 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIDSR:ComplementaryPolarizedImageDemosaicingandSuper-Resolution
Apr 10, 2025



Polarization cameras can capture multiple polarized images with different polarizer angles in a single shot, bringing convenience to polarization-based downstream tasks. However, their direct outputs are color-polarization filter array (CPFA) raw images, requiring demosaicing to reconstruct full-resolution, full-color polarized images; unfortunately, this necessary step introduces artifacts that make polarization-related parameters such as the degree of polarization (DoP) and angle of polarization (AoP) prone to error. Besides, limited by the hardware design, the resolution of a polarization camera is often much lower than that of a conventional RGB camera. Existing polarized image demosaicing (PID) methods are limited in that they cannot enhance resolution, while polarized image super-resolution (PISR) methods, though designed to obtain high-resolution (HR) polarized images from the demosaicing results, tend to retain or even amplify errors in the DoP and AoP introduced by demosaicing artifacts. In this paper, we propose PIDSR, a joint framework that performs complementary Polarized Image Demosaicing and Super-Resolution, showing the ability to robustly obtain high-quality HR polarized images with more accurate DoP and AoP from a CPFA raw image in a direct manner. Experiments show our PIDSR not only achieves state-of-the-art performance on both synthetic and real data, but also facilitates downstream tasks.
Towards Monocular Shape from Refraction
May 31, 2023Refraction is a common physical phenomenon and has long been researched in computer vision. Objects imaged through a refractive object appear distorted in the image as a function of the shape of the interface between the media. This hinders many computer vision applications, but can be utilized for obtaining the geometry of the refractive interface. Previous approaches for refractive surface recovery largely relied on various priors or additional information like multiple images of the analyzed surface. In contrast, we claim that a simple energy function based on Snell's law enables the reconstruction of an arbitrary refractive surface geometry using just a single image and known background texture and geometry. In the case of a single point, Snell's law has two degrees of freedom, therefore to estimate a surface depth, we need additional information. We show that solving for an entire surface at once introduces implicit parameter-free spatial regularization and yields convincing results when an intelligent initial guess is provided. We demonstrate our approach through simulations and real-world experiments, where the reconstruction shows encouraging results in the single-frame monocular setting.
* 12 pages, 6 figures, The 32nd British Machine Vision Conference (BMVC)
Blur Interpolation Transformer for Real-World Motion from Blur
Nov 21, 2022This paper studies the challenging problem of recovering motion from blur, also known as joint deblurring and interpolation or blur temporal super-resolution. The remaining challenges are twofold: 1) the current methods still leave considerable room for improvement in terms of visual quality even on the synthetic dataset, and 2) poor generalization to real-world data. To this end, we propose a blur interpolation transformer (BiT) to effectively unravel the underlying temporal correlation encoded in blur. Based on multi-scale residual Swin transformer blocks, we introduce dual-end temporal supervision and temporally symmetric ensembling strategies to generate effective features for time-varying motion rendering. In addition, we design a hybrid camera system to collect the first real-world dataset of one-to-many blur-sharp video pairs. Experimental results show that BiT has a significant gain over the state-of-the-art methods on the public dataset Adobe240. Besides, the proposed real-world dataset effectively helps the model generalize well to real blurry scenarios.
