 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAniCrafter: Customizing Realistic Human-Centric Animation via Avatar-Background Conditioning in Video Diffusion Models
May 26, 2025Recent advances in video diffusion models have significantly improved character animation techniques. However, current approaches rely on basic structural conditions such as DWPose or SMPL-X to animate character images, limiting their effectiveness in open-domain scenarios with dynamic backgrounds or challenging human poses. In this paper, we introduce $\textbf{AniCrafter}$, a diffusion-based human-centric animation model that can seamlessly integrate and animate a given character into open-domain dynamic backgrounds while following given human motion sequences. Built on cutting-edge Image-to-Video (I2V) diffusion architectures, our model incorporates an innovative "avatar-background" conditioning mechanism that reframes open-domain human-centric animation as a restoration task, enabling more stable and versatile animation outputs. Experimental results demonstrate the superior performance of our method. Codes will be available at https://github.com/MyNiuuu/AniCrafter.
VideoPainter: Any-length Video Inpainting and Editing with Plug-and-Play Context Control
Mar 07, 2025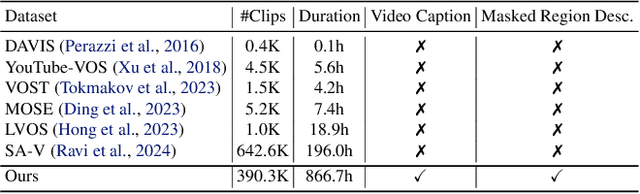
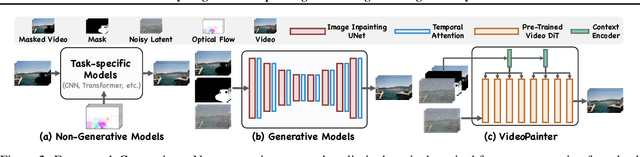
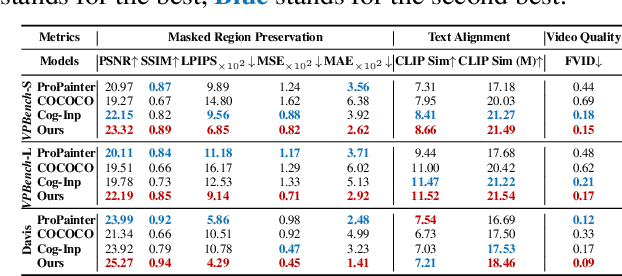
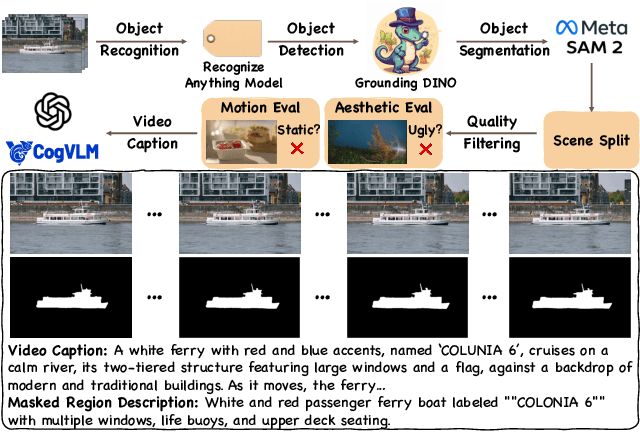
Video inpainting, which aims to restore corrupted video content, has experienced substantial progress. Despite these advances, existing methods, whether propagating unmasked region pixels through optical flow and receptive field priors, or extending image-inpainting models temporally, face challenges in generating fully masked objects or balancing the competing objectives of background context preservation and foreground generation in one model, respectively. To address these limitations, we propose a novel dual-stream paradigm VideoPainter that incorporates an efficient context encoder (comprising only 6% of the backbone parameters) to process masked videos and inject backbone-aware background contextual cues to any pre-trained video DiT, producing semantically consistent content in a plug-and-play manner. This architectural separation significantly reduces the model's learning complexity while enabling nuanced integration of crucial background context. We also introduce a novel target region ID resampling technique that enables any-length video inpainting, greatly enhancing our practical applicability. Additionally, we establish a scalable dataset pipeline leveraging current vision understanding models, contributing VPData and VPBench to facilitate segmentation-based inpainting training and assessment, the largest video inpainting dataset and benchmark to date with over 390K diverse clips. Using inpainting as a pipeline basis, we also explore downstream applications including video editing and video editing pair data generation, demonstrating competitive performance and significant practical potential. Extensive experiments demonstrate VideoPainter's superior performance in both any-length video inpainting and editing, across eight key metrics, including video quality, mask region preservation, and textual coherence.
