 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Reasoning in Large Audio-Language Models for Ambiguous Emotion Prediction
Mar 09, 2026Speech emotion recognition plays an important role in various applications. However, most existing approaches predict a single emotion label, oversimplifying the inherently ambiguous nature of human emotional expression. Recent large audio-language models show promise in generating richer outputs, but their reasoning ability for ambiguous emotional understanding remains limited. In this work, we reformulate ambiguous emotion recognition as a distributional reasoning problem and present the first systematic study of ambiguity-aware reasoning in LALMs. Our framework comprises two complementary components: an ambiguity-aware objective that aligns predictions with human perceptual distributions, and a structured ambiguity-aware chain-of-thought supervision that guides reasoning over emotional cues. Experiments on IEMOCAP and CREMA-D demonstrate consistent improvements across SFT, DPO, and GRPO training strategies.
Decoding Ambiguous Emotions with Test-Time Scaling in Audio-Language Models
Feb 01, 2026Emotion recognition from human speech is a critical enabler for socially aware conversational AI. However, while most prior work frames emotion recognition as a categorical classification problem, real-world affective states are often ambiguous, overlapping, and context-dependent, posing significant challenges for both annotation and automatic modeling. Recent large-scale audio language models (ALMs) offer new opportunities for nuanced affective reasoning without explicit emotion supervision, but their capacity to handle ambiguous emotions remains underexplored. At the same time, advances in inference-time techniques such as test-time scaling (TTS) have shown promise for improving generalization and adaptability in hard NLP tasks, but their relevance to affective computing is still largely unknown. In this work, we introduce the first benchmark for ambiguous emotion recognition in speech with ALMs under test-time scaling. Our evaluation systematically compares eight state-of-the-art ALMs and five TTS strategies across three prominent speech emotion datasets. We further provide an in-depth analysis of the interaction between model capacity, TTS, and affective ambiguity, offering new insights into the computational and representational challenges of ambiguous emotion understanding. Our benchmark establishes a foundation for developing more robust, context-aware, and emotionally intelligent speech-based AI systems, and highlights key future directions for bridging the gap between model assumptions and the complexity of real-world human emotion.
PoseCrafter: One-Shot Personalized Video Synthesis Following Flexible Poses
May 23, 2024



In this paper, we introduce PoseCrafter, a one-shot method for personalized video generation following the control of flexible poses. Built upon Stable Diffusion and ControlNet, we carefully design an inference process to produce high-quality videos without the corresponding ground-truth frames. First, we select an appropriate reference frame from the training video and invert it to initialize all latent variables for generation. Then, we insert the corresponding training pose into the target pose sequences to enhance faithfulness through a trained temporal attention module. Furthermore, to alleviate the face and hand degradation resulting from discrepancies between poses of training videos and inference poses, we implement simple latent editing through an affine transformation matrix involving facial and hand landmarks. Extensive experiments on several datasets demonstrate that PoseCrafter achieves superior results to baselines pre-trained on a vast collection of videos under 8 commonly used metrics. Besides, PoseCrafter can follow poses from different individuals or artificial edits and simultaneously retain the human identity in an open-domain training video.
CEKD:Cross Ensemble Knowledge Distillation for Augmented Fine-grained Data
Mar 13, 2022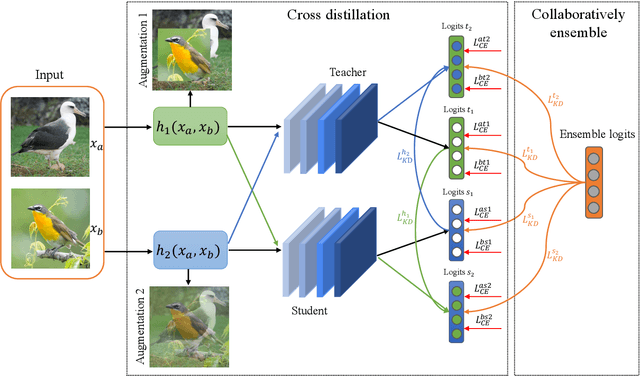
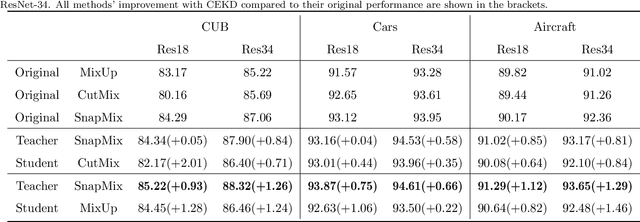
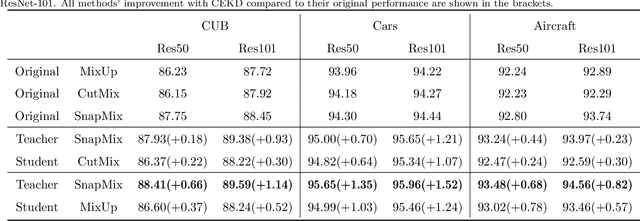

Data augmentation has been proved effective in training deep models. Existing data augmentation methods tackle the fine-grained problem by blending image pairs and fusing corresponding labels according to the statistics of mixed pixels, which produces additional noise harmful to the performance of networks. Motivated by this, we present a simple yet effective cross ensemble knowledge distillation (CEKD) model for fine-grained feature learning. We innovatively propose a cross distillation module to provide additional supervision to alleviate the noise problem, and propose a collaborative ensemble module to overcome the target conflict problem. The proposed model can be trained in an end-to-end manner, and only requires image-level label supervision. Extensive experiments on widely used fine-grained benchmarks demonstrate the effectiveness of our proposed model. Specifically, with the backbone of ResNet-101, CEKD obtains the accuracy of 89.59%, 95.96% and 94.56% in three datasets respectively, outperforming state-of-the-art API-Net by 0.99%, 1.06% and 1.16%.