ClipCrop: Conditioned Cropping Driven by Vision-Language Model
Nov 21, 2022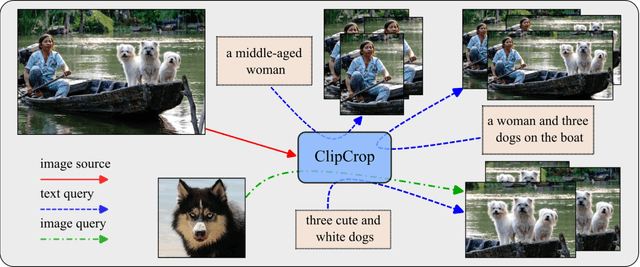
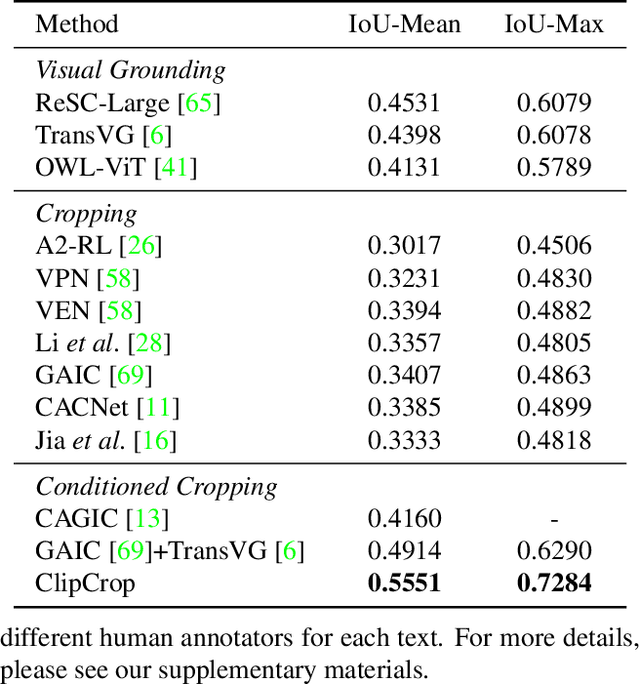
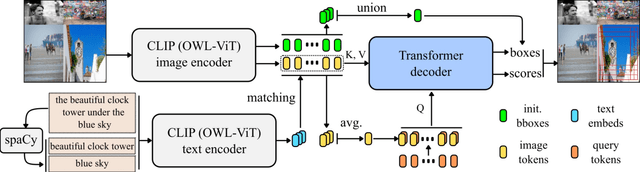
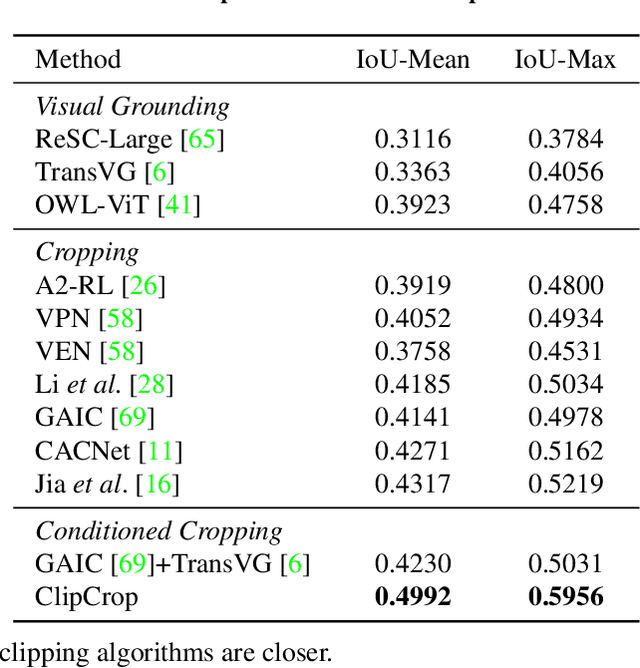
Image cropping has progressed tremendously under the data-driven paradigm. However, current approaches do not account for the intentions of the user, which is an issue especially when the composition of the input image is complex. Moreover, labeling of cropping data is costly and hence the amount of data is limited, leading to poor generalization performance of current algorithms in the wild. In this work, we take advantage of vision-language models as a foundation for creating robust and user-intentional cropping algorithms. By adapting a transformer decoder with a pre-trained CLIP-based detection model, OWL-ViT, we develop a method to perform cropping with a text or image query that reflects the user's intention as guidance. In addition, our pipeline design allows the model to learn text-conditioned aesthetic cropping with a small cropping dataset, while inheriting the open-vocabulary ability acquired from millions of text-image pairs. We validate our model through extensive experiments on existing datasets as well as a new cropping test set we compiled that is characterized by content ambiguity.
