 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyn4D: A Multiview Synthetic 4D Dataset
May 06, 2026Dense 3D reconstruction and tracking of dynamic scenes from monocular video remains an important open challenge in computer vision. Progress in this area has been constrained by the scarcity of high-quality datasets with dense, complete, and accurate geometric annotations. To address this limitation, we introduce Syn4D, a multiview synthetic dataset of dynamic scenes that includes ground-truth camera motion, depth maps, dense tracking, and parametric human pose annotations. A key feature of Syn4D is the ability to unproject any pixel into 3D to any time and to any camera. We conduct extensive evaluations across multiple downstream tasks to demonstrate the utility and effectiveness of the proposed dataset, including 4D scene reconstruction, 3D point tracking, geometry-aware camera retargeting, and human pose estimation. The experimental results highlight Syn4D's potential to facilitate research in dynamic scene understanding and spatiotemporal modeling.
CoWTracker: Tracking by Warping instead of Correlation
Feb 04, 2026Dense point tracking is a fundamental problem in computer vision, with applications ranging from video analysis to robotic manipulation. State-of-the-art trackers typically rely on cost volumes to match features across frames, but this approach incurs quadratic complexity in spatial resolution, limiting scalability and efficiency. In this paper, we propose \method, a novel dense point tracker that eschews cost volumes in favor of warping. Inspired by recent advances in optical flow, our approach iteratively refines track estimates by warping features from the target frame to the query frame based on the current estimate. Combined with a transformer architecture that performs joint spatiotemporal reasoning across all tracks, our design establishes long-range correspondences without computing feature correlations. Our model is simple and achieves state-of-the-art performance on standard dense point tracking benchmarks, including TAP-Vid-DAVIS, TAP-Vid-Kinetics, and Robo-TAP. Remarkably, the model also excels at optical flow, sometimes outperforming specialized methods on the Sintel, KITTI, and Spring benchmarks. These results suggest that warping-based architectures can unify dense point tracking and optical flow estimation.
V-DPM: 4D Video Reconstruction with Dynamic Point Maps
Jan 14, 2026Powerful 3D representations such as DUSt3R invariant point maps, which encode 3D shape and camera parameters, have significantly advanced feed forward 3D reconstruction. While point maps assume static scenes, Dynamic Point Maps (DPMs) extend this concept to dynamic 3D content by additionally representing scene motion. However, existing DPMs are limited to image pairs and, like DUSt3R, require post processing via optimization when more than two views are involved. We argue that DPMs are more useful when applied to videos and introduce V-DPM to demonstrate this. First, we show how to formulate DPMs for video input in a way that maximizes representational power, facilitates neural prediction, and enables reuse of pretrained models. Second, we implement these ideas on top of VGGT, a recent and powerful 3D reconstructor. Although VGGT was trained on static scenes, we show that a modest amount of synthetic data is sufficient to adapt it into an effective V-DPM predictor. Our approach achieves state of the art performance in 3D and 4D reconstruction for dynamic scenes. In particular, unlike recent dynamic extensions of VGGT such as P3, DPMs recover not only dynamic depth but also the full 3D motion of every point in the scene.
