 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewardDance: Reward Scaling in Visual Generation
Sep 10, 2025Reward Models (RMs) are critical for improving generation models via Reinforcement Learning (RL), yet the RM scaling paradigm in visual generation remains largely unexplored. It primarily due to fundamental limitations in existing approaches: CLIP-based RMs suffer from architectural and input modality constraints, while prevalent Bradley-Terry losses are fundamentally misaligned with the next-token prediction mechanism of Vision-Language Models (VLMs), hindering effective scaling. More critically, the RLHF optimization process is plagued by Reward Hacking issue, where models exploit flaws in the reward signal without improving true quality. To address these challenges, we introduce RewardDance, a scalable reward modeling framework that overcomes these barriers through a novel generative reward paradigm. By reformulating the reward score as the model's probability of predicting a "yes" token, indicating that the generated image outperforms a reference image according to specific criteria, RewardDance intrinsically aligns reward objectives with VLM architectures. This alignment unlocks scaling across two dimensions: (1) Model Scaling: Systematic scaling of RMs up to 26 billion parameters; (2) Context Scaling: Integration of task-specific instructions, reference examples, and chain-of-thought (CoT) reasoning. Extensive experiments demonstrate that RewardDance significantly surpasses state-of-the-art methods in text-to-image, text-to-video, and image-to-video generation. Crucially, we resolve the persistent challenge of "reward hacking": Our large-scale RMs exhibit and maintain high reward variance during RL fine-tuning, proving their resistance to hacking and ability to produce diverse, high-quality outputs. It greatly relieves the mode collapse problem that plagues smaller models.
UniMC: Taming Diffusion Transformer for Unified Keypoint-Guided Multi-Class Image Generation
Jul 03, 2025Although significant advancements have been achieved in the progress of keypoint-guided Text-to-Image diffusion models, existing mainstream keypoint-guided models encounter challenges in controlling the generation of more general non-rigid objects beyond humans (e.g., animals). Moreover, it is difficult to generate multiple overlapping humans and animals based on keypoint controls solely. These challenges arise from two main aspects: the inherent limitations of existing controllable methods and the lack of suitable datasets. First, we design a DiT-based framework, named UniMC, to explore unifying controllable multi-class image generation. UniMC integrates instance- and keypoint-level conditions into compact tokens, incorporating attributes such as class, bounding box, and keypoint coordinates. This approach overcomes the limitations of previous methods that struggled to distinguish instances and classes due to their reliance on skeleton images as conditions. Second, we propose HAIG-2.9M, a large-scale, high-quality, and diverse dataset designed for keypoint-guided human and animal image generation. HAIG-2.9M includes 786K images with 2.9M instances. This dataset features extensive annotations such as keypoints, bounding boxes, and fine-grained captions for both humans and animals, along with rigorous manual inspection to ensure annotation accuracy. Extensive experiments demonstrate the high quality of HAIG-2.9M and the effectiveness of UniMC, particularly in heavy occlusions and multi-class scenarios.
MagicDistillation: Weak-to-Strong Video Distillation for Large-Scale Portrait Few-Step Synthesis
Mar 17, 2025



Fine-tuning open-source large-scale VDMs for the portrait video synthesis task can result in significant improvements across multiple dimensions, such as visual quality and natural facial motion dynamics. Despite their advancements, how to achieve step distillation and reduce the substantial computational overhead of large-scale VDMs remains unexplored. To fill this gap, this paper proposes Weak-to-Strong Video Distillation (W2SVD) to mitigate both the issue of insufficient training memory and the problem of training collapse observed in vanilla DMD during the training process. Specifically, we first leverage LoRA to fine-tune the fake diffusion transformer (DiT) to address the out-of-memory issue. Then, we employ the W2S distribution matching to adjust the real DiT's parameter, subtly shifting it toward the fake DiT's parameter. This adjustment is achieved by utilizing the weak weight of the low-rank branch, effectively alleviate the conundrum where the video synthesized by the few-step generator deviates from the real data distribution, leading to inaccuracies in the KL divergence approximation. Additionally, we minimize the distance between the fake data distribution and the ground truth distribution to further enhance the visual quality of the synthesized videos. As experimentally demonstrated on HunyuanVideo, W2SVD surpasses the standard Euler, LCM, DMD and even the 28-step standard sampling in FID/FVD and VBench in 1/4-step video synthesis. The project page is in https://w2svd.github.io/W2SVD/.