Animation from Blur: Multi-modal Blur Decomposition with Motion Guidance
Jul 20, 2022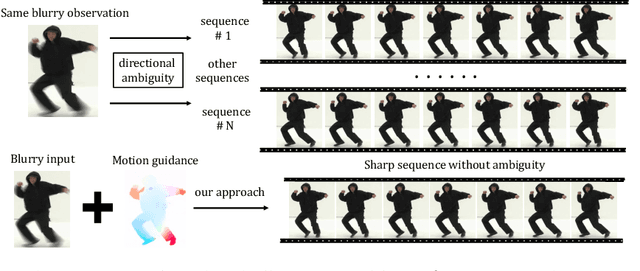
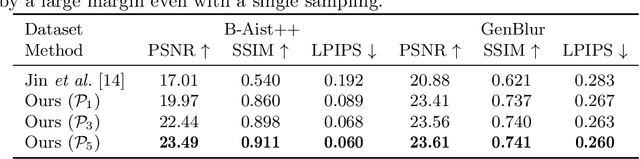
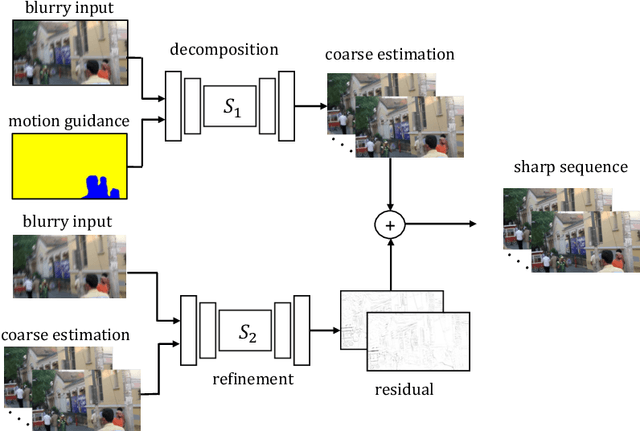

We study the challenging problem of recovering detailed motion from a single motion-blurred image. Existing solutions to this problem estimate a single image sequence without considering the motion ambiguity for each region. Therefore, the results tend to converge to the mean of the multi-modal possibilities. In this paper, we explicitly account for such motion ambiguity, allowing us to generate multiple plausible solutions all in sharp detail. The key idea is to introduce a motion guidance representation, which is a compact quantization of 2D optical flow with only four discrete motion directions. Conditioned on the motion guidance, the blur decomposition is led to a specific, unambiguous solution by using a novel two-stage decomposition network. We propose a unified framework for blur decomposition, which supports various interfaces for generating our motion guidance, including human input, motion information from adjacent video frames, and learning from a video dataset. Extensive experiments on synthesized datasets and real-world data show that the proposed framework is qualitatively and quantitatively superior to previous methods, and also offers the merit of producing physically plausible and diverse solutions. Code is available at https://github.com/zzh-tech/Animation-from-Blur.
Bringing Rolling Shutter Images Alive with Dual Reversed Distortion
Mar 15, 2022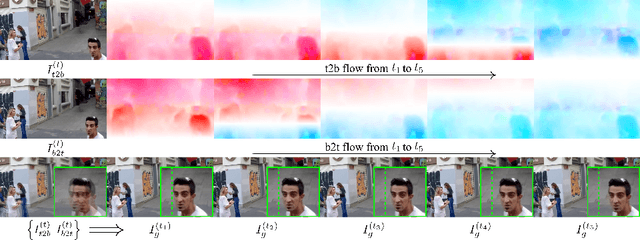

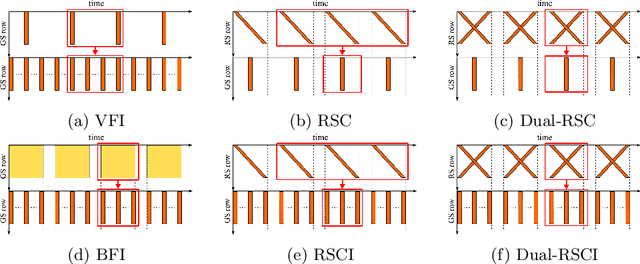
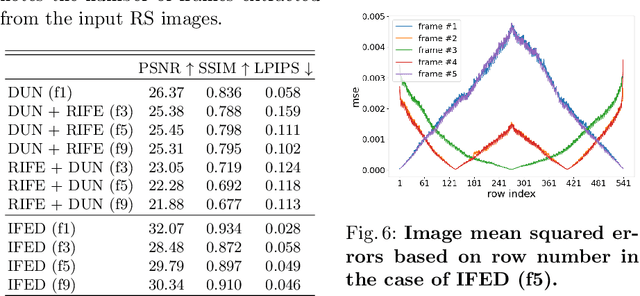
Rolling shutter (RS) distortion can be interpreted as the result of picking a row of pixels from instant global shutter (GS) frames over time during the exposure of the RS camera. This means that the information of each instant GS frame is partially, yet sequentially, embedded into the row-dependent distortion. Inspired by this fact, we address the challenging task of reversing this process, i.e., extracting undistorted GS frames from images suffering from RS distortion. However, since RS distortion is coupled with other factors such as readout settings and the relative velocity of scene elements to the camera, models that only exploit the geometric correlation between temporally adjacent images suffer from poor generality in processing data with different readout settings and dynamic scenes with both camera motion and object motion. In this paper, instead of two consecutive frames, we propose to exploit a pair of images captured by dual RS cameras with reversed RS directions for this highly challenging task. Grounded on the symmetric and complementary nature of dual reversed distortion, we develop a novel end-to-end model, IFED, to generate dual optical flow sequence through iterative learning of the velocity field during the RS time. Extensive experimental results demonstrate that IFED is superior to naive cascade schemes, as well as the state-of-the-art which utilizes adjacent RS images. Most importantly, although it is trained on a synthetic dataset, IFED is shown to be effective at retrieving GS frame sequences from real-world RS distorted images of dynamic scenes.