Consistent Human Image and Video Generation with Spatially Conditioned Diffusion
Dec 19, 2024



Consistent human-centric image and video synthesis aims to generate images or videos with new poses while preserving appearance consistency with a given reference image, which is crucial for low-cost visual content creation. Recent advances based on diffusion models typically rely on separate networks for reference appearance feature extraction and target visual generation, leading to inconsistent domain gaps between references and targets. In this paper, we frame the task as a spatially-conditioned inpainting problem, where the target image is inpainted to maintain appearance consistency with the reference. This approach enables the reference features to guide the generation of pose-compliant targets within a unified denoising network, thereby mitigating domain gaps. Additionally, to better maintain the reference appearance information, we impose a causal feature interaction framework, in which reference features can only query from themselves, while target features can query appearance information from both the reference and the target. To further enhance computational efficiency and flexibility, in practical implementation, we decompose the spatially-conditioned generation process into two stages: reference appearance extraction and conditioned target generation. Both stages share a single denoising network, with interactions restricted to self-attention layers. This proposed method ensures flexible control over the appearance of generated human images and videos. By fine-tuning existing base diffusion models on human video data, our method demonstrates strong generalization to unseen human identities and poses without requiring additional per-instance fine-tuning. Experimental results validate the effectiveness of our approach, showing competitive performance compared to existing methods for consistent human image and video synthesis.
Instruction-based Image Manipulation by Watching How Things Move
Dec 16, 2024



This paper introduces a novel dataset construction pipeline that samples pairs of frames from videos and uses multimodal large language models (MLLMs) to generate editing instructions for training instruction-based image manipulation models. Video frames inherently preserve the identity of subjects and scenes, ensuring consistent content preservation during editing. Additionally, video data captures diverse, natural dynamics-such as non-rigid subject motion and complex camera movements-that are difficult to model otherwise, making it an ideal source for scalable dataset construction. Using this approach, we create a new dataset to train InstructMove, a model capable of instruction-based complex manipulations that are difficult to achieve with synthetically generated datasets. Our model demonstrates state-of-the-art performance in tasks such as adjusting subject poses, rearranging elements, and altering camera perspectives.
ReVideo: Remake a Video with Motion and Content Control
May 22, 2024Despite significant advancements in video generation and editing using diffusion models, achieving accurate and localized video editing remains a substantial challenge. Additionally, most existing video editing methods primarily focus on altering visual content, with limited research dedicated to motion editing. In this paper, we present a novel attempt to Remake a Video (ReVideo) which stands out from existing methods by allowing precise video editing in specific areas through the specification of both content and motion. Content editing is facilitated by modifying the first frame, while the trajectory-based motion control offers an intuitive user interaction experience. ReVideo addresses a new task involving the coupling and training imbalance between content and motion control. To tackle this, we develop a three-stage training strategy that progressively decouples these two aspects from coarse to fine. Furthermore, we propose a spatiotemporal adaptive fusion module to integrate content and motion control across various sampling steps and spatial locations. Extensive experiments demonstrate that our ReVideo has promising performance on several accurate video editing applications, i.e., (1) locally changing video content while keeping the motion constant, (2) keeping content unchanged and customizing new motion trajectories, (3) modifying both content and motion trajectories. Our method can also seamlessly extend these applications to multi-area editing without specific training, demonstrating its flexibility and robustness.