Modality-Composable Diffusion Policy via Inference-Time Distribution-level Composition
Mar 16, 2025Diffusion Policy (DP) has attracted significant attention as an effective method for policy representation due to its capacity to model multi-distribution dynamics. However, current DPs are often based on a single visual modality (e.g., RGB or point cloud), limiting their accuracy and generalization potential. Although training a generalized DP capable of handling heterogeneous multimodal data would enhance performance, it entails substantial computational and data-related costs. To address these challenges, we propose a novel policy composition method: by leveraging multiple pre-trained DPs based on individual visual modalities, we can combine their distributional scores to form a more expressive Modality-Composable Diffusion Policy (MCDP), without the need for additional training. Through extensive empirical experiments on the RoboTwin dataset, we demonstrate the potential of MCDP to improve both adaptability and performance. This exploration aims to provide valuable insights into the flexible composition of existing DPs, facilitating the development of generalizable cross-modality, cross-domain, and even cross-embodiment policies. Our code is open-sourced at https://github.com/AndyCao1125/MCDP.
MagicInfinite: Generating Infinite Talking Videos with Your Words and Voice
Mar 07, 2025We present MagicInfinite, a novel diffusion Transformer (DiT) framework that overcomes traditional portrait animation limitations, delivering high-fidelity results across diverse character types-realistic humans, full-body figures, and stylized anime characters. It supports varied facial poses, including back-facing views, and animates single or multiple characters with input masks for precise speaker designation in multi-character scenes. Our approach tackles key challenges with three innovations: (1) 3D full-attention mechanisms with a sliding window denoising strategy, enabling infinite video generation with temporal coherence and visual quality across diverse character styles; (2) a two-stage curriculum learning scheme, integrating audio for lip sync, text for expressive dynamics, and reference images for identity preservation, enabling flexible multi-modal control over long sequences; and (3) region-specific masks with adaptive loss functions to balance global textual control and local audio guidance, supporting speaker-specific animations. Efficiency is enhanced via our innovative unified step and cfg distillation techniques, achieving a 20x inference speed boost over the basemodel: generating a 10 second 540x540p video in 10 seconds or 720x720p in 30 seconds on 8 H100 GPUs, without quality loss. Evaluations on our new benchmark demonstrate MagicInfinite's superiority in audio-lip synchronization, identity preservation, and motion naturalness across diverse scenarios. It is publicly available at https://www.hedra.com/, with examples at https://magicinfinite.github.io/.
Real-time One-Step Diffusion-based Expressive Portrait Videos Generation
Dec 18, 2024



Latent diffusion models have made great strides in generating expressive portrait videos with accurate lip-sync and natural motion from a single reference image and audio input. However, these models are far from real-time, often requiring many sampling steps that take minutes to generate even one second of video-significantly limiting practical use. We introduce OSA-LCM (One-Step Avatar Latent Consistency Model), paving the way for real-time diffusion-based avatars. Our method achieves comparable video quality to existing methods but requires only one sampling step, making it more than 10x faster. To accomplish this, we propose a novel avatar discriminator design that guides lip-audio consistency and motion expressiveness to enhance video quality in limited sampling steps. Additionally, we employ a second-stage training architecture using an editing fine-tuned method (EFT), transforming video generation into an editing task during training to effectively address the temporal gap challenge in single-step generation. Experiments demonstrate that OSA-LCM outperforms existing open-source portrait video generation models while operating more efficiently with a single sampling step.
