 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Vision-Language Pre-trained Models for Incremental Face Presentation Attack Detection
Dec 24, 2025Face Presentation Attack Detection (PAD) demands incremental learning (IL) to combat evolving spoofing tactics and domains. Privacy regulations, however, forbid retaining past data, necessitating rehearsal-free IL (RF-IL). Vision-Language Pre-trained (VLP) models, with their prompt-tunable cross-modal representations, enable efficient adaptation to new spoofing styles and domains. Capitalizing on this strength, we propose \textbf{SVLP-IL}, a VLP-based RF-IL framework that balances stability and plasticity via \textit{Multi-Aspect Prompting} (MAP) and \textit{Selective Elastic Weight Consolidation} (SEWC). MAP isolates domain dependencies, enhances distribution-shift sensitivity, and mitigates forgetting by jointly exploiting universal and domain-specific cues. SEWC selectively preserves critical weights from previous tasks, retaining essential knowledge while allowing flexibility for new adaptations. Comprehensive experiments across multiple PAD benchmarks show that SVLP-IL significantly reduces catastrophic forgetting and enhances performance on unseen domains. SVLP-IL offers a privacy-compliant, practical solution for robust lifelong PAD deployment in RF-IL settings.
A Study of Finetuning Video Transformers for Multi-view Geometry Tasks
Dec 21, 2025This paper presents an investigation of vision transformer learning for multi-view geometry tasks, such as optical flow estimation, by fine-tuning video foundation models. Unlike previous methods that involve custom architectural designs and task-specific pretraining, our research finds that general-purpose models pretrained on videos can be readily transferred to multi-view problems with minimal adaptation. The core insight is that general-purpose attention between patches learns temporal and spatial information for geometric reasoning. We demonstrate that appending a linear decoder to the Transformer backbone produces satisfactory results, and iterative refinement can further elevate performance to stateof-the-art levels. This conceptually simple approach achieves top cross-dataset generalization results for optical flow estimation with end-point error (EPE) of 0.69, 1.78, and 3.15 on the Sintel clean, Sintel final, and KITTI datasets, respectively. Our method additionally establishes a new record on the online test benchmark with EPE values of 0.79, 1.88, and F1 value of 3.79. Applications to 3D depth estimation and stereo matching also show strong performance, illustrating the versatility of video-pretrained models in addressing geometric vision tasks.
Seeing Beyond Haze: Generative Nighttime Image Dehazing
Mar 11, 2025



Nighttime image dehazing is particularly challenging when dense haze and intense glow severely degrade or completely obscure background information. Existing methods often encounter difficulties due to insufficient background priors and limited generative ability, both essential for handling such conditions. In this paper, we introduce BeyondHaze, a generative nighttime dehazing method that not only significantly reduces haze and glow effects but also infers background information in regions where it may be absent. Our approach is developed on two main ideas: gaining strong background priors by adapting image diffusion models to the nighttime dehazing problem, and enhancing generative ability for haze- and glow-obscured scene areas through guided training. Task-specific nighttime dehazing knowledge is distilled into an image diffusion model in a manner that preserves its capacity to generate clean images. The diffusion model is additionally trained on image pairs designed to improve its ability to generate background details and content that are missing in the input image due to haze effects. Since generative models are susceptible to hallucinations, we develop our framework to allow user control over the generative level, balancing visual realism and factual accuracy. Experiments on real-world images demonstrate that BeyondHaze effectively restores visibility in dense nighttime haze.
You Only Need Less Attention at Each Stage in Vision Transformers
Jun 01, 2024The advent of Vision Transformers (ViTs) marks a substantial paradigm shift in the realm of computer vision. ViTs capture the global information of images through self-attention modules, which perform dot product computations among patchified image tokens. While self-attention modules empower ViTs to capture long-range dependencies, the computational complexity grows quadratically with the number of tokens, which is a major hindrance to the practical application of ViTs. Moreover, the self-attention mechanism in deep ViTs is also susceptible to the attention saturation issue. Accordingly, we argue against the necessity of computing the attention scores in every layer, and we propose the Less-Attention Vision Transformer (LaViT), which computes only a few attention operations at each stage and calculates the subsequent feature alignments in other layers via attention transformations that leverage the previously calculated attention scores. This novel approach can mitigate two primary issues plaguing traditional self-attention modules: the heavy computational burden and attention saturation. Our proposed architecture offers superior efficiency and ease of implementation, merely requiring matrix multiplications that are highly optimized in contemporary deep learning frameworks. Moreover, our architecture demonstrates exceptional performance across various vision tasks including classification, detection and segmentation.
