 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaDA-o: An Effective and Length-Adaptive Omni Diffusion Model
Mar 01, 2026We present \textbf{LLaDA-o}, an effective and length-adaptive omni diffusion model for multimodal understanding and generation. LLaDA-o is built on a Mixture of Diffusion (MoD) framework that decouples discrete masked diffusion for text understanding and continuous diffusion for visual generation, while coupling them through a shared, simple, and efficient attention backbone that reduces redundant computation for fixed conditions. Building on MoD, we further introduce a data-centric length adaptation strategy that enables flexible-length decoding in multimodal settings without architectural changes. Extensive experiments show that LLaDA-o achieves state-of-the-art performance among omni-diffusion models on multimodal understanding and generation benchmarks, and reaches 87.04 on DPG-Bench for text-to-image generation, supporting the effectiveness of unified omni diffusion modeling. Code is available at https://github.com/ML-GSAI/LLaDA-o.
LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning
May 22, 2025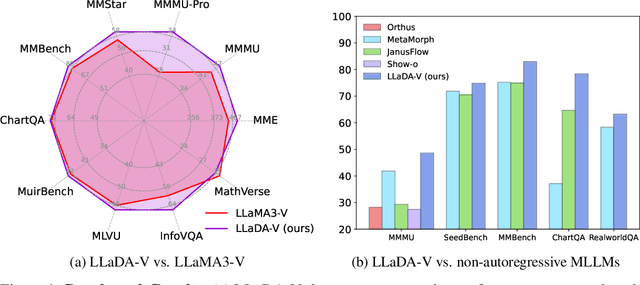
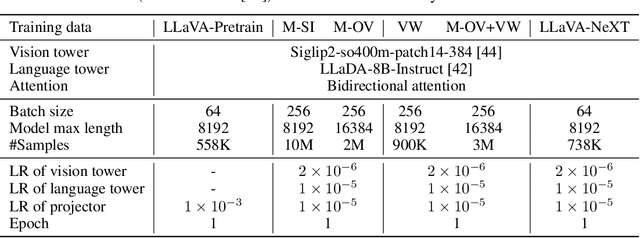
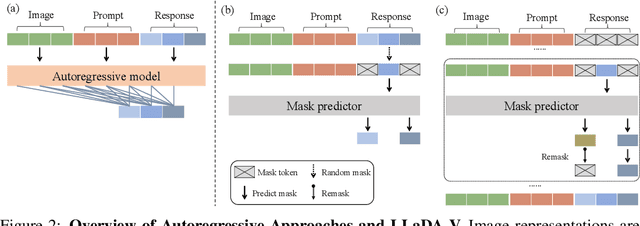
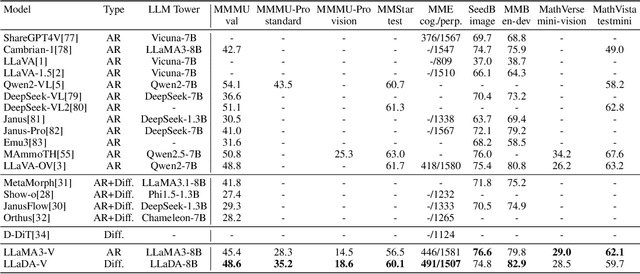
In this work, we introduce LLaDA-V, a purely diffusion-based Multimodal Large Language Model (MLLM) that integrates visual instruction tuning with masked diffusion models, representing a departure from the autoregressive paradigms dominant in current multimodal approaches. Built upon LLaDA, a representative large language diffusion model, LLaDA-V incorporates a vision encoder and MLP connector that projects visual features into the language embedding space, enabling effective multimodal alignment. Our empirical investigation reveals several intriguing results: First, LLaDA-V demonstrates promising multimodal performance despite its language model being weaker on purely textual tasks than counterparts like LLaMA3-8B and Qwen2-7B. When trained on the same instruction data, LLaDA-V is highly competitive to LLaMA3-V across multimodal tasks with better data scalability. It also narrows the performance gap to Qwen2-VL, suggesting the effectiveness of its architecture for multimodal tasks. Second, LLaDA-V achieves state-of-the-art performance in multimodal understanding compared to existing hybrid autoregressive-diffusion and purely diffusion-based MLLMs. Our findings suggest that large language diffusion models show promise in multimodal contexts and warrant further investigation in future research. Project page and codes: https://ml-gsai.github.io/LLaDA-V-demo/.