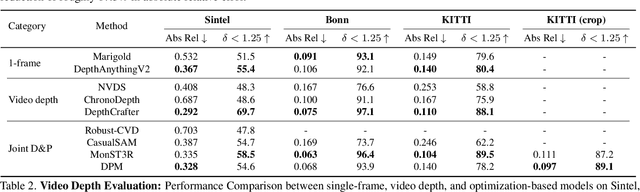
Tracktention: Leveraging Point Tracking to Attend Videos Faster and Better
Mar 25, 2025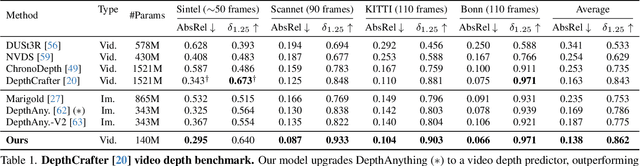
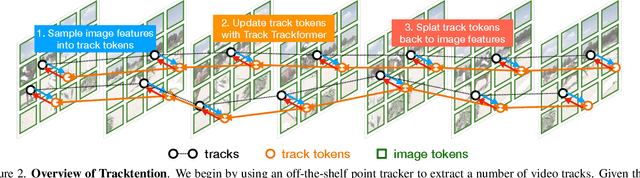

Temporal consistency is critical in video prediction to ensure that outputs are coherent and free of artifacts. Traditional methods, such as temporal attention and 3D convolution, may struggle with significant object motion and may not capture long-range temporal dependencies in dynamic scenes. To address this gap, we propose the Tracktention Layer, a novel architectural component that explicitly integrates motion information using point tracks, i.e., sequences of corresponding points across frames. By incorporating these motion cues, the Tracktention Layer enhances temporal alignment and effectively handles complex object motions, maintaining consistent feature representations over time. Our approach is computationally efficient and can be seamlessly integrated into existing models, such as Vision Transformers, with minimal modification. It can be used to upgrade image-only models to state-of-the-art video ones, sometimes outperforming models natively designed for video prediction. We demonstrate this on video depth prediction and video colorization, where models augmented with the Tracktention Layer exhibit significantly improved temporal consistency compared to baselines.
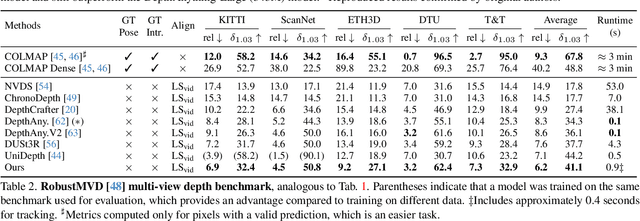
Dynamic Point Maps: A Versatile Representation for Dynamic 3D Reconstruction
Mar 20, 2025


DUSt3R has recently shown that one can reduce many tasks in multi-view geometry, including estimating camera intrinsics and extrinsics, reconstructing the scene in 3D, and establishing image correspondences, to the prediction of a pair of viewpoint-invariant point maps, i.e., pixel-aligned point clouds defined in a common reference frame. This formulation is elegant and powerful, but unable to tackle dynamic scenes. To address this challenge, we introduce the concept of Dynamic Point Maps (DPM), extending standard point maps to support 4D tasks such as motion segmentation, scene flow estimation, 3D object tracking, and 2D correspondence. Our key intuition is that, when time is introduced, there are several possible spatial and time references that can be used to define the point maps. We identify a minimal subset of such combinations that can be regressed by a network to solve the sub tasks mentioned above. We train a DPM predictor on a mixture of synthetic and real data and evaluate it across diverse benchmarks for video depth prediction, dynamic point cloud reconstruction, 3D scene flow and object pose tracking, achieving state-of-the-art performance. Code, models and additional results are available at https://www.robots.ox.ac.uk/~vgg/research/dynamic-point-maps/.
Exploring Simple Open-Vocabulary Semantic Segmentation
Jan 22, 2024Open-vocabulary semantic segmentation models aim to accurately assign a semantic label to each pixel in an image from a set of arbitrary open-vocabulary texts. In order to learn such pixel-level alignment, current approaches typically rely on a combination of (i) image-level VL model (e.g. CLIP), (ii) ground truth masks, and (iii) custom grouping encoders. In this paper, we introduce S-Seg, a novel model that can achieve surprisingly strong performance without depending on any of the above elements. S-Seg leverages pseudo-mask and language to train a MaskFormer, and can be easily trained from publicly available image-text datasets. Contrary to prior works, our model directly trains for pixel-level features and language alignment. Once trained, S-Seg generalizes well to multiple testing datasets without requiring fine-tuning. In addition, S-Seg has the extra benefits of scalability with data and consistently improvement when augmented with self-training. We believe that our simple yet effective approach will serve as a solid baseline for future research.
