 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirichlet-based Uncertainty Calibration for Active Domain Adaptation
Feb 27, 2023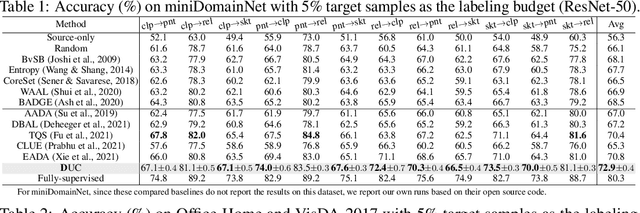
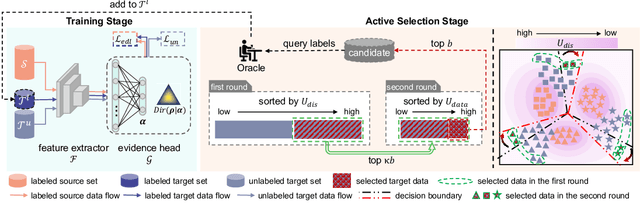
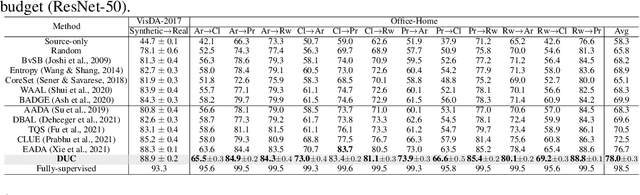
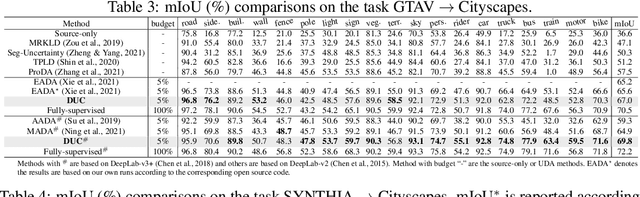
Active domain adaptation (DA) aims to maximally boost the model adaptation on a new target domain by actively selecting limited target data to annotate, whereas traditional active learning methods may be less effective since they do not consider the domain shift issue. Despite active DA methods address this by further proposing targetness to measure the representativeness of target domain characteristics, their predictive uncertainty is usually based on the prediction of deterministic models, which can easily be miscalibrated on data with distribution shift. Considering this, we propose a \textit{Dirichlet-based Uncertainty Calibration} (DUC) approach for active DA, which simultaneously achieves the mitigation of miscalibration and the selection of informative target samples. Specifically, we place a Dirichlet prior on the prediction and interpret the prediction as a distribution on the probability simplex, rather than a point estimate like deterministic models. This manner enables us to consider all possible predictions, mitigating the miscalibration of unilateral prediction. Then a two-round selection strategy based on different uncertainty origins is designed to select target samples that are both representative of target domain and conducive to discriminability. Extensive experiments on cross-domain image classification and semantic segmentation validate the superiority of DUC.