Real-time Identity Defenses against Malicious Personalization of Diffusion Models
Dec 13, 2024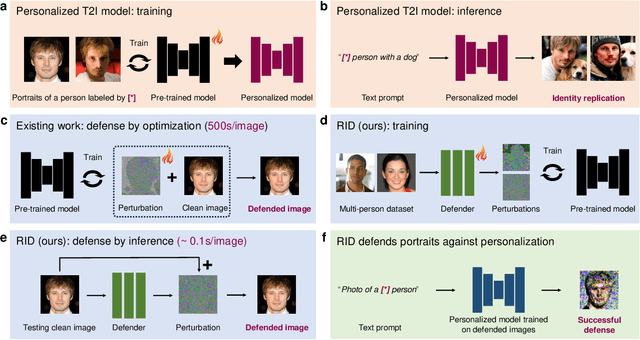
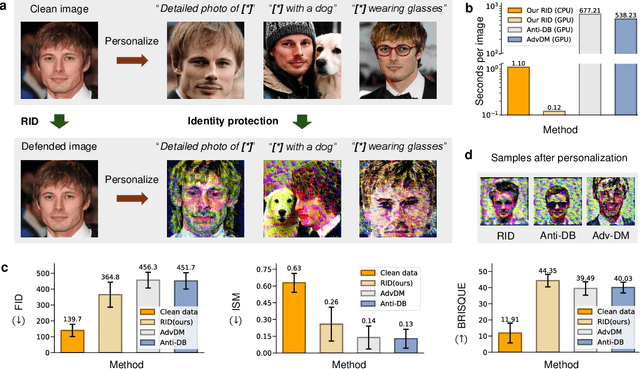
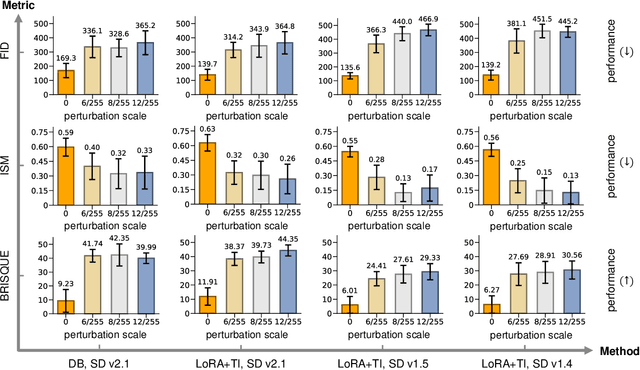
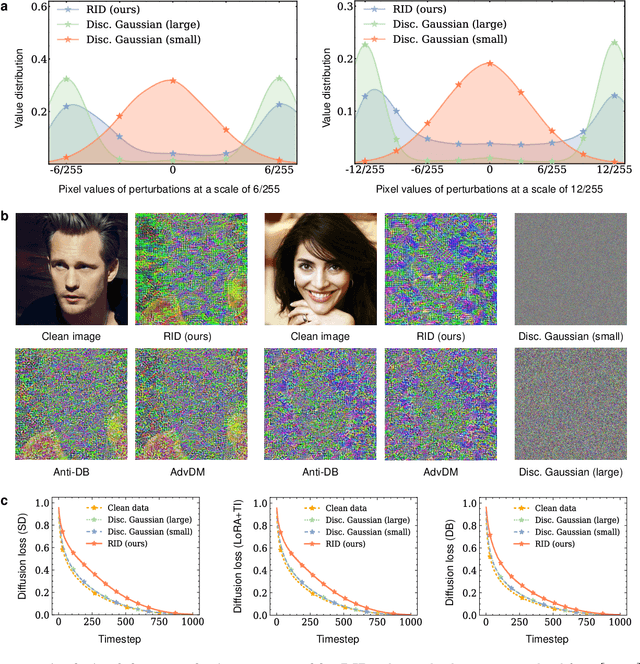
Personalized diffusion models, capable of synthesizing highly realistic images based on a few reference portraits, pose substantial social, ethical, and legal risks by enabling identity replication. Existing defense mechanisms rely on computationally intensive adversarial perturbations tailored to individual images, rendering them impractical for real-world deployment. This study introduces Real-time Identity Defender (RID), a neural network designed to generate adversarial perturbations through a single forward pass, bypassing the need for image-specific optimization. RID achieves unprecedented efficiency, with defense times as low as 0.12 seconds on a single GPU (4,400 times faster than leading methods) and 1.1 seconds per image on a standard Intel i9 CPU, making it suitable for edge devices such as smartphones. Despite its efficiency, RID matches state-of-the-art performance across visual and quantitative benchmarks, effectively mitigating identity replication risks. Our analysis reveals that RID's perturbations mimic the efficacy of traditional defenses while exhibiting properties distinct from natural noise, such as Gaussian perturbations. To enhance robustness, we extend RID into an ensemble framework that integrates multiple pre-trained text-to-image diffusion models, ensuring resilience against black-box attacks and post-processing techniques, including JPEG compression and diffusion-based purification.