Rolling Shutter Correction with Intermediate Distortion Flow Estimation
Apr 09, 2024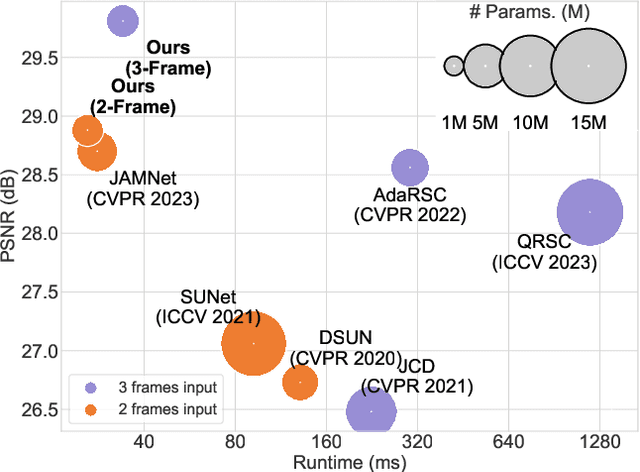
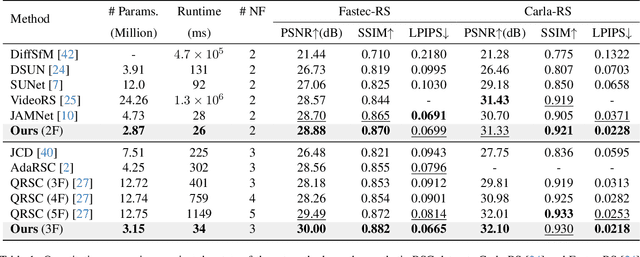
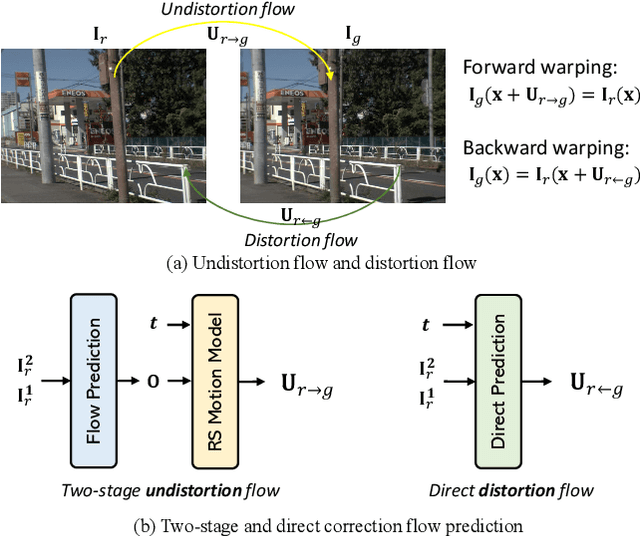
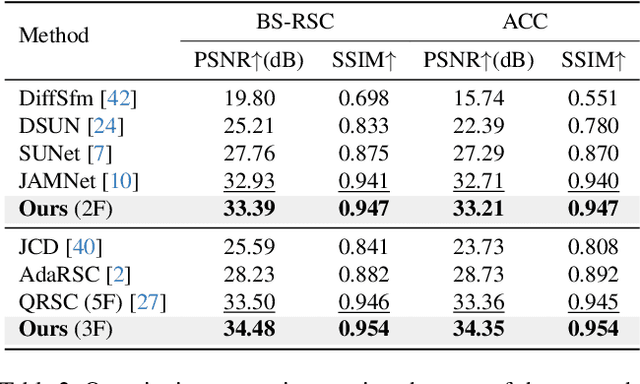
This paper proposes to correct the rolling shutter (RS) distorted images by estimating the distortion flow from the global shutter (GS) to RS directly. Existing methods usually perform correction using the undistortion flow from the RS to GS. They initially predict the flow from consecutive RS frames, subsequently rescaling it as the displacement fields from the RS frame to the underlying GS image using time-dependent scaling factors. Following this, RS-aware forward warping is employed to convert the RS image into its GS counterpart. Nevertheless, this strategy is prone to two shortcomings. First, the undistortion flow estimation is rendered inaccurate by merely linear scaling the flow, due to the complex non-linear motion nature. Second, RS-aware forward warping often results in unavoidable artifacts. To address these limitations, we introduce a new framework that directly estimates the distortion flow and rectifies the RS image with the backward warping operation. More specifically, we first propose a global correlation-based flow attention mechanism to estimate the initial distortion flow and GS feature jointly, which are then refined by the following coarse-to-fine decoder layers. Additionally, a multi-distortion flow prediction strategy is integrated to mitigate the issue of inaccurate flow estimation further. Experimental results validate the effectiveness of the proposed method, which outperforms state-of-the-art approaches on various benchmarks while maintaining high efficiency. The project is available at \url{https://github.com/ljzycmd/DFRSC}.