Domain Adaptation via Prompt Learning
Feb 14, 2022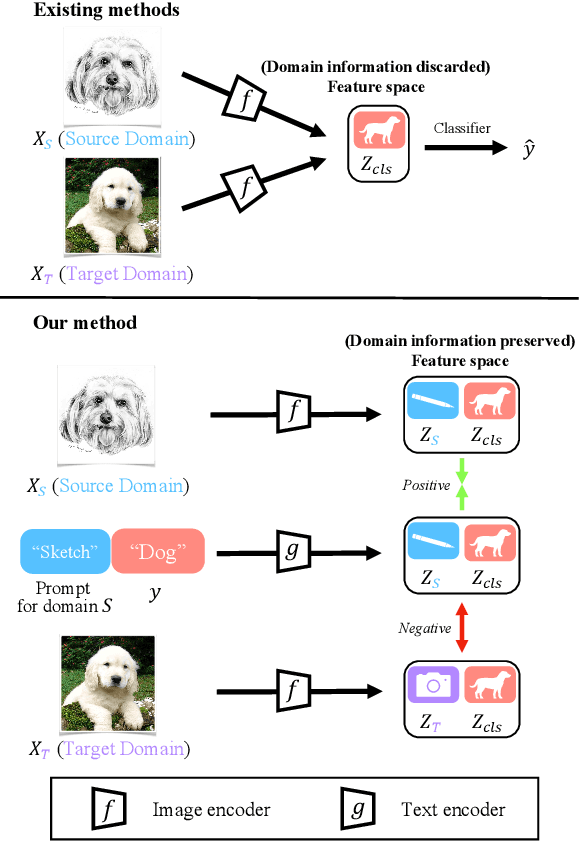

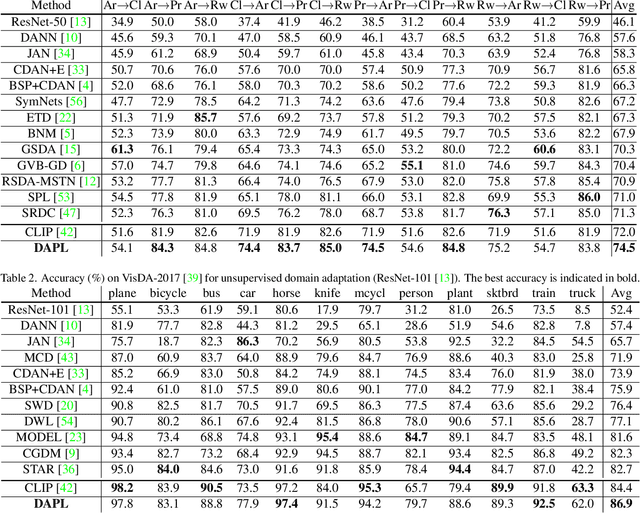
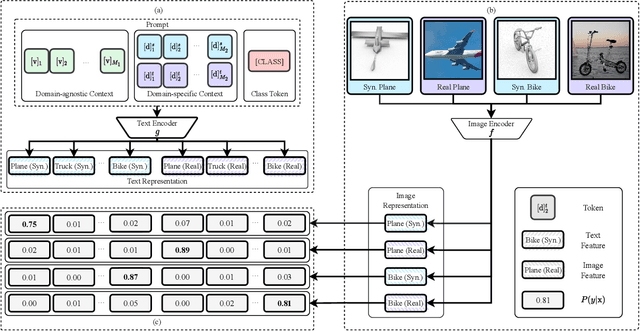
Unsupervised domain adaption (UDA) aims to adapt models learned from a well-annotated source domain to a target domain, where only unlabeled samples are given. Current UDA approaches learn domain-invariant features by aligning source and target feature spaces. Such alignments are imposed by constraints such as statistical discrepancy minimization or adversarial training. However, these constraints could lead to the distortion of semantic feature structures and loss of class discriminability. In this paper, we introduce a novel prompt learning paradigm for UDA, named Domain Adaptation via Prompt Learning (DAPL). In contrast to prior works, our approach makes use of pre-trained vision-language models and optimizes only very few parameters. The main idea is to embed domain information into prompts, a form of representations generated from natural language, which is then used to perform classification. This domain information is shared only by images from the same domain, thereby dynamically adapting the classifier according to each domain. By adopting this paradigm, we show that our model not only outperforms previous methods on several cross-domain benchmarks but also is very efficient to train and easy to implement.