MEMO: Memory-Guided Diffusion for Expressive Talking Video Generation
Dec 05, 2024



Recent advances in video diffusion models have unlocked new potential for realistic audio-driven talking video generation. However, achieving seamless audio-lip synchronization, maintaining long-term identity consistency, and producing natural, audio-aligned expressions in generated talking videos remain significant challenges. To address these challenges, we propose Memory-guided EMOtion-aware diffusion (MEMO), an end-to-end audio-driven portrait animation approach to generate identity-consistent and expressive talking videos. Our approach is built around two key modules: (1) a memory-guided temporal module, which enhances long-term identity consistency and motion smoothness by developing memory states to store information from a longer past context to guide temporal modeling via linear attention; and (2) an emotion-aware audio module, which replaces traditional cross attention with multi-modal attention to enhance audio-video interaction, while detecting emotions from audio to refine facial expressions via emotion adaptive layer norm. Extensive quantitative and qualitative results demonstrate that MEMO generates more realistic talking videos across diverse image and audio types, outperforming state-of-the-art methods in overall quality, audio-lip synchronization, identity consistency, and expression-emotion alignment.
Try-On-Adapter: A Simple and Flexible Try-On Paradigm
Nov 15, 2024
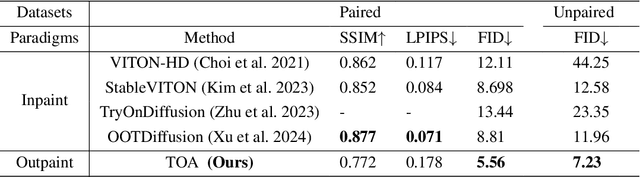
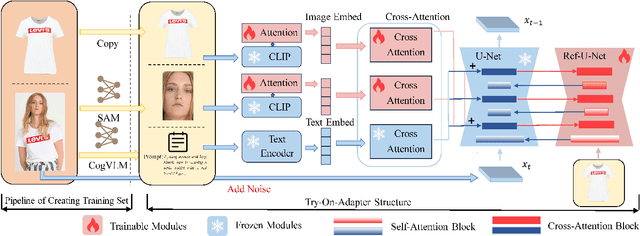

Image-based virtual try-on, widely used in online shopping, aims to generate images of a naturally dressed person conditioned on certain garments, providing significant research and commercial potential. A key challenge of try-on is to generate realistic images of the model wearing the garments while preserving the details of the garments. Previous methods focus on masking certain parts of the original model's standing image, and then inpainting on masked areas to generate realistic images of the model wearing corresponding reference garments, which treat the try-on task as an inpainting task. However, such implements require the user to provide a complete, high-quality standing image, which is user-unfriendly in practical applications. In this paper, we propose Try-On-Adapter (TOA), an outpainting paradigm that differs from the existing inpainting paradigm. Our TOA can preserve the given face and garment, naturally imagine the rest parts of the image, and provide flexible control ability with various conditions, e.g., garment properties and human pose. In the experiments, TOA shows excellent performance on the virtual try-on task even given relatively low-quality face and garment images in qualitative comparisons. Additionally, TOA achieves the state-of-the-art performance of FID scores 5.56 and 7.23 for paired and unpaired on the VITON-HD dataset in quantitative comparisons.
FreqMark: Invisible Image Watermarking via Frequency Based Optimization in Latent Space
Oct 28, 2024Invisible watermarking is essential for safeguarding digital content, enabling copyright protection and content authentication. However, existing watermarking methods fall short in robustness against regeneration attacks. In this paper, we propose a novel method called FreqMark that involves unconstrained optimization of the image latent frequency space obtained after VAE encoding. Specifically, FreqMark embeds the watermark by optimizing the latent frequency space of the images and then extracts the watermark through a pre-trained image encoder. This optimization allows a flexible trade-off between image quality with watermark robustness and effectively resists regeneration attacks. Experimental results demonstrate that FreqMark offers significant advantages in image quality and robustness, permits flexible selection of the encoding bit number, and achieves a bit accuracy exceeding 90% when encoding a 48-bit hidden message under various attack scenarios.