label annotation and dataset bias issues by the knowledge transfer from a label-rich source domain to a related but unlabeled target domain. A mainstream of DA methods is to align the feature distributions of the two domains. However, the majority of them focus on the entire image features where irrelevant semantic information, e.g., the messy background, is inevitably embedded. Enforcing feature alignments in such case will negatively influence the correct matching of objects and consequently lead to the semantically negative transfer due to the confusion of irrelevant semantics. To tackle this issue, we propose Semantic Concentration for Domain Adaptation (SCDA), which encourages the model to concentrate on the most principal features via the pair-wise adversarial alignment of prediction distributions. Specifically, we train the classifier to class-wisely maximize the prediction distribution divergence of each sample pair, which enables the model to find the region with large differences among the same class of samples. Meanwhile, the feature extractor attempts to minimize that discrepancy, which suppresses the features of dissimilar regions among the same class of samples and accentuates the features of principal parts. As a general method, SCDA can be easily integrated into various DA methods as a regularizer to further boost their performance. Extensive experiments on the cross-domain benchmarks show the efficacy of SCDA.
Bi-Classifier Determinacy Maximization for Unsupervised Domain Adaptation
Dec 13, 2020
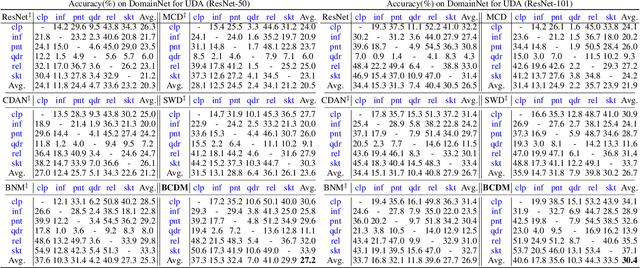


Unsupervised domain adaptation challenges the problem of transferring knowledge from a well-labelled source domain to an unlabelled target domain. Recently,adversarial learning with bi-classifier has been proven effective in pushing cross-domain distributions close. Prior approaches typically leverage the disagreement between bi-classifier to learn transferable representations, however, they often neglect the classifier determinacy in the target domain, which could result in a lack of feature discriminability. In this paper, we present a simple yet effective method, namely Bi-Classifier Determinacy Maximization(BCDM), to tackle this problem. Motivated by the observation that target samples cannot always be separated distinctly by the decision boundary, here in the proposed BCDM, we design a novel classifier determinacy disparity (CDD) metric, which formulates classifier discrepancy as the class relevance of distinct target predictions and implicitly introduces constraint on the target feature discriminability. To this end, the BCDM can generate discriminative representations by encouraging target predictive outputs to be consistent and determined, meanwhile, preserve the diversity of predictions in an adversarial manner. Furthermore, the properties of CDD as well as the theoretical guarantees of BCDM's generalization bound are both elaborated. Extensive experiments show that BCDM compares favorably against the existing state-of-the-art domain adaptation methods.