Effective and Efficient Masked Image Generation Models
Mar 10, 2025Although masked image generation models and masked diffusion models are designed with different motivations and objectives, we observe that they can be unified within a single framework. Building upon this insight, we carefully explore the design space of training and sampling, identifying key factors that contribute to both performance and efficiency. Based on the improvements observed during this exploration, we develop our model, referred to as eMIGM. Empirically, eMIGM demonstrates strong performance on ImageNet generation, as measured by Fr\'echet Inception Distance (FID). In particular, on ImageNet 256x256, with similar number of function evaluations (NFEs) and model parameters, eMIGM outperforms the seminal VAR. Moreover, as NFE and model parameters increase, eMIGM achieves performance comparable to the state-of-the-art continuous diffusion models while requiring less than 40% of the NFE. Additionally, on ImageNet 512x512, with only about 60% of the NFE, eMIGM outperforms the state-of-the-art continuous diffusion models.
Are Image Distributions Indistinguishable to Humans Indistinguishable to Classifiers?
May 28, 2024
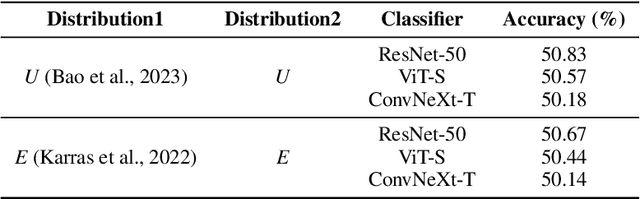
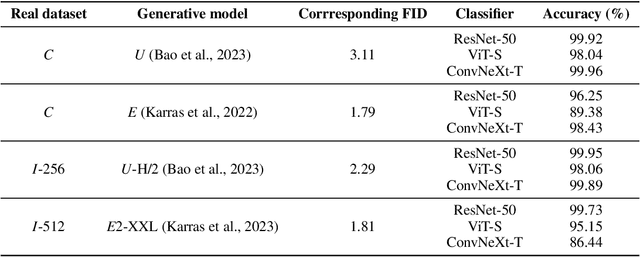
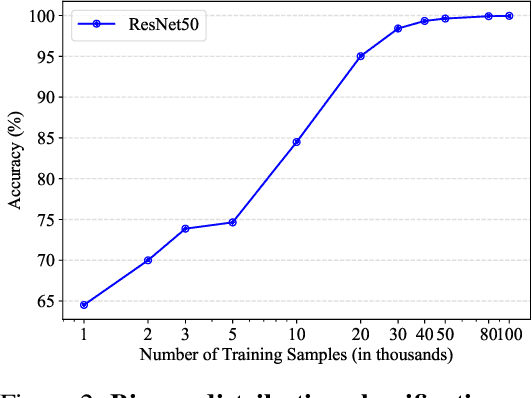
The ultimate goal of generative models is to characterize the data distribution perfectly. For image generation, common metrics of visual quality (e.g., FID), and the truthlikeness of generated images to the human eyes seem to suggest that we are close to achieving it. However, through distribution classification tasks, we find that, in the eyes of classifiers parameterized by neural networks, the strongest diffusion models are still far from this goal. Specifically, classifiers consistently and effortlessly distinguish between real and generated images in various settings. Further, we observe an intriguing discrepancy: classifiers can identify differences between diffusion models with similar performance (e.g., U-ViT-H vs. DiT-XL), but struggle to differentiate between the smallest and largest models in the same family (e.g., EDM2-XS vs. EDM2-XXL), whereas humans exhibit the opposite tendency. As an explanation, our comprehensive empirical study suggests that, unlike humans, classifiers tend to classify images through edge and high-frequency components. We believe that our methodology can serve as a probe to understand how generative models work and inspire further thought on how existing models can be improved and how the abuse of such models can be prevented.
