 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Image Distributions Indistinguishable to Humans Indistinguishable to Classifiers?
Paper and Code
May 28, 2024
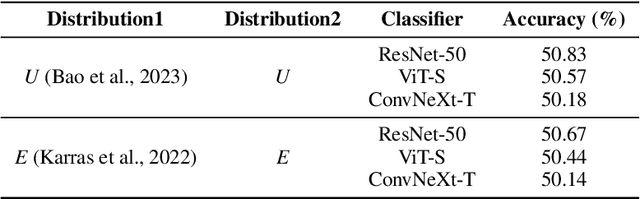
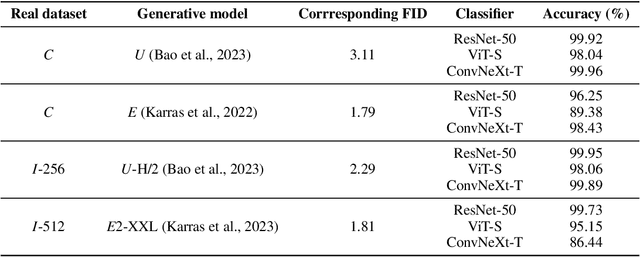
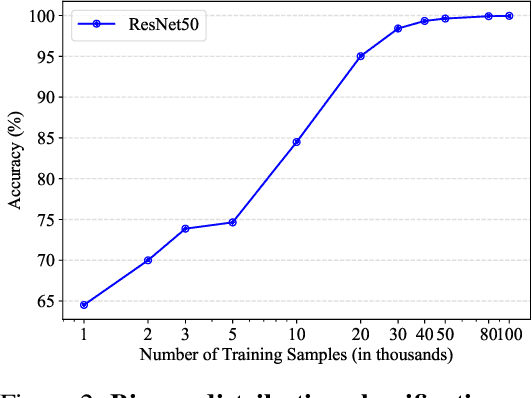
The ultimate goal of generative models is to characterize the data distribution perfectly. For image generation, common metrics of visual quality (e.g., FID), and the truthlikeness of generated images to the human eyes seem to suggest that we are close to achieving it. However, through distribution classification tasks, we find that, in the eyes of classifiers parameterized by neural networks, the strongest diffusion models are still far from this goal. Specifically, classifiers consistently and effortlessly distinguish between real and generated images in various settings. Further, we observe an intriguing discrepancy: classifiers can identify differences between diffusion models with similar performance (e.g., U-ViT-H vs. DiT-XL), but struggle to differentiate between the smallest and largest models in the same family (e.g., EDM2-XS vs. EDM2-XXL), whereas humans exhibit the opposite tendency. As an explanation, our comprehensive empirical study suggests that, unlike humans, classifiers tend to classify images through edge and high-frequency components. We believe that our methodology can serve as a probe to understand how generative models work and inspire further thought on how existing models can be improved and how the abuse of such models can be prevented.