ActiveNeRF: Learning where to See with Uncertainty Estimation
Sep 18, 2022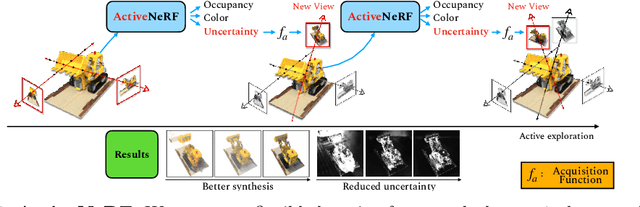
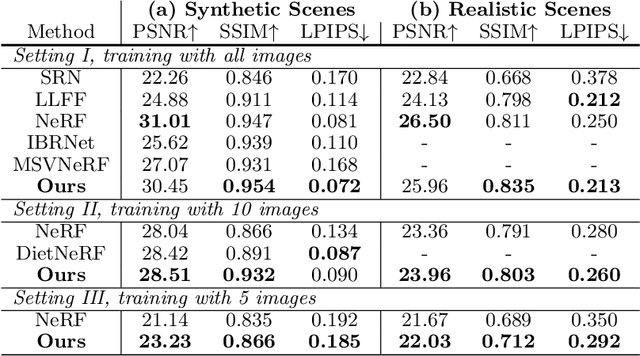

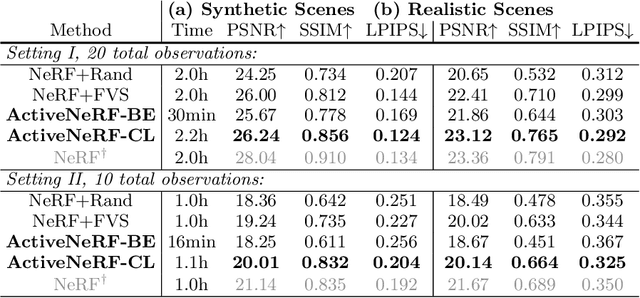
Recently, Neural Radiance Fields (NeRF) has shown promising performances on reconstructing 3D scenes and synthesizing novel views from a sparse set of 2D images. Albeit effective, the performance of NeRF is highly influenced by the quality of training samples. With limited posed images from the scene, NeRF fails to generalize well to novel views and may collapse to trivial solutions in unobserved regions. This makes NeRF impractical under resource-constrained scenarios. In this paper, we present a novel learning framework, ActiveNeRF, aiming to model a 3D scene with a constrained input budget. Specifically, we first incorporate uncertainty estimation into a NeRF model, which ensures robustness under few observations and provides an interpretation of how NeRF understands the scene. On this basis, we propose to supplement the existing training set with newly captured samples based on an active learning scheme. By evaluating the reduction of uncertainty given new inputs, we select the samples that bring the most information gain. In this way, the quality of novel view synthesis can be improved with minimal additional resources. Extensive experiments validate the performance of our model on both realistic and synthetic scenes, especially with scarcer training data. Code will be released at \url{https://github.com/LeapLabTHU/ActiveNeRF}.
Learning to Weight Samples for Dynamic Early-exiting Networks
Sep 17, 2022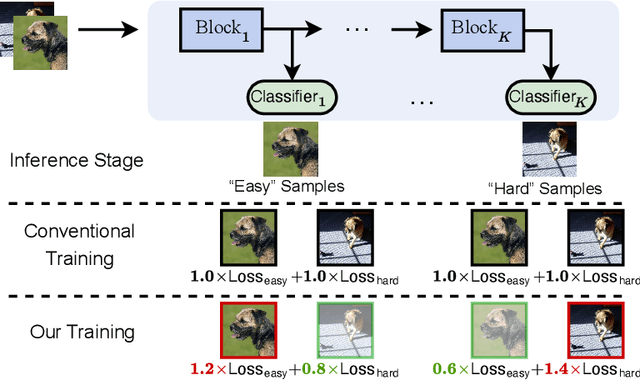
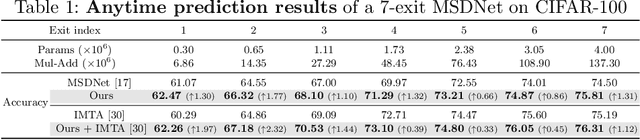

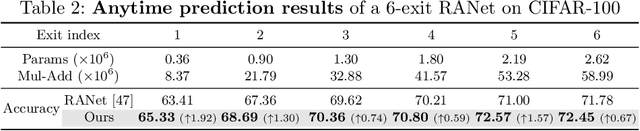
Early exiting is an effective paradigm for improving the inference efficiency of deep networks. By constructing classifiers with varying resource demands (the exits), such networks allow easy samples to be output at early exits, removing the need for executing deeper layers. While existing works mainly focus on the architectural design of multi-exit networks, the training strategies for such models are largely left unexplored. The current state-of-the-art models treat all samples the same during