PoseCrafter: One-Shot Personalized Video Synthesis Following Flexible Poses
May 23, 2024



In this paper, we introduce PoseCrafter, a one-shot method for personalized video generation following the control of flexible poses. Built upon Stable Diffusion and ControlNet, we carefully design an inference process to produce high-quality videos without the corresponding ground-truth frames. First, we select an appropriate reference frame from the training video and invert it to initialize all latent variables for generation. Then, we insert the corresponding training pose into the target pose sequences to enhance faithfulness through a trained temporal attention module. Furthermore, to alleviate the face and hand degradation resulting from discrepancies between poses of training videos and inference poses, we implement simple latent editing through an affine transformation matrix involving facial and hand landmarks. Extensive experiments on several datasets demonstrate that PoseCrafter achieves superior results to baselines pre-trained on a vast collection of videos under 8 commonly used metrics. Besides, PoseCrafter can follow poses from different individuals or artificial edits and simultaneously retain the human identity in an open-domain training video.
Diffusion Models and Semi-Supervised Learners Benefit Mutually with Few Labels
Feb 21, 2023
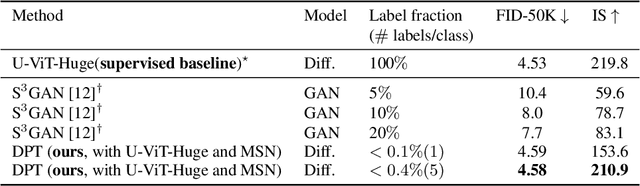
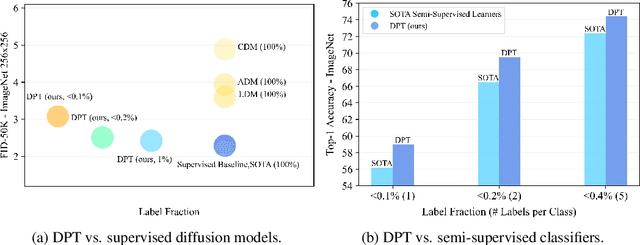
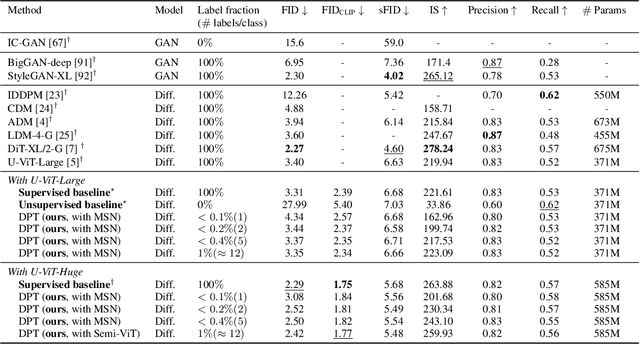
We propose a three-stage training strategy called dual pseudo training (DPT) for conditional image generation and classification in semi-supervised learning. First, a classifier is trained on partially labeled data and predicts pseudo labels for all data. Second, a conditional generative model is trained on all data with pseudo labels and generates pseudo images given labels. Finally, the classifier is trained on real data augmented by pseudo images with labels. We demonstrate large-scale diffusion models and semi-supervised learners benefit mutually with a few labels via DPT. In particular, on the ImageNet 256x256 generation benchmark, DPT can generate realistic, diverse, and semantically correct images with very few labels. With two (i.e., < 0.2%) and five (i.e., < 0.4%) labels per class, DPT achieves an FID of 3.44 and 3.37 respectively, outperforming strong diffusion models with full labels, such as IDDPM, CDM, ADM, and LDM. Besides, DPT outperforms competitive semi-supervised baselines substantially on ImageNet classification benchmarks with one, two, and five labels per class, achieving state-of-the-art top-1 accuracies of 59.0 (+2.8), 69.5 (+3.0), and 73.6 (+1.2) respectively.