Semantic Concentration for Domain Adaptation
Aug 12, 2021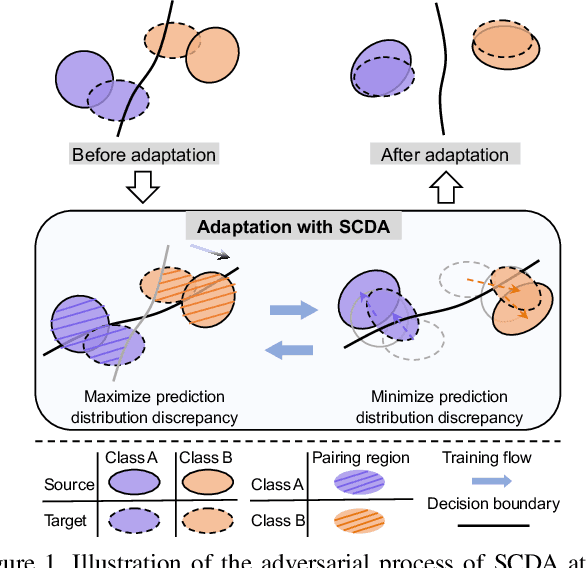
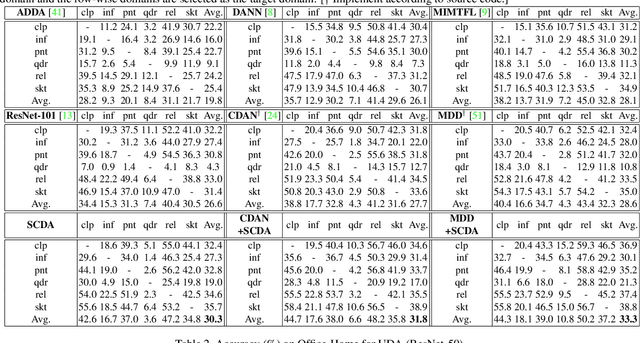


Domain adaptation (DA) paves the way for label annotation and dataset bias issues by the knowledge transfer from a label-rich source domain to a related but unlabeled target domain. A mainstream of DA methods is to align the feature distributions of the two domains. However, the majority of them focus on the entire image features where irrelevant semantic information, e.g., the messy background, is inevitably embedded. Enforcing feature alignments in such case will negatively influence the correct matching of objects and consequently lead to the semantically negative transfer due to the confusion of irrelevant semantics. To tackle this issue, we propose Semantic Concentration for Domain Adaptation (SCDA), which encourages the model to concentrate on the most principal features via the pair-wise adversarial alignment of prediction distributions. Specifically, we train the classifier to class-wisely maximize the prediction distribution divergence of each sample pair, which enables the model to find the region with large differences among the same class of samples. Meanwhile, the feature extractor attempts to minimize that discrepancy, which suppresses the features of dissimilar regions among the same class of samples and accentuates the features of principal parts. As a general method, SCDA can be easily integrated into various DA methods as a regularizer to further boost their performance. Extensive experiments on the cross-domain benchmarks show the efficacy of SCDA.
Transferable Semantic Augmentation for Domain Adaptation
Mar 23, 2021
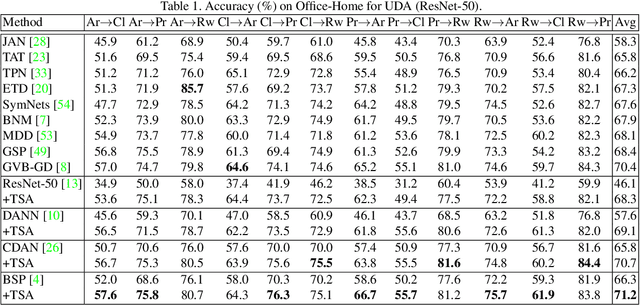


Domain adaptation has been widely explored by transferring the knowledge from a label-rich source domain to a related but unlabeled target domain. Most existing domain adaptation algorithms attend to adapting feature representations across two domains with the guidance of a shared source-supervised classifier. However, such classifier limits the generalization ability towards unlabeled target recognition. To remedy this, we propose a Transferable Semantic Augmentation (TSA) approach to enhance the classifier adaptation ability through implicitly generating source features towards target semantics. Specifically, TSA is inspired by the fact that deep feature transformation towards a certain direction can be represented as meaningful semantic altering in the original input space. Thus, source features can be augmented to effectively equip with target semantics to train a more transferable classifier. To achieve this, for each class, we first use the inter-domain feature mean difference and target intra-class feature covariance to construct a multivariate normal distribution. Then we augment source features with random directions sampled from the distribution class-wisely. Interestingly, such source augmentation is implicitly implemented through an expected transferable cross-entropy loss over the augmented source distribution, where an upper bound of the expected loss is derived and minimized, introducing negligible computational overhead. As a light-weight and general technique, TSA can be easily plugged into various domain adaptation methods, bringing remarkable improvements. Comprehensive experiments on cross-domain benchmarks validate the efficacy of TSA.