training. However, the early-exiting behavior during testing has been ignored, leading to a gap between training and testing. In this paper, we propose to bridge this gap by sample weighting. Intuitively, easy samples, which generally exit early in the network during inference, should contribute more to training early classifiers. The training of hard samples (mostly exit from deeper layers), however, should be emphasized by the late classifiers. Our work proposes to adopt a weight prediction network to weight the loss of different training samples at each exit. This weight prediction network and the backbone model are jointly optimized under a meta-learning framework with a novel optimization objective. By bringing the adaptive behavior during inference into the training phase, we show that the proposed weighting mechanism consistently improves the trade-off between classification accuracy and inference efficiency. Code is available at https://github.com/LeapLabTHU/L2W-DEN.
Extreme Masking for Learning Instance and Distributed Visual Representations
Jun 09, 2022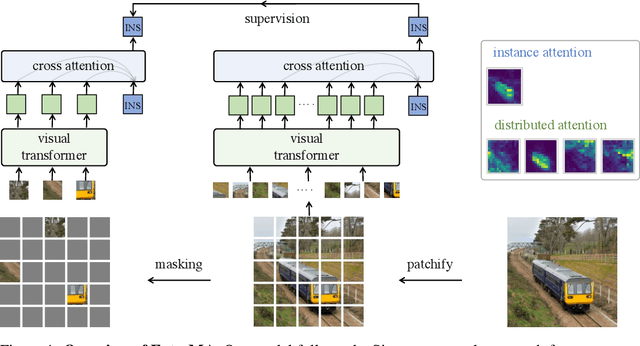


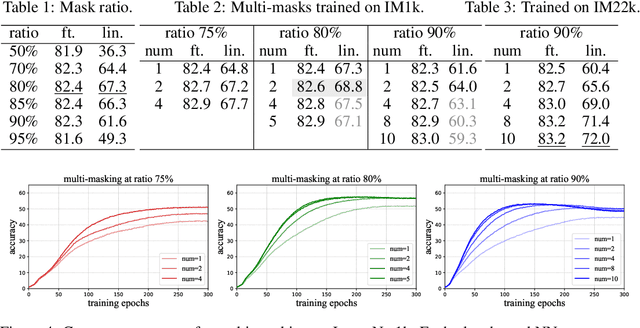
The paper presents a scalable approach for learning distributed representations over individual tokens and a holistic instance representation simultaneously. We use self-attention blocks to represent distributed tokens, followed by cross-attention blocks to aggregate the holistic instance. The core of the approach is the use of extremely large token masking (75%-90%) as the data augmentation for supervision. Our model, named ExtreMA, follows the plain BYOL approach where the instance representation from the unmasked subset is trained to predict that from the intact input. Learning requires the model to capture informative variations in an instance, instead of encouraging invariances. The paper makes three contributions: 1) Random masking is a strong and computationally efficient data augmentation for learning generalizable attention representations. 2) With multiple sampling per instance, extreme masking greatly speeds up learning and hungers for more data. 3) Distributed representations can be learned from the instance supervision alone, unlike per-token supervisions in masked modeling.
