 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRESOURCE2SKILL: Distilling Executable Agent Skills from Human-Created Multimodal Resources
Jun 28, 2026Skills are a useful abstraction for software agents, turning human and agent experience into reusable procedural knowledge. Yet existing skill libraries are mostly hand-written, text-centric, or derived from agent traces, leaving tutorial videos and other multimodal human resources largely underused. We present RESOURCE2SKILL, a framework that distills multimodal resources, including tutorial videos, repositories, articles, and reference artifacts, into executable skills for software agents. RESOURCE2SKILL organizes these skills as a hierarchical multimodal Skill Wiki, where each entry combines structured text, code, visual examples, metadata, and provenance. This design preserves complementary signals from different resources: videos capture temporal operations and visual effects, code captures executable tool patterns, and articles or artifacts provide conceptual and stylistic grounding. At inference time, agents retrieve and compose relevant skills from the wiki; when coverage is insufficient, the same construction operator can acquire new skills online. Across seven practical authoring domains, RESOURCE2SKILL improves average overall score by +11.9 percentage points over no-skill agents and outperforms strong harness baselines in 26 of 28 main-aggregate model-domain cells. Ablations confirm the value of multimodal skill format, hierarchical organization, source diversity, selection strategy, and online acquisition.
Covering Human Action Space for Computer Use: Data Synthesis and Benchmark
May 12, 2026Computer-use agents (CUAs) automate on-screen work, as illustrated by GPT-5.4 and Claude. Yet their reliability on complex, low-frequency interactions is still poor, limiting user trust. Our analysis of failure cases from advanced models suggests a long-tail pattern in GUI operations, where a relatively small fraction of complex and diverse interactions accounts for a disproportionate share of task failures. We hypothesize that this issue largely stems from the scarcity of data for complex interactions. To address this problem, we propose a new benchmark CUActSpot for evaluating models' capabilities on complex interactions across five modalities: GUI, text, table, canvas, and natural image, as well as a variety of actions (click, drag, draw, etc.), covering a broader range of interaction types than prior click-centric benchmarks that focus mainly on GUI widgets. We also design a renderer-based data-synthesis pipeline: scenes are automatically generated for each modality, screenshots and element coordinates are recorded, and an LLM produces matching instructions and action traces. After training on this corpus, our Phi-Ground-Any-4B outperforms open-source models with fewer than 32B parameters. We will release our benchmark, data, code, and models at https://github.com/microsoft/Phi-Ground.git
MM-WebAgent: A Hierarchical Multimodal Web Agent for Webpage Generation
Apr 16, 2026The rapid progress of Artificial Intelligence Generated Content (AIGC) tools enables images, videos, and visualizations to be created on demand for webpage design, offering a flexible and increasingly adopted paradigm for modern UI/UX. However, directly integrating such tools into automated webpage generation often leads to style inconsistency and poor global coherence, as elements are generated in isolation. We propose MM-WebAgent, a hierarchical agentic framework for multimodal webpage generation that coordinates AIGC-based element generation through hierarchical planning and iterative self-reflection. MM-WebAgent jointly optimizes global layout, local multimodal content, and their integration, producing coherent and visually consistent webpages. We further introduce a benchmark for multimodal webpage generation and a multi-level evaluation protocol for systematic assessment. Experiments demonstrate that MM-WebAgent outperforms code-generation and agent-based baselines, especially on multimodal element generation and integration. Code & Data: https://aka.ms/mm-webagent.
The Second Challenge on Cross-Domain Few-Shot Object Detection at NTIRE 2026: Methods and Results
Apr 13, 2026Cross-domain few-shot object detection (CD-FSOD) remains a challenging problem for existing object detectors and few-shot learning approaches, particularly when generalizing across distinct domains. As part of NTIRE 2026, we hosted the second CD-FSOD Challenge to systematically evaluate and promote progress in detecting objects in unseen target domains under limited annotation conditions. The challenge received strong community interest, with 128 registered participants and a total of 696 submissions. Among them, 31 teams actively participated, and 19 teams submitted valid final results. Participants explored a wide range of strategies, introducing innovative methods that push the performance frontier under both open-source and closed-source tracks. This report presents a detailed overview of the NTIRE 2026 CD-FSOD Challenge, including a summary of the submitted approaches and an analysis of the final results across all participating teams. Challenge Codes: https://github.com/ohMargin/NTIRE2026_CDFSOD.