Image to Pseudo-Episode: Boosting Few-Shot Segmentation by Unlabeled Data
May 14, 2024Few-shot segmentation (FSS) aims to train a model which can segment the object from novel classes with a few labeled samples. The insufficient generalization ability of models leads to unsatisfactory performance when the models lack enough labeled data from the novel classes. Considering that there are abundant unlabeled data available, it is promising to improve the generalization ability by exploiting these various data. For leveraging unlabeled data, we propose a novel method, named Image to Pseudo-Episode (IPE), to generate pseudo-episodes from unlabeled data. Specifically, our method contains two modules, i.e., the pseudo-label generation module and the episode generation module. The former module generates pseudo-labels from unlabeled images by the spectral clustering algorithm, and the latter module generates pseudo-episodes from pseudo-labeled images by data augmentation methods. Extensive experiments on PASCAL-$5^i$ and COCO-$20^i$ demonstrate that our method achieves the state-of-the-art performance for FSS.
Unifying Feature and Cost Aggregation with Transformers for Semantic and Visual Correspondence
Mar 17, 2024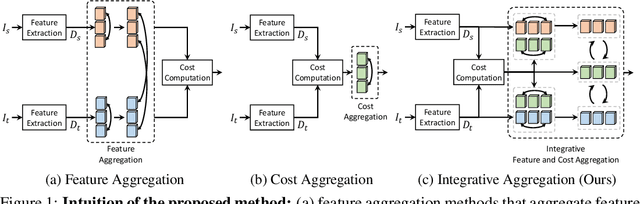
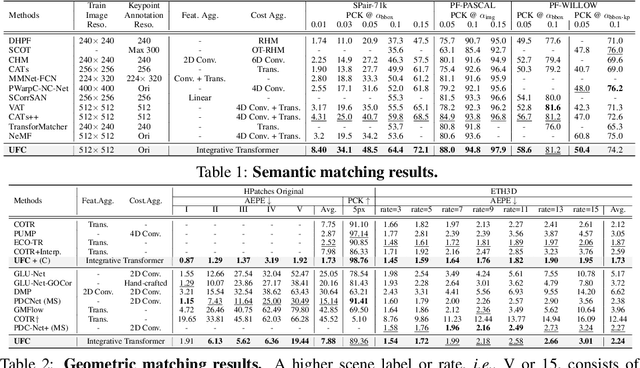


This paper introduces a Transformer-based integrative feature and cost aggregation network designed for dense matching tasks. In the context of dense matching, many works benefit from one of two forms of aggregation: feature aggregation, which pertains to the alignment of similar features, or cost aggregation, a procedure aimed at instilling coherence in the flow estimates across neighboring pixels. In this work, we first show that feature aggregation and cost aggregation exhibit distinct characteristics and reveal the potential for substantial benefits stemming from the judicious use of both aggregation processes. We then introduce a simple yet effective architecture that harnesses self- and cross-attention mechanisms to show that our approach unifies feature aggregation and cost aggregation and effectively harnesses the strengths of both techniques. Within the proposed attention layers, the features and cost volume both complement each other, and the attention layers are interleaved through a coarse-to-fine design to further promote accurate correspondence estimation. Finally at inference, our network produces multi-scale predictions, computes their confidence scores, and selects the most confident flow for final prediction. Our framework is evaluated on standard benchmarks for semantic matching, and also applied to geometric matching, where we show that our approach achieves significant improvements compared to existing methods.
Collaboratively Self-supervised Video Representation Learning for Action Recognition
Jan 15, 2024Considering the close connection between action recognition and human pose estimation, we design a Collaboratively Self-supervised Video Representation (CSVR) learning framework specific to action recognition by jointly considering generative pose prediction and discriminative context matching as pretext tasks. Specifically, our CSVR consists of three branches: a generative pose prediction branch, a discriminative context matching branch, and a video generating branch. Among them, the first one encodes dynamic motion feature by utilizing Conditional-GAN to predict the human poses of future frames, and the second branch extracts static context features by pulling the representations of clips and compressed key frames from the same video together while pushing apart the pairs from different videos. The third branch is designed to recover the current video frames and predict the future ones, for the purpose of collaboratively improving dynamic motion features and static context features. Extensive experiments demonstrate that our method achieves state-of-the-art performance on the UCF101 and HMDB51 datasets.
Exploring Transferability for Randomized Smoothing
Dec 14, 2023Training foundation models on extensive datasets and then finetuning them on specific tasks has emerged as the mainstream approach in artificial intelligence. However, the model robustness, which is a critical aspect for safety, is often optimized for each specific task rather than at the pretraining stage. In this paper, we propose a method for pretraining certifiably robust models that can be readily finetuned for adaptation to a particular task. A key challenge is dealing with the compromise between semantic learning and robustness. We address this with a simple yet highly effective strategy based on significantly broadening the pretraining data distribution, which is shown to greatly benefit finetuning for downstream tasks. Through pretraining on a mixture of clean and various noisy images, we find that surprisingly strong certified accuracy can be achieved even when finetuning on only clean images. Furthermore, this strategy requires just a single model to deal with various noise levels, thus substantially reducing computational costs in relation to previous works that employ multiple models. Despite using just one model, our method can still yield results that are on par with, or even superior to, existing multi-model methods.
