 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClipCrop: Conditioned Cropping Driven by Vision-Language Model
Paper and Code
Nov 21, 2022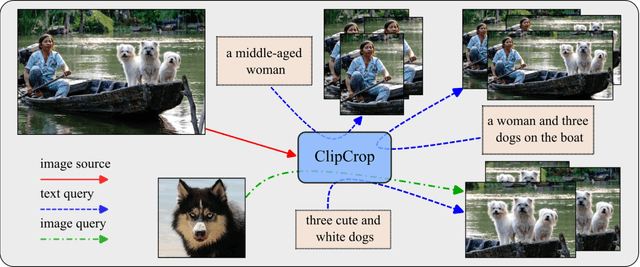
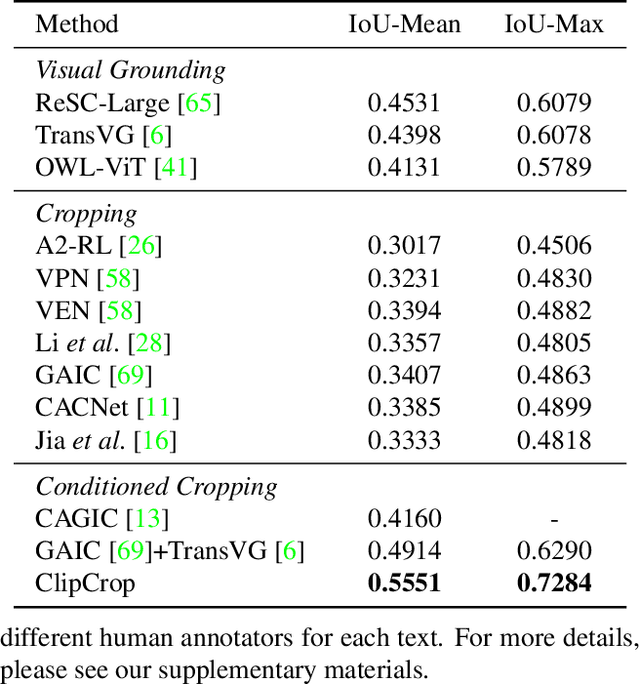
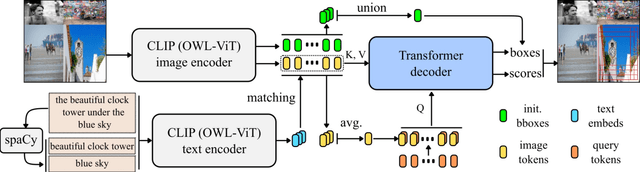
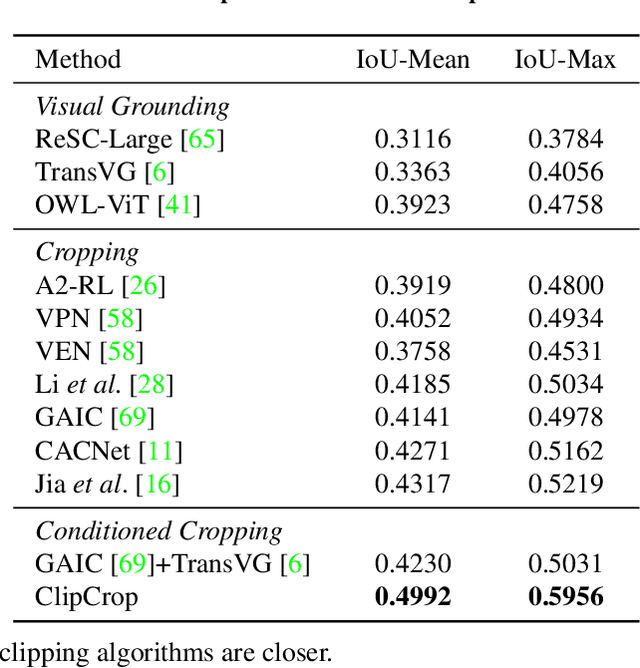
Image cropping has progressed tremendously under the data-driven paradigm. However, current approaches do not account for the intentions of the user, which is an issue especially when the composition of the input image is complex. Moreover, labeling of cropping data is costly and hence the amount of data is limited, leading to poor generalization performance of current algorithms in the wild. In this work, we take advantage of vision-language models as a foundation for creating robust and user-intentional cropping algorithms. By adapting a transformer decoder with a pre-trained CLIP-based detection model, OWL-ViT, we develop a method to perform cropping with a text or image query that reflects the user's intention as guidance. In addition, our pipeline design allows the model to learn text-conditioned aesthetic cropping with a small cropping dataset, while inheriting the open-vocabulary ability acquired from millions of text-image pairs. We validate our model through extensive experiments on existing datasets as well as a new cropping test set we compiled that is characterized by content ambiguity.