BizGenEval: A Systematic Benchmark for Commercial Visual Content Generation
Mar 26, 2026Recent advances in image generation models have expanded their applications beyond aesthetic imagery toward practical visual content creation. However, existing benchmarks mainly focus on natural image synthesis and fail to systematically evaluate models under the structured and multi-constraint requirements of real-world commercial design tasks. In this work, we introduce BizGenEval, a systematic benchmark for commercial visual content generation. The benchmark spans five representative document types: slides, charts, webpages, posters, and scientific figures, and evaluates four key capability dimensions: text rendering, layout control, attribute binding, and knowledge-based reasoning, forming 20 diverse evaluation tasks. BizGenEval contains 400 carefully curated prompts and 8000 human-verified checklist questions to rigorously assess whether generated images satisfy complex visual and semantic constraints. We conduct large-scale benchmarking on 26 popular image generation systems, including state-of-the-art commercial APIs and leading open-source models. The results reveal substantial capability gaps between current generative models and the requirements of professional visual content creation. We hope BizGenEval serves as a standardized benchmark for real-world commercial visual content generation.
Can Vision Language Models Assess Graphic Design Aesthetics? A Benchmark, Evaluation, and Dataset Perspective
Mar 01, 2026Assessing the aesthetic quality of graphic design is central to visual communication, yet remains underexplored in vision language models (VLMs). We investigate whether VLMs can evaluate design aesthetics in ways comparable to humans. Prior work faces three key limitations: benchmarks restricted to narrow principles and coarse evaluation protocols, a lack of systematic VLM comparisons, and limited training data for model improvement. In this work, we introduce AesEval-Bench, a comprehensive benchmark spanning four dimensions, twelve indicators, and three fully quantifiable tasks: aesthetic judgment, region selection, and precise localization. Then, we systematically evaluate proprietary, open-source, and reasoning-augmented VLMs, revealing clear performance gaps against the nuanced demands of aesthetic assessment. Moreover, we construct a training dataset to fine-tune VLMs for this domain, leveraging human-guided VLM labeling to produce task labels at scale and indicator-grounded reasoning to tie abstract indicators to concrete design regions.Together, our work establishes the first systematic framework for aesthetic quality assessment in graphic design. Our code and dataset will be released at: \href{https://github.com/arctanxarc/AesEval-Bench}{https://github.com/arctanxarc/AesEval-Bench}
EMoE: Eigenbasis-Guided Routing for Mixture-of-Experts
Jan 17, 2026The relentless scaling of deep learning models has led to unsustainable computational demands, positioning Mixture-of-Experts (MoE) architectures as a promising path towards greater efficiency. However, MoE models are plagued by two fundamental challenges: 1) a load imbalance problem known as the``rich get richer" phenomenon, where a few experts are over-utilized, and 2) an expert homogeneity problem, where experts learn redundant representations, negating their purpose. Current solutions typically employ an auxiliary load-balancing loss that, while mitigating imbalance, often exacerbates homogeneity by enforcing uniform routing at the expense of specialization. To resolve this, we introduce the Eigen-Mixture-of-Experts (EMoE), a novel architecture that leverages a routing mechanism based on a learned orthonormal eigenbasis. EMoE projects input tokens onto this shared eigenbasis and routes them based on their alignment with the principal components of the feature space. This principled, geometric partitioning of data intrinsically promotes both balanced expert utilization and the development of diverse, specialized experts, all without the need for a conflicting auxiliary loss function. Our code is publicly available at https://github.com/Belis0811/EMoE.