NuTime: Numerically Multi-Scaled Embedding for Large-Scale Time Series Pretraining
Oct 12, 2023Recent research on time-series self-supervised models shows great promise in learning semantic representations. However, it has been limited to small-scale datasets, e.g., thousands of temporal sequences. In this work, we make key technical contributions that are tailored to the numerical properties of time-series data and allow the model to scale to large datasets, e.g., millions of temporal sequences. We adopt the Transformer architecture by first partitioning the input into non-overlapping windows. Each window is then characterized by its normalized shape and two scalar values denoting the mean and standard deviation within each window. To embed scalar values that may possess arbitrary numerical scales to high-dimensional vectors, we propose a numerically multi-scaled embedding module enumerating all possible scales for the scalar values. The model undergoes pretraining using the proposed numerically multi-scaled embedding with a simple contrastive objective on a large-scale dataset containing over a million sequences. We study its transfer performance on a number of univariate and multivariate classification benchmarks. Our method exhibits remarkable improvement against previous representation learning approaches and establishes the new state of the art, even compared with domain-specific non-learning-based methods.
Associative Transformer Is A Sparse Representation Learner
Sep 22, 2023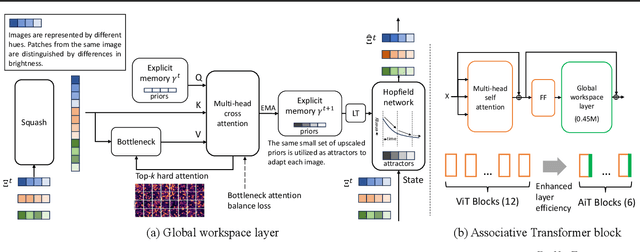
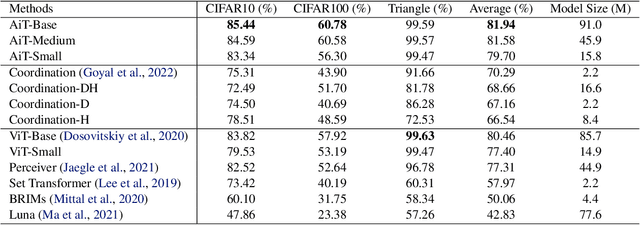
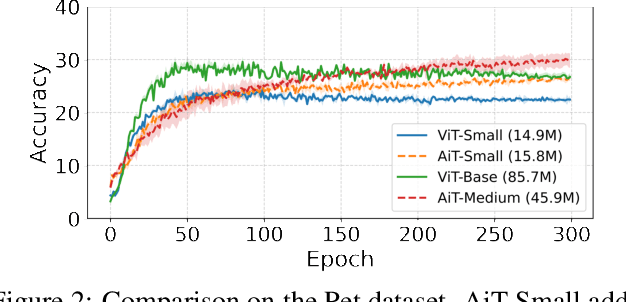
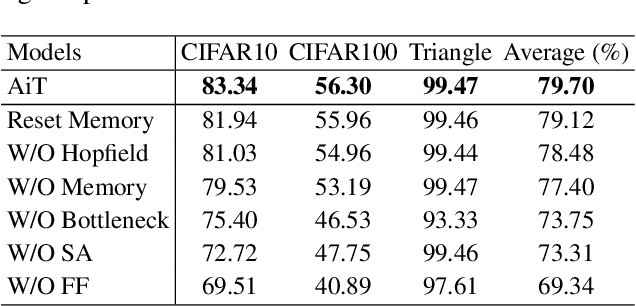
Emerging from the monolithic pairwise attention mechanism in conventional Transformer models, there is a growing interest in leveraging sparse interactions that align more closely with biological principles. Approaches including the Set Transformer and the Perceiver employ cross-attention consolidated with a latent space that forms an attention bottleneck with limited capacity. Building upon recent neuroscience studies of Global Workspace Theory and associative memory, we propose the Associative Transformer (AiT). AiT induces low-rank explicit memory that serves as both priors to guide bottleneck attention in the shared workspace and attractors within associative memory of a Hopfield network. Through joint end-to-end training, these priors naturally develop module specialization, each contributing a distinct inductive bias to form attention bottlenecks. A bottleneck can foster competition among inputs for writing information into the memory. We show that AiT is a sparse representation learner, learning distinct priors through the bottlenecks that are complexity-invariant to input quantities and dimensions. AiT demonstrates its superiority over methods such as the Set Transformer, Vision Transformer, and Coordination in various vision tasks.