 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Masking for Learning Instance and Distributed Visual Representations
Paper and Code
Jun 09, 2022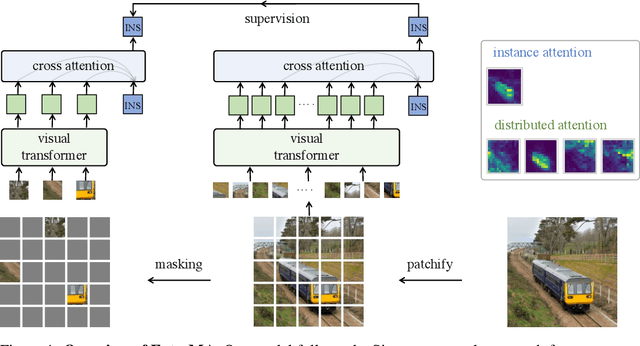


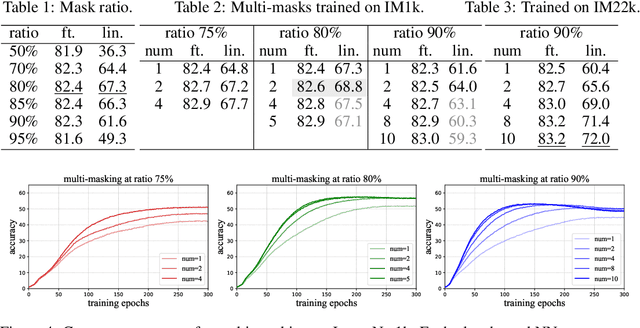
The paper presents a scalable approach for learning distributed representations over individual tokens and a holistic instance representation simultaneously. We use self-attention blocks to represent distributed tokens, followed by cross-attention blocks to aggregate the holistic instance. The core of the approach is the use of extremely large token masking (75%-90%) as the data augmentation for supervision. Our model, named ExtreMA, follows the plain BYOL approach where the instance representation from the unmasked subset is trained to predict that from the intact input. Learning requires the model to capture informative variations in an instance, instead of encouraging invariances. The paper makes three contributions: 1) Random masking is a strong and computationally efficient data augmentation for learning generalizable attention representations. 2) With multiple sampling per instance, extreme masking greatly speeds up learning and hungers for more data. 3) Distributed representations can be learned from the instance supervision alone, unlike per-token supervisions in masked modeling.