ERMoE: Eigen-Reparameterized Mixture-of-Experts for Stable Routing and Interpretable Specialization
Nov 14, 2025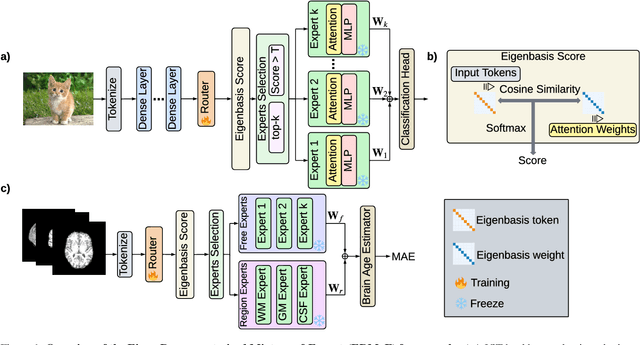
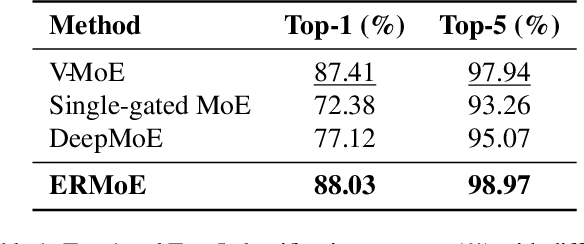
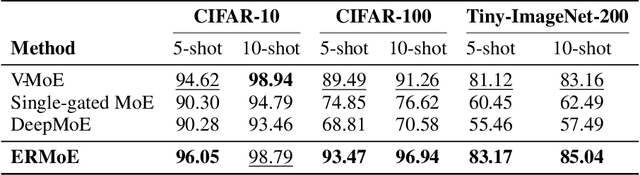
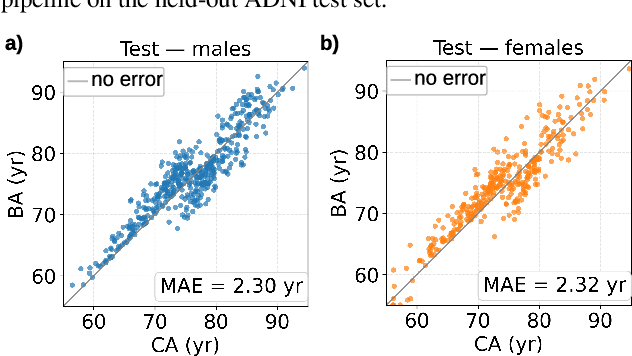
Mixture-of-Experts (MoE) architectures expand model capacity by sparsely activating experts but face two core challenges: misalignment between router logits and each expert's internal structure leads to unstable routing and expert underutilization, and load imbalances create straggler bottlenecks. Standard solutions, such as auxiliary load-balancing losses, can reduce load disparities but often weaken expert specialization and hurt downstream performance. To address these issues, we propose ERMoE, a sparse MoE transformer that reparameterizes each expert in a learned orthonormal eigenbasis and replaces learned gating logits with an "Eigenbasis Score", defined as the cosine similarity between input features and an expert's basis. This content-aware routing ties token assignments directly to experts' representation spaces, stabilizing utilization and promoting interpretable specialization without sacrificing sparsity. Crucially, ERMoE removes the need for explicit balancing losses and avoids the interfering gradients they introduce. We show that ERMoE achieves state-of-the-art accuracy on ImageNet classification and cross-modal image-text retrieval benchmarks (e.g., COCO, Flickr30K), while naturally producing flatter expert load distributions. Moreover, a 3D MRI variant (ERMoE-ba) improves brain age prediction accuracy by more than 7\% and yields anatomically interpretable expert specializations. ERMoE thus introduces a new architectural principle for sparse expert models that directly addresses routing instabilities and enables improved performance with scalable, interpretable specialization.