Taming Lookup Tables for Efficient Image Retouching
Mar 28, 2024The widespread use of high-definition screens in edge devices, such as end-user cameras, smartphones, and televisions, is spurring a significant demand for image enhancement. Existing enhancement models often optimize for high performance while falling short of reducing hardware inference time and power consumption, especially on edge devices with constrained computing and storage resources. To this end, we propose Image Color Enhancement Lookup Table (ICELUT) that adopts LUTs for extremely efficient edge inference, without any convolutional neural network (CNN). During training, we leverage pointwise (1x1) convolution to extract color information, alongside a split fully connected layer to incorporate global information. Both components are then seamlessly converted into LUTs for hardware-agnostic deployment. ICELUT achieves near-state-of-the-art performance and remarkably low power consumption. We observe that the pointwise network structure exhibits robust scalability, upkeeping the performance even with a heavily downsampled 32x32 input image. These enable ICELUT, the first-ever purely LUT-based image enhancer, to reach an unprecedented speed of 0.4ms on GPU and 7ms on CPU, at least one order faster than any CNN solution. Codes are available at https://github.com/Stephen0808/ICELUT.
PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding
Dec 07, 2023



Recent advances in text-to-image generation have made remarkable progress in synthesizing realistic human photos conditioned on given text prompts. However, existing personalized generation methods cannot simultaneously satisfy the requirements of high efficiency, promising identity (ID) fidelity, and flexible text controllability. In this work, we introduce PhotoMaker, an efficient personalized text-to-image generation method, which mainly encodes an arbitrary number of input ID images into a stack ID embedding for preserving ID information. Such an embedding, serving as a unified ID representation, can not only encapsulate the characteristics of the same input ID comprehensively, but also accommodate the characteristics of different IDs for subsequent integration. This paves the way for more intriguing and practically valuable applications. Besides, to drive the training of our PhotoMaker, we propose an ID-oriented data construction pipeline to assemble the training data. Under the nourishment of the dataset constructed through the proposed pipeline, our PhotoMaker demonstrates better ID preservation ability than test-time fine-tuning based methods, yet provides significant speed improvements, high-quality generation results, strong generalization capabilities, and a wide range of applications. Our project page is available at https://photo-maker.github.io/
CustomNet: Zero-shot Object Customization with Variable-Viewpoints in Text-to-Image Diffusion Models
Oct 30, 2023Incorporating a customized object into image generation presents an attractive feature in text-to-image generation. However, existing optimization-based and encoder-based methods are hindered by drawbacks such as time-consuming optimization, insufficient identity preservation, and a prevalent copy-pasting effect. To overcome these limitations, we introduce CustomNet, a novel object customization approach that explicitly incorporates 3D novel view synthesis capabilities into the object customization process. This integration facilitates the adjustment of spatial position relationships and viewpoints, yielding diverse outputs while effectively preserving object identity. Moreover, we introduce delicate designs to enable location control and flexible background control through textual descriptions or specific user-defined images, overcoming the limitations of existing 3D novel view synthesis methods. We further leverage a dataset construction pipeline that can better handle real-world objects and complex backgrounds. Equipped with these designs, our method facilitates zero-shot object customization without test-time optimization, offering simultaneous control over the viewpoints, location, and background. As a result, our CustomNet ensures enhanced identity preservation and generates diverse, harmonious outputs.
Assessor360: Multi-sequence Network for Blind Omnidirectional Image Quality Assessment
May 24, 2023Blind Omnidirectional Image Quality Assessment (BOIQA) aims to objectively assess the human perceptual quality of omnidirectional images (ODIs) without relying on pristine-quality image information. It is becoming more significant with the increasing advancement of virtual reality (VR) technology. However, the quality assessment of ODIs is severely hampered by the fact that the existing BOIQA pipeline lacks the modeling of the observer's browsing process. To tackle this issue, we propose a novel multi-sequence network for BOIQA called Assessor360, which is derived from the realistic multi-assessor ODI quality assessment procedure. Specifically, we propose a generalized Recursive Probability Sampling (RPS) method for the BOIQA task, combining content and detailed information to generate multiple pseudo viewport sequences from a given starting point. Additionally, we design a Multi-scale Feature Aggregation (MFA) module with Distortion-aware Block (DAB) to fuse distorted and semantic features of each viewport. We also devise TMM to learn the viewport transition in the temporal domain. Extensive experimental results demonstrate that Assessor360 outperforms state-of-the-art methods on multiple OIQA datasets.