Efficient Spatio-Temporal Recurrent Neural Network for Video Deblurring
Jun 30, 2021



Real-time video deblurring still remains a challenging task due to the complexity of spatially and temporally varying blur itself and the requirement of low computational cost. To improve the network efficiency, we adopt residual dense blocks into RNN cells, so as to efficiently extract the spatial features of the current frame. Furthermore, a global spatio-temporal attention module is proposed to fuse the effective hierarchical features from past and future frames to help better deblur the current frame. Another issue needs to be addressed urgently is the lack of a real-world benchmark dataset. Thus, we contribute a novel dataset (BSD) to the community, by collecting paired blurry/sharp video clips using a co-axis beam splitter acquisition system. Experimental results show that the proposed method (ESTRNN) can achieve better deblurring performance both quantitatively and qualitatively with less computational cost against state-of-the-art video deblurring methods. In addition, cross-validation experiments between datasets illustrate the high generality of BSD over the synthetic datasets. The code and dataset are released at https://github.com/zzh-tech/ESTRNN.
Multi-view 3D Reconstruction of a Texture-less Smooth Surface of Unknown Generic Reflectance
May 25, 2021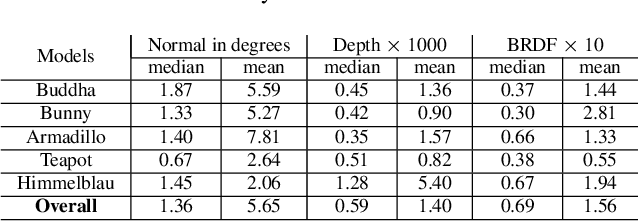

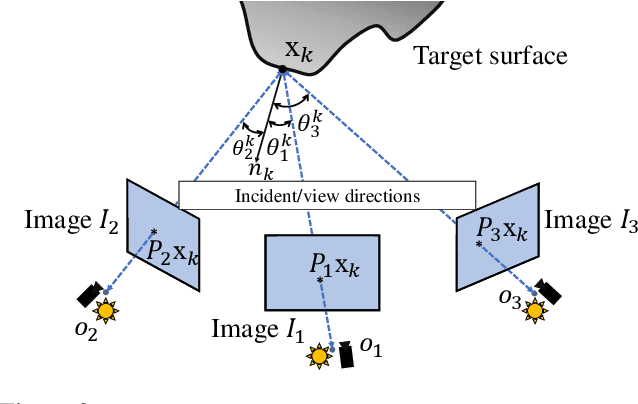
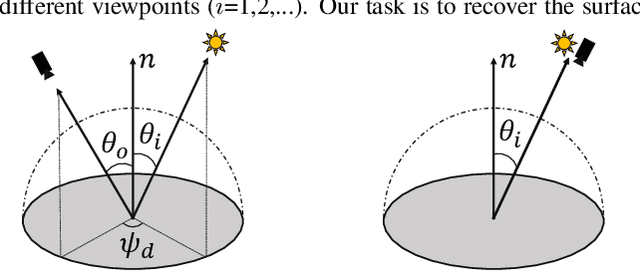
Recovering the 3D geometry of a purely texture-less object with generally unknown surface reflectance (e.g. non-Lambertian) is regarded as a challenging task in multi-view reconstruction. The major obstacle revolves around establishing cross-view correspondences where photometric constancy is violated. This paper proposes a simple and practical solution to overcome this challenge based on a co-located camera-light scanner device. Unlike existing solutions, we do not explicitly solve for correspondence. Instead, we argue the problem is generally well-posed by multi-view geometrical and photometric constraints, and can be solved from a small number of input views. We formulate the reconstruction task as a joint energy minimization over the surface geometry and reflectance. Despite this energy is highly non-convex, we develop an optimization algorithm that robustly recovers globally optimal shape and reflectance even from a random initialization. Extensive experiments on both simulated and real data have validated our method, and possible future extensions are discussed.