Neuro-Inspired Information-Theoretic Hierarchical Perception for Multimodal Learning
Apr 15, 2024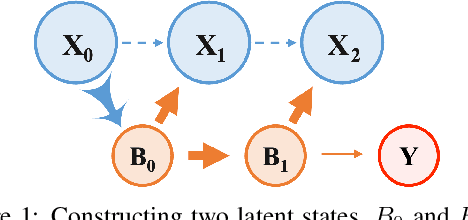
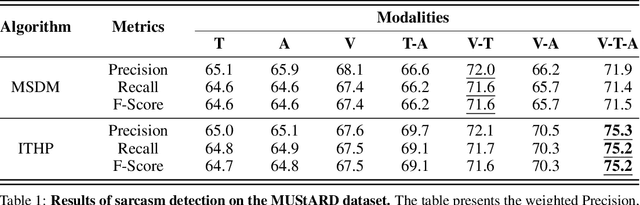
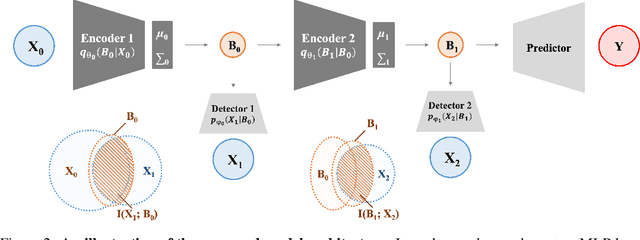

Integrating and processing information from various sources or modalities are critical for obtaining a comprehensive and accurate perception of the real world in autonomous systems and cyber-physical systems. Drawing inspiration from neuroscience, we develop the Information-Theoretic Hierarchical Perception (ITHP) model, which utilizes the concept of information bottleneck. Different from most traditional fusion models that incorporate all modalities identically in neural networks, our model designates a prime modality and regards the remaining modalities as detectors in the information pathway, serving to distill the flow of information. Our proposed perception model focuses on constructing an effective and compact information flow by achieving a balance between the minimization of mutual information between the latent state and the input modal state, and the maximization of mutual information between the latent states and the remaining modal states. This approach leads to compact latent state representations that retain relevant information while minimizing redundancy, thereby substantially enhancing the performance of multimodal representation learning. Experimental evaluations on the MUStARD, CMU-MOSI, and CMU-MOSEI datasets demonstrate that our model consistently distills crucial information in multimodal learning scenarios, outperforming state-of-the-art benchmarks. Remarkably, on the CMU-MOSI dataset, ITHP surpasses human-level performance in the multimodal sentiment binary classification task across all evaluation metrics (i.e., Binary Accuracy, F1 Score, Mean Absolute Error, and Pearson Correlation).
Unlocking Deep Learning: A BP-Free Approach for Parallel Block-Wise Training of Neural Networks
Dec 20, 2023



Backpropagation (BP) has been a successful optimization technique for deep learning models. However, its limitations, such as backward- and update-locking, and its biological implausibility, hinder the concurrent updating of layers and do not mimic the local learning processes observed in the human brain. To address these issues, recent research has suggested using local error signals to asynchronously train network blocks. However, this approach often involves extensive trial-and-error iterations to determine the best configuration for local training. This includes decisions on how to decouple network blocks and which auxiliary networks to use for each block. In our work, we introduce a novel BP-free approach: a block-wise BP-free (BWBPF) neural network that leverages local error signals to optimize distinct sub-neural networks separately, where the global loss is only responsible for updating the output layer. The local error signals used in the BP-free model can be computed in parallel, enabling a potential speed-up in the weight update process through parallel implementation. Our experimental results consistently show that this approach can identify transferable decoupled architectures for VGG and ResNet variations, outperforming models trained with end-to-end backpropagation and other state-of-the-art block-wise learning techniques on datasets such as CIFAR-10 and Tiny-ImageNet. The code is released at https://github.com/Belis0811/BWBPF.