Domain Adaptation via Prompt Learning
Feb 14, 2022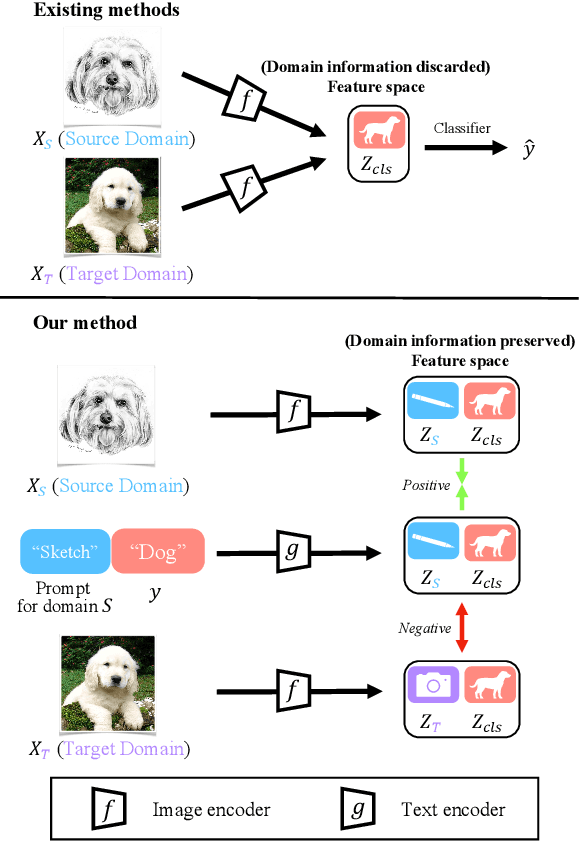

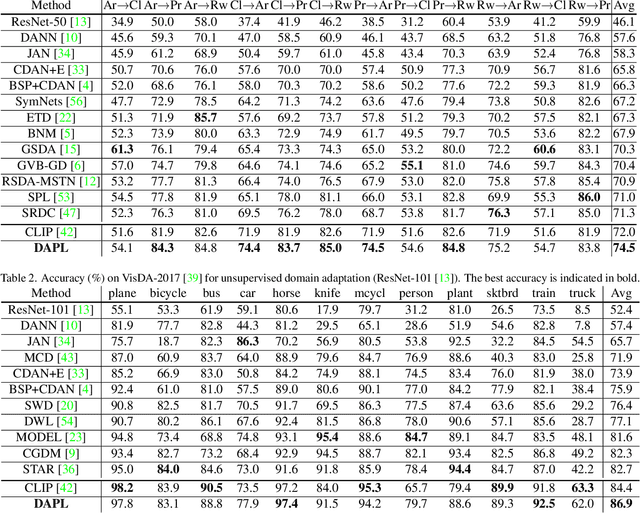
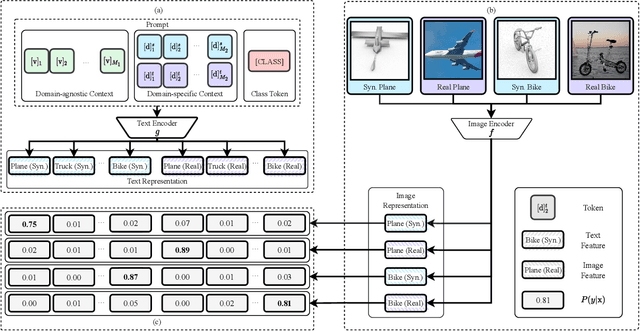
Unsupervised domain adaption (UDA) aims to adapt models learned from a well-annotated source domain to a target domain, where only unlabeled samples are given. Current UDA approaches learn domain-invariant features by aligning source and target feature spaces. Such alignments are imposed by constraints such as statistical discrepancy minimization or adversarial training. However, these constraints could lead to the distortion of semantic feature structures and loss of class discriminability. In this paper, we introduce a novel prompt learning paradigm for UDA, named Domain Adaptation via Prompt Learning (DAPL). In contrast to prior works, our approach makes use of pre-trained vision-language models and optimizes only very few parameters. The main idea is to embed domain information into prompts, a form of representations generated from natural language, which is then used to perform classification. This domain information is shared only by images from the same domain, thereby dynamically adapting the classifier according to each domain. By adopting this paradigm, we show that our model not only outperforms previous methods on several cross-domain benchmarks but also is very efficient to train and easy to implement.