One Ring to Rule Them All: a simple solution to multi-view 3D-Reconstruction of shapes with unknown BRDF via a small Recurrent ResNet
Apr 11, 2021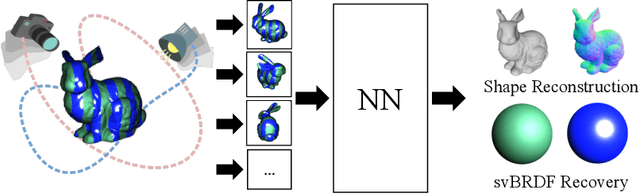
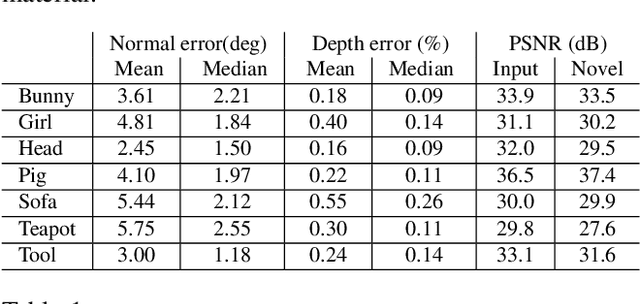
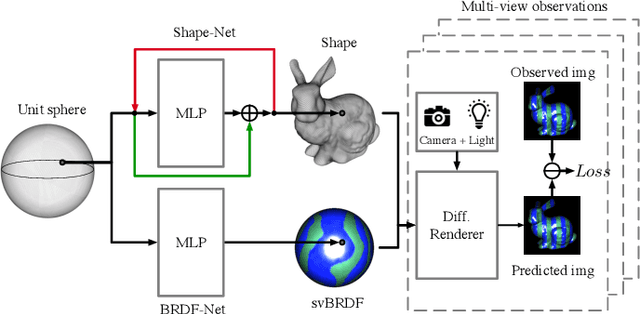
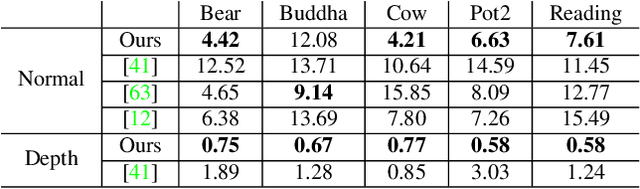
This paper proposes a simple method which solves an open problem of multi-view 3D-Reconstruction for objects with unknown and generic surface materials, imaged by a freely moving camera and a freely moving point light source. The object can have arbitrary (e.g. non-Lambertian), spatially-varying (or everywhere different) surface reflectances (svBRDF). Our solution consists of two smallsized neural networks (dubbed the 'Shape-Net' and 'BRDFNet'), each having about 1,000 neurons, used to parameterize the unknown shape and unknown svBRDF, respectively. Key to our method is a special network design (namely, a ResNet with a global feedback or 'ring' connection), which has a provable guarantee for finding a valid diffeomorphic shape parameterization. Despite the underlying problem is highly non-convex hence impractical to solve by traditional optimization techniques, our method converges reliably to high quality solutions, even without initialization. Extensive experiments demonstrate the superiority of our method, and it naturally enables a wide range of special-effect applications including novel-view-synthesis, relighting, material retouching, and shape exchange without additional coding effort. We encourage the reader to view our demo video for better visualizations.
Towards Rolling Shutter Correction and Deblurring in Dynamic Scenes
Apr 04, 2021
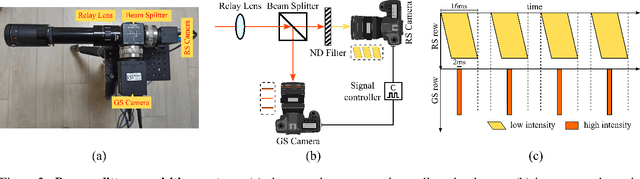


Joint rolling shutter correction and deblurring (RSCD) techniques are critical for the prevalent CMOS cameras. However, current approaches are still based on conventional energy optimization and are developed for static scenes. To enable learning-based approaches to address real-world RSCD problem, we contribute the first dataset, BS-RSCD, which includes both ego-motion and object-motion in dynamic scenes. Real distorted and blurry videos with corresponding ground truth are recorded simultaneously via a beam-splitter-based acquisition system. Since direct application of existing individual rolling shutter correction (RSC) or global shutter deblurring (GSD) methods on RSCD leads to undesirable results due to inherent flaws in the network architecture, we further present the first learning-based model (JCD) for RSCD. The key idea is that we adopt bi-directional warping streams for displacement compensation, while also preserving the non-warped deblurring stream for details restoration. The experimental results demonstrate that JCD achieves state-of-the-art performance on the realistic RSCD dataset (BS-RSCD) and the synthetic RSC dataset (Fastec-RS). The dataset and code are available at https://github.com/zzh-tech/RSCD.